 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-BERT: Inductive Generalization of Transformer to Arbitrary Context Lengths
Jun 19, 2020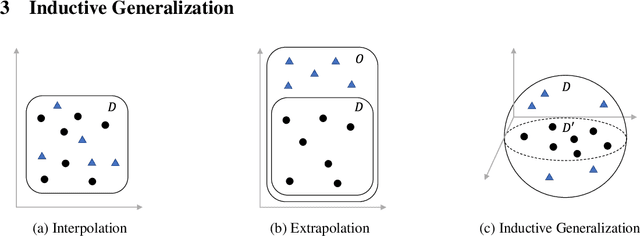
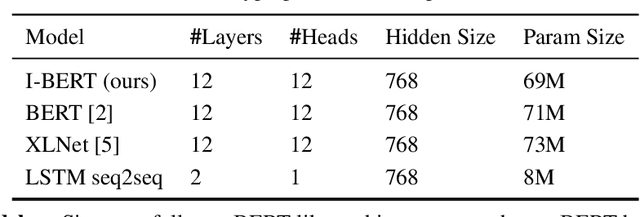
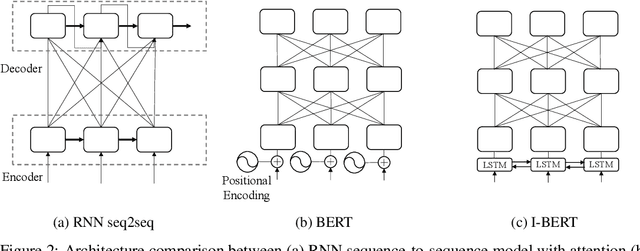
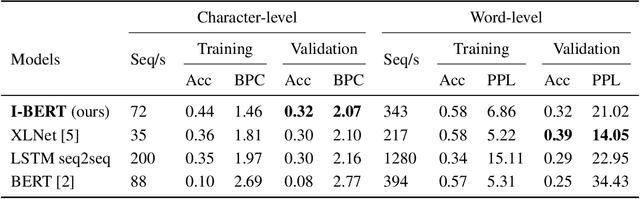
Self-attention has emerged as a vital component of state-of-the-art sequence-to-sequence models for natural language processing in recent years, brought to the forefront by pre-trained bi-directional Transformer models. Its effectiveness is partly due to its non-sequential architecture, which promotes scalability and parallelism but limits the model to inputs of a bounded length. In particular, such architectures perform poorly on algorithmic tasks, where the model must learn a procedure which generalizes to input lengths unseen in training, a capability we refer to as inductive generalization. Identifying the computational limits of existing self-attention mechanisms, we propose I-BERT, a bi-directional Transformer that replaces positional encodings with a recurrent layer. The model inductively generalizes on a variety of algorithmic tasks where state-of-the-art Transformer models fail to do so. We also test our method on masked language modeling tasks where training and validation sets are partitioned to verify inductive generalization. Out of three algorithmic and two natural language inductive generalization tasks, I-BERT achieves state-of-the-art results on four tasks.