 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTBA: Faster Large Language Model Training Using SSD-Based Activation Offloading
Aug 19, 2024



The growth rate of the GPU memory capacity has not been able to keep up with that of the size of large language models (LLMs), hindering the model training process. In particular, activations -- the intermediate tensors produced during forward propagation and reused in backward propagation -- dominate the GPU memory use. To address this challenge, we propose TBA to efficiently offload activations to high-capacity NVMe SSDs. This approach reduces GPU memory usage without impacting performance by adaptively overlapping data transfers with computation. TBA is compatible with popular deep learning frameworks like PyTorch, Megatron, and DeepSpeed, and it employs techniques such as tensor deduplication, forwarding, and adaptive offloading to further enhance efficiency. We conduct extensive experiments on GPT, BERT, and T5. Results demonstrate that TBA effectively reduces 47% of the activation peak memory usage. At the same time, TBA perfectly overlaps the I/O with the computation and incurs negligible performance overhead. We introduce the recompute-offload-keep (ROK) curve to compare the TBA offloading with other two tensor placement strategies, keeping activations in memory and layerwise full recomputation. We find that TBA achieves better memory savings than layerwise full recomputation while retaining the performance of keeping the activations in memory.
LSM-GNN: Large-scale Storage-based Multi-GPU GNN Training by Optimizing Data Transfer Scheme
Jul 21, 2024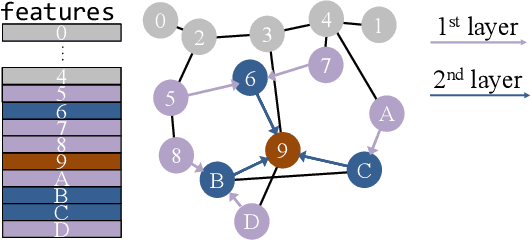

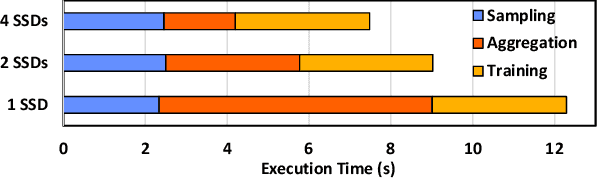
Graph Neural Networks (GNNs) are widely used today in recommendation systems, fraud detection, and node/link classification tasks. Real world GNNs continue to scale in size and require a large memory footprint for storing graphs and embeddings that often exceed the memory capacities of the target GPUs used for training. To address limited memory capacities, traditional GNN training approaches use graph partitioning and sharding techniques to scale up across multiple GPUs within a node and/or scale out across multiple nodes. However, this approach suffers from the high computational costs of graph partitioning algorithms and inefficient communication across GPUs. To address these overheads, we propose Large-scale Storage-based Multi-GPU GNN framework (LSM-GNN), a storagebased approach to train GNN models that utilizes a novel communication layer enabling GPU software caches to function as a system-wide shared cache with low overheads.LSM-GNN incorporates a hybrid eviction policy that intelligently manages cache space by using both static and dynamic node information to significantly enhance cache performance. Furthermore, we introduce the Preemptive Victim-buffer Prefetcher (PVP), a mechanism for prefetching node feature data from a Victim Buffer located in CPU pinned-memory to further reduce the pressure on the storage devices. Experimental results show that despite the lower compute capabilities and memory capacities, LSM-GNN in a single node with two GPUs offers superior performance over two-node-four-GPU Dist-DGL baseline and provides up to 3.75x speed up on end-to-end epoch time while running large-scale GNN training
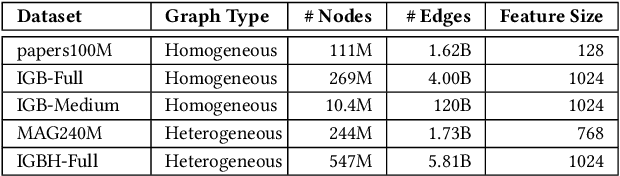
Accelerating Sampling and Aggregation Operations in GNN Frameworks with GPU Initiated Direct Storage Accesses
Jun 28, 2023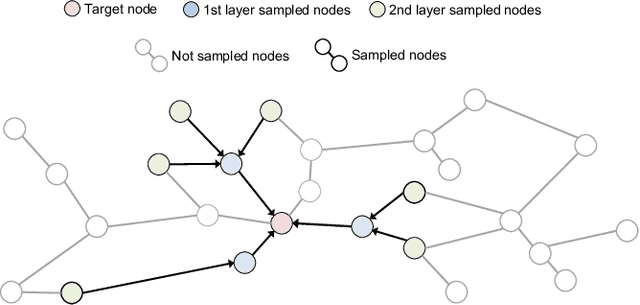

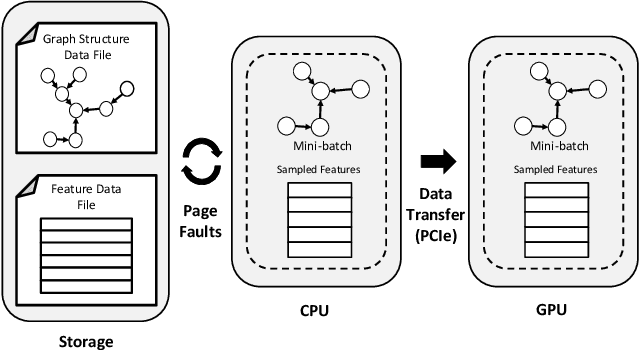
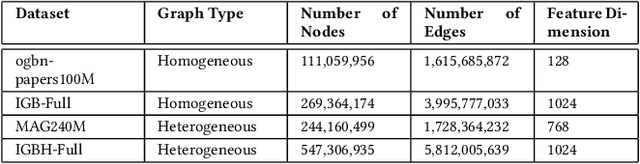
Graph Neural Networks (GNNs) are emerging as a powerful tool for learning from graph-structured data and performing sophisticated inference tasks in various application domains. Although GNNs have been shown to be effective on modest-sized graphs, training them on large-scale graphs remains a significant challenge due to lack of efficient data access and data movement methods. Existing frameworks for training GNNs use CPUs for graph sampling and feature aggregation, while the training and updating of model weights are executed on GPUs. However, our in-depth profiling shows the CPUs cannot achieve the throughput required to saturate GNN model training throughput, causing gross under-utilization of expensive GPU resources. Furthermore, when the graph and its embeddings do not fit in the CPU memory, the overhead introduced by the operating system, say for handling page-faults, comes in the critical path of execution. To address these issues, we propose the GPU Initiated Direct Storage Access (GIDS) dataloader, to enable GPU-oriented GNN training for large-scale graphs while efficiently utilizing all hardware resources, such as CPU memory, storage, and GPU memory with a hybrid data placement strategy. By enabling GPU threads to fetch feature vectors directly from storage, GIDS dataloader solves the memory capacity problem for GPU-oriented GNN training. Moreover, GIDS dataloader leverages GPU parallelism to tolerate storage latency and eliminates expensive page-fault overhead. Doing so enables us to design novel optimizations for exploiting locality and increasing effective bandwidth for GNN training. Our evaluation using a single GPU on terabyte-scale GNN datasets shows that GIDS dataloader accelerates the overall DGL GNN training pipeline by up to 392X when compared to the current, state-of-the-art DGL dataloader.