 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Sampling and Aggregation Operations in GNN Frameworks with GPU Initiated Direct Storage Accesses
Paper and Code
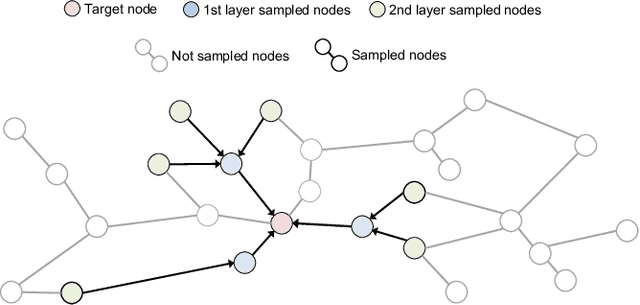

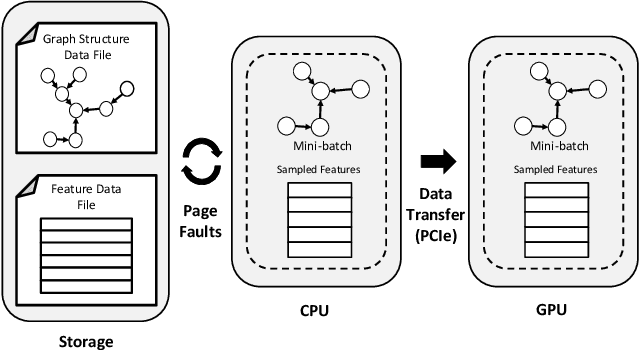
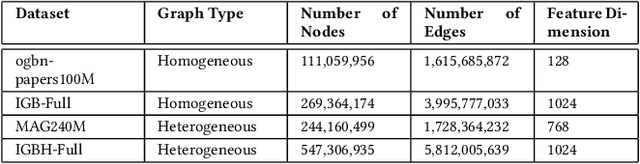
Graph Neural Networks (GNNs) are emerging as a powerful tool for learning from graph-structured data and performing sophisticated inference tasks in various application domains. Although GNNs have been shown to be effective on modest-sized graphs, training them on large-scale graphs remains a significant challenge due to lack of efficient data access and data movement methods. Existing frameworks for training GNNs use CPUs for graph sampling and feature aggregation, while the training and updating of model weights are executed on GPUs. However, our in-depth profiling shows the CPUs cannot achieve the throughput required to saturate GNN model training throughput, causing gross under-utilization of expensive GPU resources. Furthermore, when the graph and its embeddings do not fit in the CPU memory, the overhead introduced by the operating system, say for handling page-faults, comes in the critical path of execution. To address these issues, we propose the GPU Initiated Direct Storage Access (GIDS) dataloader, to enable GPU-oriented GNN training for large-scale graphs while efficiently utilizing all hardware resources, such as CPU memory, storage, and GPU memory with a hybrid data placement strategy. By enabling GPU threads to fetch feature vectors directly from storage, GIDS dataloader solves the memory capacity problem for GPU-oriented GNN training. Moreover, GIDS dataloader leverages GPU parallelism to tolerate storage latency and eliminates expensive page-fault overhead. Doing so enables us to design novel optimizations for exploiting locality and increasing effective bandwidth for GNN training. Our evaluation using a single GPU on terabyte-scale GNN datasets shows that GIDS dataloader accelerates the overall DGL GNN training pipeline by up to 392X when compared to the current, state-of-the-art DGL dataloader.