 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperBench: Why Coding Agents Cannot be Your Teammates Yet
Jan 19, 2026Resolving team conflicts requires not only task-specific competence, but also social intelligence to find common ground and build consensus. As AI agents increasingly collaborate on complex work, they must develop coordination capabilities to function as effective teammates. Yet we hypothesize that current agents lack these capabilities. To test this, we introduce CooperBench, a benchmark of over 600 collaborative coding tasks across 12 libraries in 4 programming languages. Each task assigns two agents different features that can be implemented independently but may conflict without proper coordination. Tasks are grounded in real open-source repositories with expert-written tests. Evaluating state-of-the-art coding agents, we observe the curse of coordination: agents achieve on average 30% lower success rates when working together compared to performing both tasks individually. This contrasts sharply with human teams, where adding teammates typically improves productivity. Our analysis reveals three key issues: (1) communication channels become jammed with vague, ill-timed, and inaccurate messages; (2) even with effective communication, agents deviate from their commitments; and (3) agents often hold incorrect expectations about others' plans and communication. Through large-scale simulation, we also observe rare but interesting emergent coordination behavior including role division, resource division, and negotiation. Our research presents a novel benchmark for collaborative coding and calls for a shift from pursuing individual agent capability to developing social intelligence.
VideoWeave: A Data-Centric Approach for Efficient Video Understanding
Jan 09, 2026Training video-language models is often prohibitively expensive due to the high cost of processing long frame sequences and the limited availability of annotated long videos. We present VideoWeave, a simple yet effective approach to improve data efficiency by constructing synthetic long-context training samples that splice together short, captioned videos from existing datasets. Rather than modifying model architectures or optimization objectives, VideoWeave reorganizes available video-text pairs to expand temporal diversity within fixed compute. We systematically study how different data composition strategies like random versus visually clustered splicing and caption enrichment affect downstream performance on downstream video question answering. Under identical compute constraints, models trained with VideoWeave achieve higher accuracy than conventional video finetuning. Our results highlight that reorganizing training data, rather than altering architectures, may offer a simple and scalable path for training video-language models. We link our code for all experiments here.
VideoMultiAgents: A Multi-Agent Framework for Video Question Answering
Apr 30, 2025Video Question Answering (VQA) inherently relies on multimodal reasoning, integrating visual, temporal, and linguistic cues to achieve a deeper understanding of video content. However, many existing methods rely on feeding frame-level captions into a single model, making it difficult to adequately capture temporal and interactive contexts. To address this limitation, we introduce VideoMultiAgents, a framework that integrates specialized agents for vision, scene graph analysis, and text processing. It enhances video understanding leveraging complementary multimodal reasoning from independently operating agents. Our approach is also supplemented with a question-guided caption generation, which produces captions that highlight objects, actions, and temporal transitions directly relevant to a given query, thus improving the answer accuracy. Experimental results demonstrate that our method achieves state-of-the-art performance on Intent-QA (79.0%, +6.2% over previous SOTA), EgoSchema subset (75.4%, +3.4%), and NExT-QA (79.6%, +0.4%). The source code is available at https://github.com/PanasonicConnect/VideoMultiAgents.
IGB: Addressing The Gaps In Labeling, Features, Heterogeneity, and Size of Public Graph Datasets for Deep Learning Research
Feb 27, 2023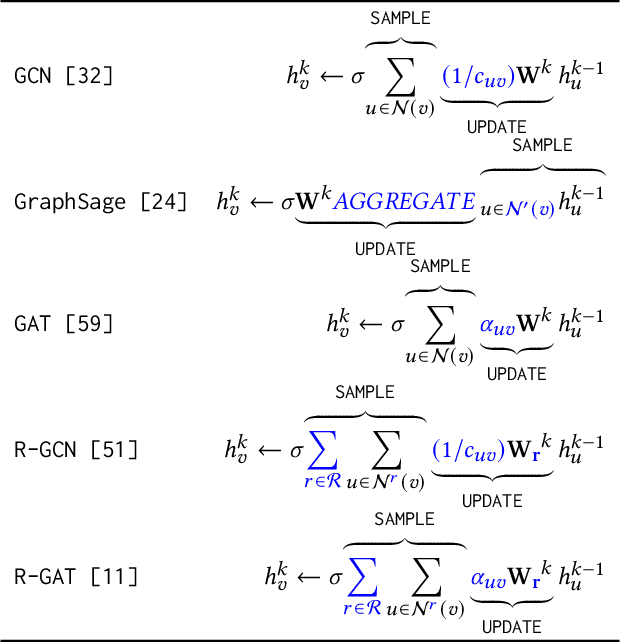
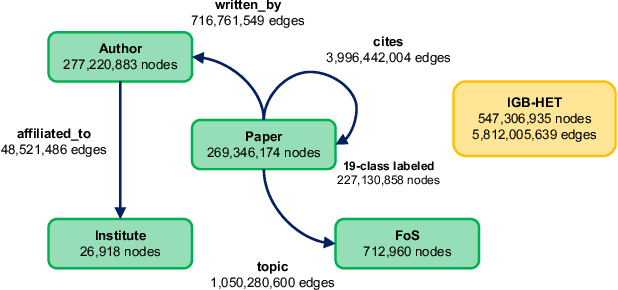

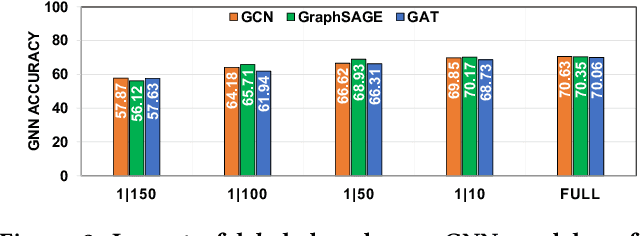
Graph neural networks (GNNs) have shown high potential for a variety of real-world, challenging applications, but one of the major obstacles in GNN research is the lack of large-scale flexible datasets. Most existing public datasets for GNNs are relatively small, which limits the ability of GNNs to generalize to unseen data. The few existing large-scale graph datasets provide very limited labeled data. This makes it difficult to determine if the GNN model's low accuracy for unseen data is inherently due to insufficient training data or if the model failed to generalize. Additionally, datasets used to train GNNs need to offer flexibility to enable a thorough study of the impact of various factors while training GNN models. In this work, we introduce the Illinois Graph Benchmark (IGB), a research dataset tool that the developers can use to train, scrutinize and systematically evaluate GNN models with high fidelity. IGB includes both homogeneous and heterogeneous graphs of enormous sizes, with more than 40% of their nodes labeled. Compared to the largest graph datasets publicly available, the IGB provides over 162X more labeled data for deep learning practitioners and developers to create and evaluate models with higher accuracy. The IGB dataset is designed to be flexible, enabling the study of various GNN architectures, embedding generation techniques, and analyzing system performance issues. IGB is open-sourced, supports DGL and PyG frameworks, and comes with releases of the raw text that we believe foster emerging language models and GNN research projects. An early public version of IGB is available at https://github.com/IllinoisGraphBenchmark/IGB-Datasets.