 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Automated Knowledge Engineering and Process Mapping for Total Airport Management
Mar 27, 2026Documentation of airport operations is inherently complex due to extensive technical terminology, rigorous regulations, proprietary regional information, and fragmented communication across multiple stakeholders. The resulting data silos and semantic inconsistencies present a significant impediment to the Total Airport Management (TAM) initiative. This paper presents a methodological framework for constructing a domain-grounded, machine-readable Knowledge Graph (KG) through a dual-stage fusion of symbolic Knowledge Engineering (KE) and generative Large Language Models (LLMs). The framework employs a scaffolded fusion strategy in which expert-curated KE structures guide LLM prompts to facilitate the discovery of semantically aligned knowledge triples. We evaluate this methodology on the Google LangExtract library and investigate the impact of context window utilization by comparing localized segment-based inference with document-level processing. Contrary to prior empirical observations of long-context degradation in LLMs, document-level processing improves the recovery of non-linear procedural dependencies. To ensure the high-fidelity provenance required in airport operations, the proposed framework fuses a probabilistic model for discovery and a deterministic algorithm for anchoring every extraction to its ground source. This ensures absolute traceability and verifiability, bridging the gap between "black-box" generative outputs and the transparency required for operational tooling. Finally, we introduce an automated framework that operationalizes this pipeline to synthesize complex operational workflows from unstructured textual corpora.
At-Scale Sparse Deep Neural Network Inference with Efficient GPU Implementation
Sep 02, 2020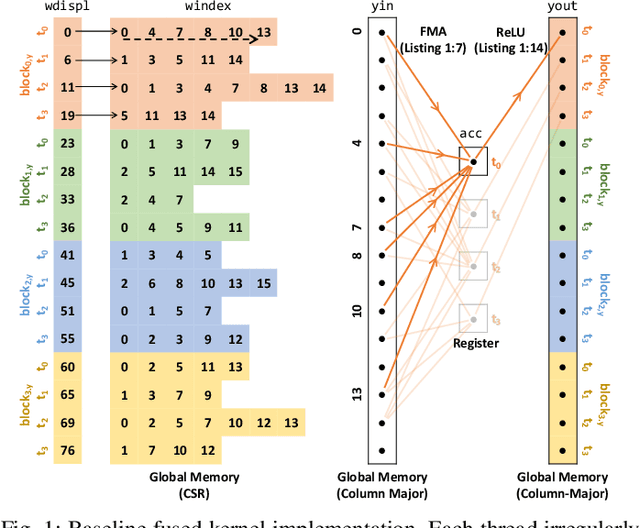
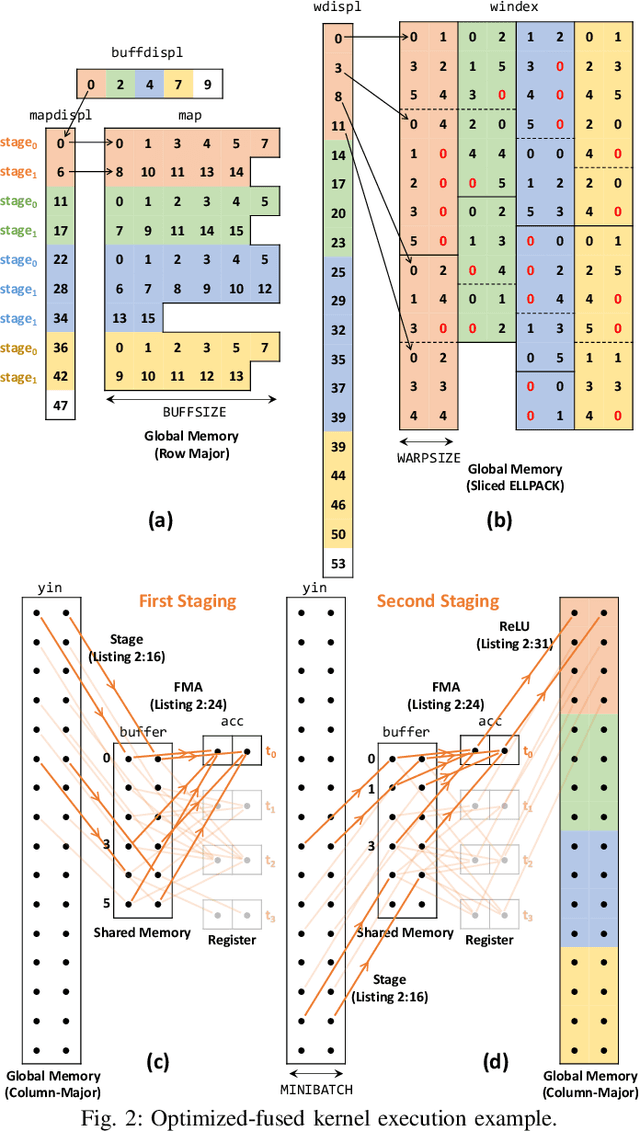
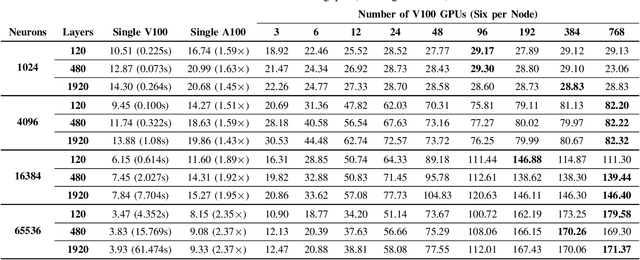
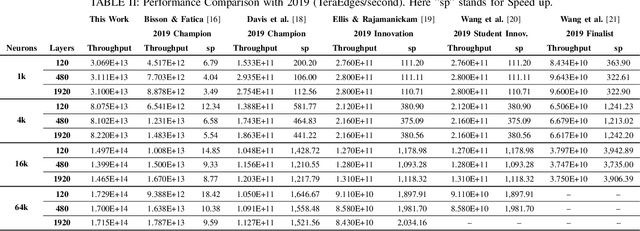
This paper presents GPU performance optimization and scaling results for inference models of the Sparse Deep Neural Network Challenge 2020. Demands for network quality have increased rapidly, pushing the size and thus the memory requirements of many neural networks beyond the capacity of available accelerators. Sparse deep neural networks (SpDNN) have shown promise for reining in the memory footprint of large neural networks. However, there is room for improvement in implementing SpDNN operations on GPUs. This work presents optimized sparse matrix multiplication kernels fused with the ReLU function. The optimized kernels reuse input feature maps from the shared memory and sparse weights from registers. For multi-GPU parallelism, our SpDNN implementation duplicates weights and statically partition the feature maps across GPUs. Results for the challenge benchmarks show that the proposed kernel design and multi-GPU parallelization achieve up to 180 tera-edges per second inference throughput. These results are up to 4.3x faster for a single GPU and an order of magnitude faster at full scale than those of the champion of the 2019 Sparse Deep Neural Network Graph Challenge for the same generation of NVIDIA V100 GPUs. Using the same implementation, we also show single-GPU throughput on NVIDIA A100 is 2.37$\times$ faster than V100.
* 7 pages
Risk-Averse Explore-Then-Commit Algorithms for Finite-Time Bandits
May 08, 2019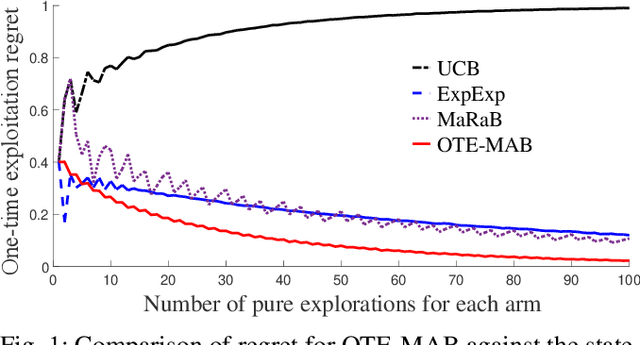
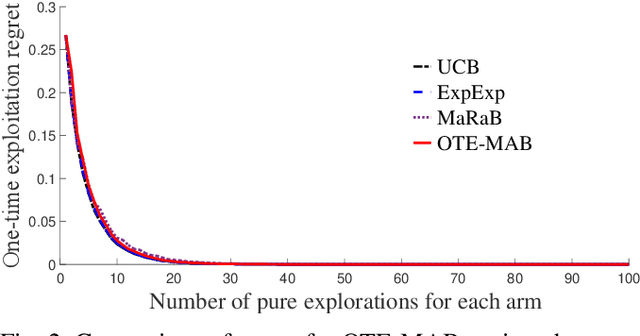
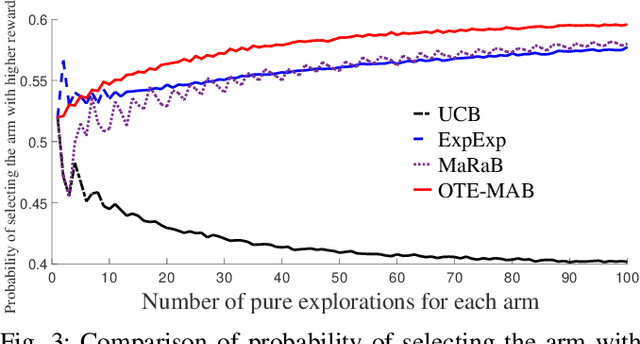
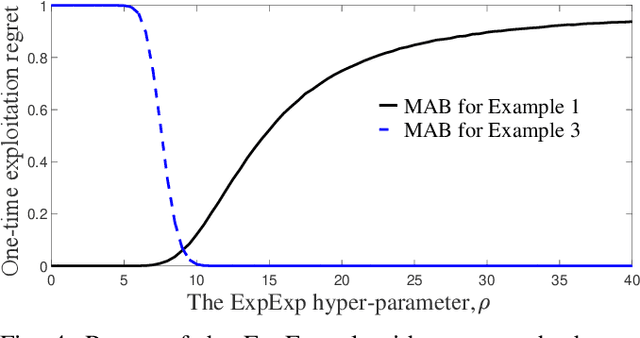
In this paper, we study multi-armed bandit problems in explore-then-commit setting. In our proposed explore-then-commit setting, the goal is to identify the best arm after a pure experimentation (exploration) phase and exploit it once or for a given finite number of times. We identify that although the arm with the highest expected reward is the most desirable objective for infinite exploitations, it is not necessarily the one that is most probable to have the highest reward in a single or finite-time exploitations. Alternatively, we advocate the idea of risk-aversion where the objective is to compete against the arm with the best risk-return trade-off. Then, we propose two algorithms whose objectives are to select the arm that is most probable to reward the most. Using a new notion of finite-time exploitation regret, we find an upper bound for the minimum number of experiments before commitment, to guarantee an upper bound for the regret. As compared to existing risk-averse bandit algorithms, our algorithms do not rely on hyper-parameters, resulting in a more robust behavior in practice, which is verified by the numerical evaluation.