 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Sample Complexity Bounds for Distributionally Robust Reinforcement Learning
Paper and Code
Mar 05, 2023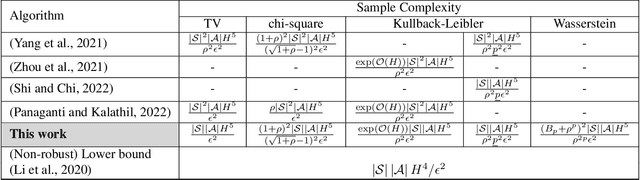
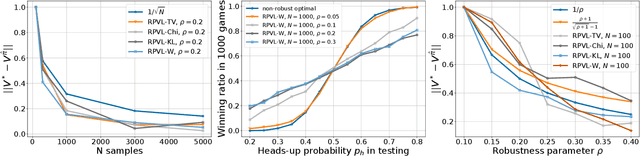
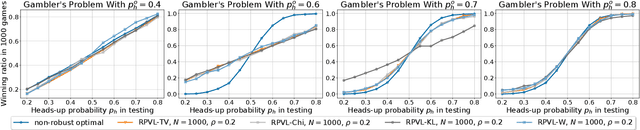
We consider the problem of learning a control policy that is robust against the parameter mismatches between the training environment and testing environment. We formulate this as a distributionally robust reinforcement learning (DR-RL) problem where the objective is to learn the policy which maximizes the value function against the worst possible stochastic model of the environment in an uncertainty set. We focus on the tabular episodic learning setting where the algorithm has access to a generative model of the nominal (training) environment around which the uncertainty set is defined. We propose the Robust Phased Value Learning (RPVL) algorithm to solve this problem for the uncertainty sets specified by four different divergences: total variation, chi-square, Kullback-Leibler, and Wasserstein. We show that our algorithm achieves $\tilde{\mathcal{O}}(|\mathcal{S}||\mathcal{A}| H^{5})$ sample complexity, which is uniformly better than the existing results by a factor of $|\mathcal{S}|$, where $|\mathcal{S}|$ is number of states, $|\mathcal{A}|$ is the number of actions, and $H$ is the horizon length. We also provide the first-ever sample complexity result for the Wasserstein uncertainty set. Finally, we demonstrate the performance of our algorithm using simulation experiments.