 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
IRB: Automated Generation of Robust Factuality Benchmarks
Feb 08, 2026Static benchmarks for RAG systems often suffer from rapid saturation and require significant manual effort to maintain robustness. To address this, we present IRB, a framework for automatically generating benchmarks to evaluate the factuality of RAG systems. IRB employs a structured generation pipeline utilizing \textit{factual scaffold} and \textit{algorithmic scaffold}. We utilize IRB to construct a benchmark and evaluate frontier LLMs and retrievers. Our results demonstrate that IRB poses a significant challenge for frontier LLMs in the closed-book setting. Furthermore, our evaluation suggests that reasoning LLMs are more reliable, and that improving the retrieval component may yield more cost-effective gains in RAG system correctness than scaling the generator.
TBA: Faster Large Language Model Training Using SSD-Based Activation Offloading
Aug 19, 2024



The growth rate of the GPU memory capacity has not been able to keep up with that of the size of large language models (LLMs), hindering the model training process. In particular, activations -- the intermediate tensors produced during forward propagation and reused in backward propagation -- dominate the GPU memory use. To address this challenge, we propose TBA to efficiently offload activations to high-capacity NVMe SSDs. This approach reduces GPU memory usage without impacting performance by adaptively overlapping data transfers with computation. TBA is compatible with popular deep learning frameworks like PyTorch, Megatron, and DeepSpeed, and it employs techniques such as tensor deduplication, forwarding, and adaptive offloading to further enhance efficiency. We conduct extensive experiments on GPT, BERT, and T5. Results demonstrate that TBA effectively reduces 47% of the activation peak memory usage. At the same time, TBA perfectly overlaps the I/O with the computation and incurs negligible performance overhead. We introduce the recompute-offload-keep (ROK) curve to compare the TBA offloading with other two tensor placement strategies, keeping activations in memory and layerwise full recomputation. We find that TBA achieves better memory savings than layerwise full recomputation while retaining the performance of keeping the activations in memory.
LSM-GNN: Large-scale Storage-based Multi-GPU GNN Training by Optimizing Data Transfer Scheme
Jul 21, 2024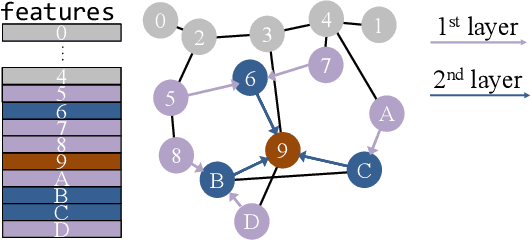

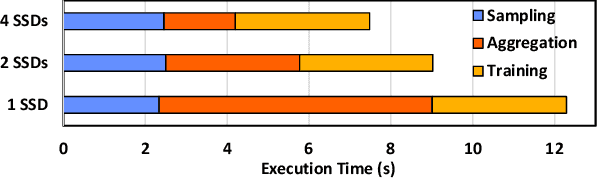
Graph Neural Networks (GNNs) are widely used today in recommendation systems, fraud detection, and node/link classification tasks. Real world GNNs continue to scale in size and require a large memory footprint for storing graphs and embeddings that often exceed the memory capacities of the target GPUs used for training. To address limited memory capacities, traditional GNN training approaches use graph partitioning and sharding techniques to scale up across multiple GPUs within a node and/or scale out across multiple nodes. However, this approach suffers from the high computational costs of graph partitioning algorithms and inefficient communication across GPUs. To address these overheads, we propose Large-scale Storage-based Multi-GPU GNN framework (LSM-GNN), a storagebased approach to train GNN models that utilizes a novel communication layer enabling GPU software caches to function as a system-wide shared cache with low overheads.LSM-GNN incorporates a hybrid eviction policy that intelligently manages cache space by using both static and dynamic node information to significantly enhance cache performance. Furthermore, we introduce the Preemptive Victim-buffer Prefetcher (PVP), a mechanism for prefetching node feature data from a Victim Buffer located in CPU pinned-memory to further reduce the pressure on the storage devices. Experimental results show that despite the lower compute capabilities and memory capacities, LSM-GNN in a single node with two GPUs offers superior performance over two-node-four-GPU Dist-DGL baseline and provides up to 3.75x speed up on end-to-end epoch time while running large-scale GNN training
Accelerating Sampling and Aggregation Operations in GNN Frameworks with GPU Initiated Direct Storage Accesses
Jun 28, 2023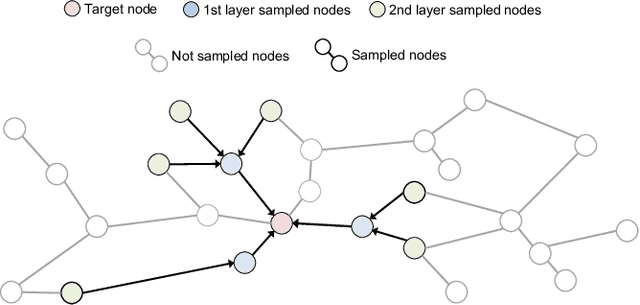

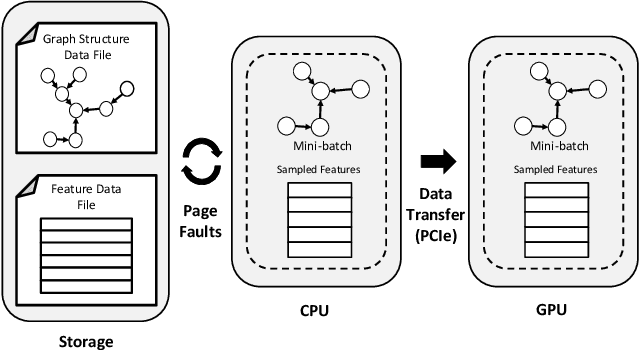
Graph Neural Networks (GNNs) are emerging as a powerful tool for learning from graph-structured data and performing sophisticated inference tasks in various application domains. Although GNNs have been shown to be effective on modest-sized graphs, training them on large-scale graphs remains a significant challenge due to lack of efficient data access and data movement methods. Existing frameworks for training GNNs use CPUs for graph sampling and feature aggregation, while the training and updating of model weights are executed on GPUs. However, our in-depth profiling shows the CPUs cannot achieve the throughput required to saturate GNN model training throughput, causing gross under-utilization of expensive GPU resources. Furthermore, when the graph and its embeddings do not fit in the CPU memory, the overhead introduced by the operating system, say for handling page-faults, comes in the critical path of execution. To address these issues, we propose the GPU Initiated Direct Storage Access (GIDS) dataloader, to enable GPU-oriented GNN training for large-scale graphs while efficiently utilizing all hardware resources, such as CPU memory, storage, and GPU memory with a hybrid data placement strategy. By enabling GPU threads to fetch feature vectors directly from storage, GIDS dataloader solves the memory capacity problem for GPU-oriented GNN training. Moreover, GIDS dataloader leverages GPU parallelism to tolerate storage latency and eliminates expensive page-fault overhead. Doing so enables us to design novel optimizations for exploiting locality and increasing effective bandwidth for GNN training. Our evaluation using a single GPU on terabyte-scale GNN datasets shows that GIDS dataloader accelerates the overall DGL GNN training pipeline by up to 392X when compared to the current, state-of-the-art DGL dataloader.
IGB: Addressing The Gaps In Labeling, Features, Heterogeneity, and Size of Public Graph Datasets for Deep Learning Research
Feb 27, 2023
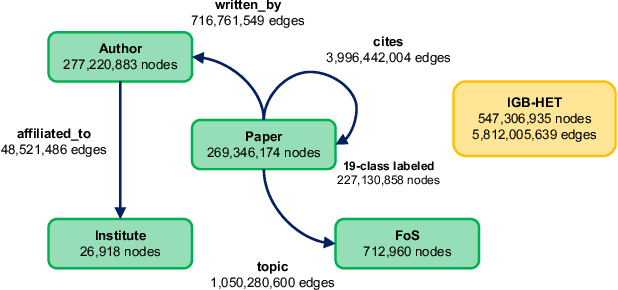

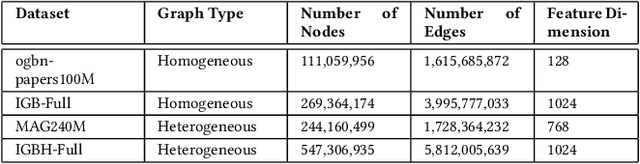
Graph neural networks (GNNs) have shown high potential for a variety of real-world, challenging applications, but one of the major obstacles in GNN research is the lack of large-scale flexible datasets. Most existing public datasets for GNNs are relatively small, which limits the ability of GNNs to generalize to unseen data. The few existing large-scale graph datasets provide very limited labeled data. This makes it difficult to determine if the GNN model's low accuracy for unseen data is inherently due to insufficient training data or if the model failed to generalize. Additionally, datasets used to train GNNs need to offer flexibility to enable a thorough study of the impact of various factors while training GNN models. In this work, we introduce the Illinois Graph Benchmark (IGB), a research dataset tool that the developers can use to train, scrutinize and systematically evaluate GNN models with high fidelity. IGB includes both homogeneous and heterogeneous graphs of enormous sizes, with more than 40% of their nodes labeled. Compared to the largest graph datasets publicly available, the IGB provides over 162X more labeled data for deep learning practitioners and developers to create and evaluate models with higher accuracy. The IGB dataset is designed to be flexible, enabling the study of various GNN architectures, embedding generation techniques, and analyzing system performance issues. IGB is open-sourced, supports DGL and PyG frameworks, and comes with releases of the raw text that we believe foster emerging language models and GNN research projects. An early public version of IGB is available at https://github.com/IllinoisGraphBenchmark/IGB-Datasets.
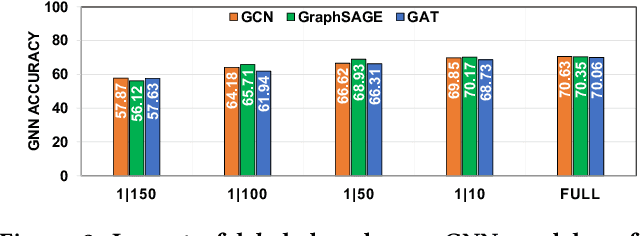
At-Scale Sparse Deep Neural Network Inference with Efficient GPU Implementation
Sep 02, 2020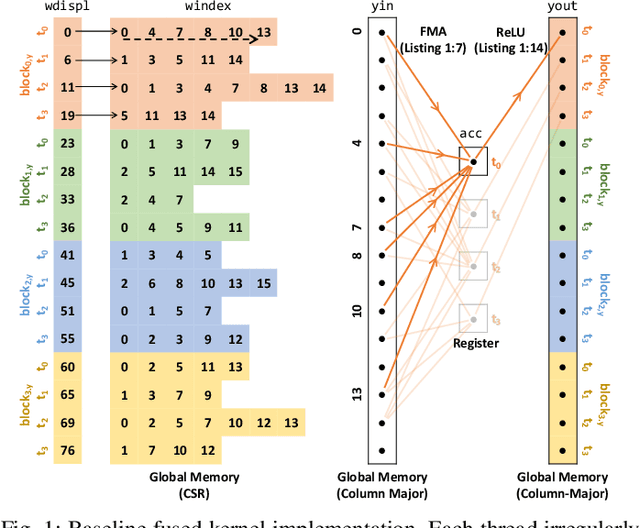
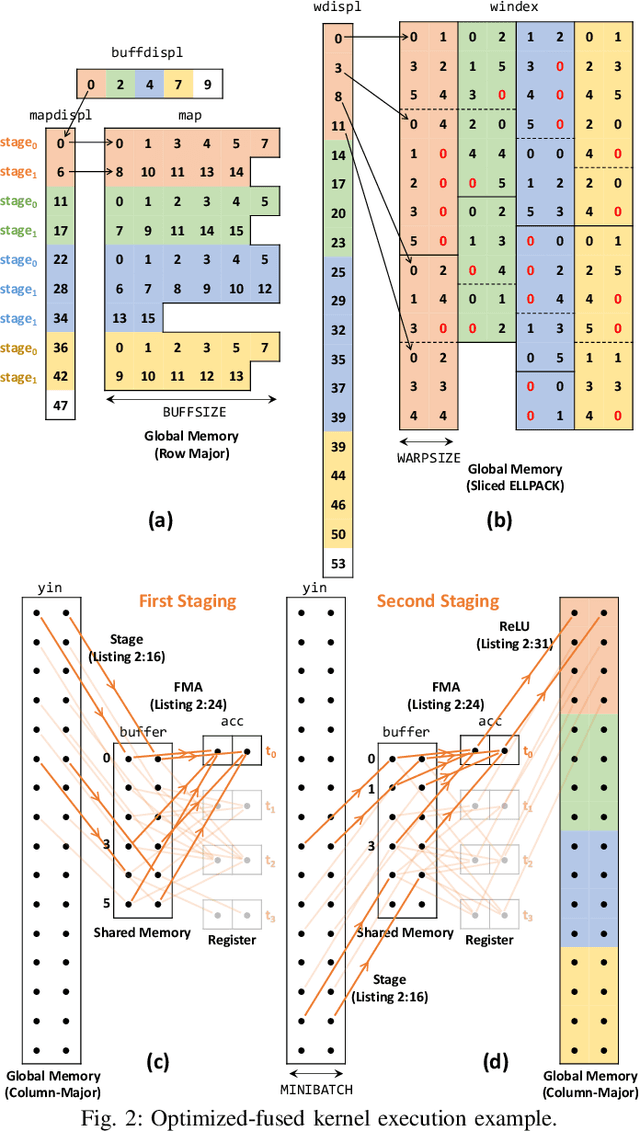
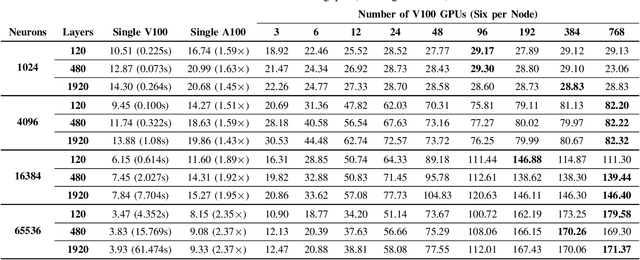
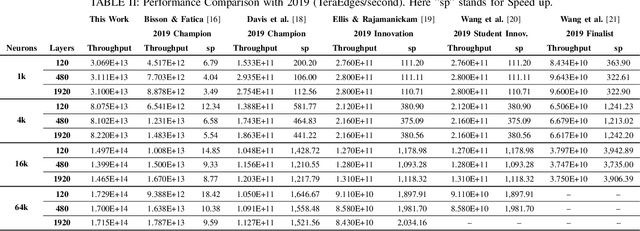
This paper presents GPU performance optimization and scaling results for inference models of the Sparse Deep Neural Network Challenge 2020. Demands for network quality have increased rapidly, pushing the size and thus the memory requirements of many neural networks beyond the capacity of available accelerators. Sparse deep neural networks (SpDNN) have shown promise for reining in the memory footprint of large neural networks. However, there is room for improvement in implementing SpDNN operations on GPUs. This work presents optimized sparse matrix multiplication kernels fused with the ReLU function. The optimized kernels reuse input feature maps from the shared memory and sparse weights from registers. For multi-GPU parallelism, our SpDNN implementation duplicates weights and statically partition the feature maps across GPUs. Results for the challenge benchmarks show that the proposed kernel design and multi-GPU parallelization achieve up to 180 tera-edges per second inference throughput. These results are up to 4.3x faster for a single GPU and an order of magnitude faster at full scale than those of the champion of the 2019 Sparse Deep Neural Network Graph Challenge for the same generation of NVIDIA V100 GPUs. Using the same implementation, we also show single-GPU throughput on NVIDIA A100 is 2.37$\times$ faster than V100.
* 7 pages
I-BERT: Inductive Generalization of Transformer to Arbitrary Context Lengths
Jun 19, 2020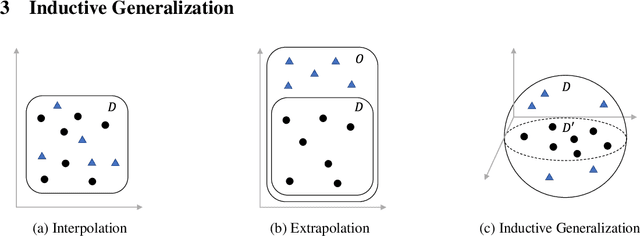
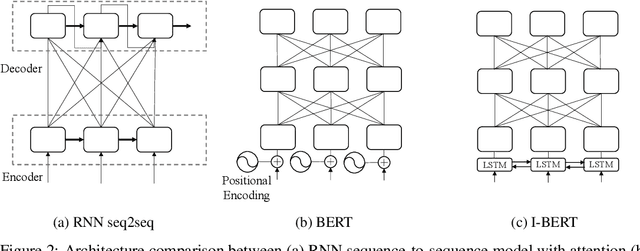
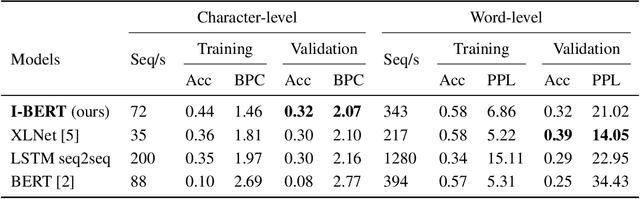
Self-attention has emerged as a vital component of state-of-the-art sequence-to-sequence models for natural language processing in recent years, brought to the forefront by pre-trained bi-directional Transformer models. Its effectiveness is partly due to its non-sequential architecture, which promotes scalability and parallelism but limits the model to inputs of a bounded length. In particular, such architectures perform poorly on algorithmic tasks, where the model must learn a procedure which generalizes to input lengths unseen in training, a capability we refer to as inductive generalization. Identifying the computational limits of existing self-attention mechanisms, we propose I-BERT, a bi-directional Transformer that replaces positional encodings with a recurrent layer. The model inductively generalizes on a variety of algorithmic tasks where state-of-the-art Transformer models fail to do so. We also test our method on masked language modeling tasks where training and validation sets are partitioned to verify inductive generalization. Out of three algorithmic and two natural language inductive generalization tasks, I-BERT achieves state-of-the-art results on four tasks.