 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for CUDA+MPI Design Rules
Mar 17, 2022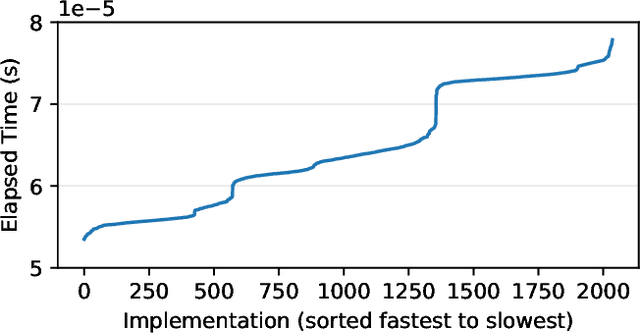
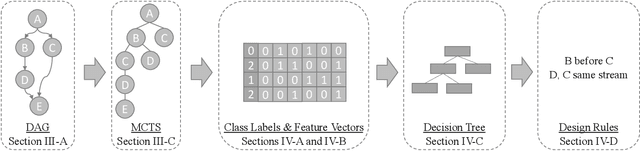
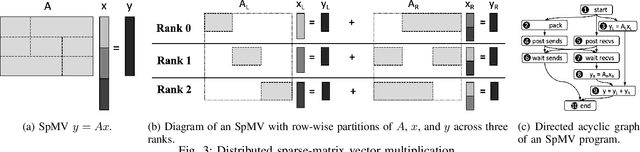
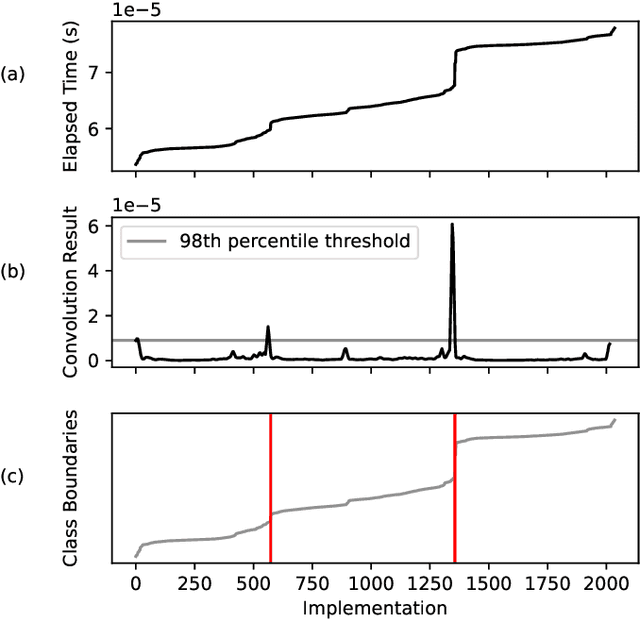
We present a new strategy for automatically exploring the design space of key CUDA+MPI programs and providing design rules that discriminate slow from fast implementations. In such programs, the order of operations (e.g., GPU kernels, MPI communication) and assignment of operations to resources (e.g., GPU streams) makes the space of possible designs enormous. Systems experts have the task of redesigning and reoptimizing these programs to effectively utilize each new platform. This work provides a prototype tool to reduce that burden. In our approach, a directed acyclic graph of CUDA and MPI operations defines the design space for the program. Monte-Carlo tree search discovers regions of the design space that have large impact on the program's performance. A sequence-to-vector transformation defines features for each explored implementation, and each implementation is assigned a class label according to its relative performance. A decision tree is trained on the features and labels to produce design rules for each class; these rules can be used by systems experts to guide their implementations. We demonstrate our strategy using a key kernel from scientific computing -- sparse-matrix vector multiplication -- on a platform with multiple MPI ranks and GPU streams.
At-Scale Sparse Deep Neural Network Inference with Efficient GPU Implementation
Sep 02, 2020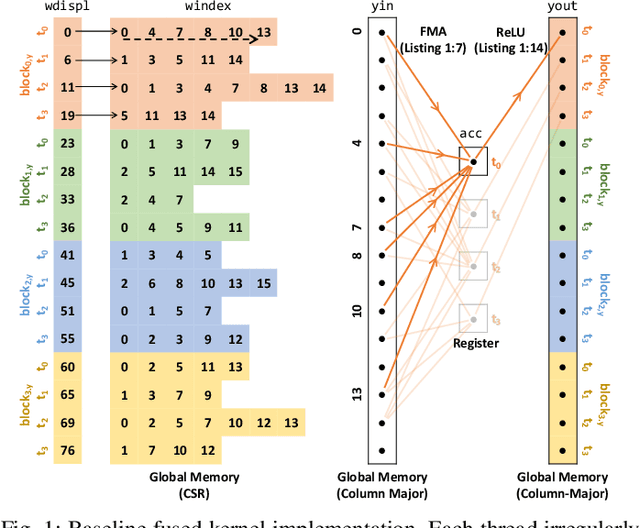
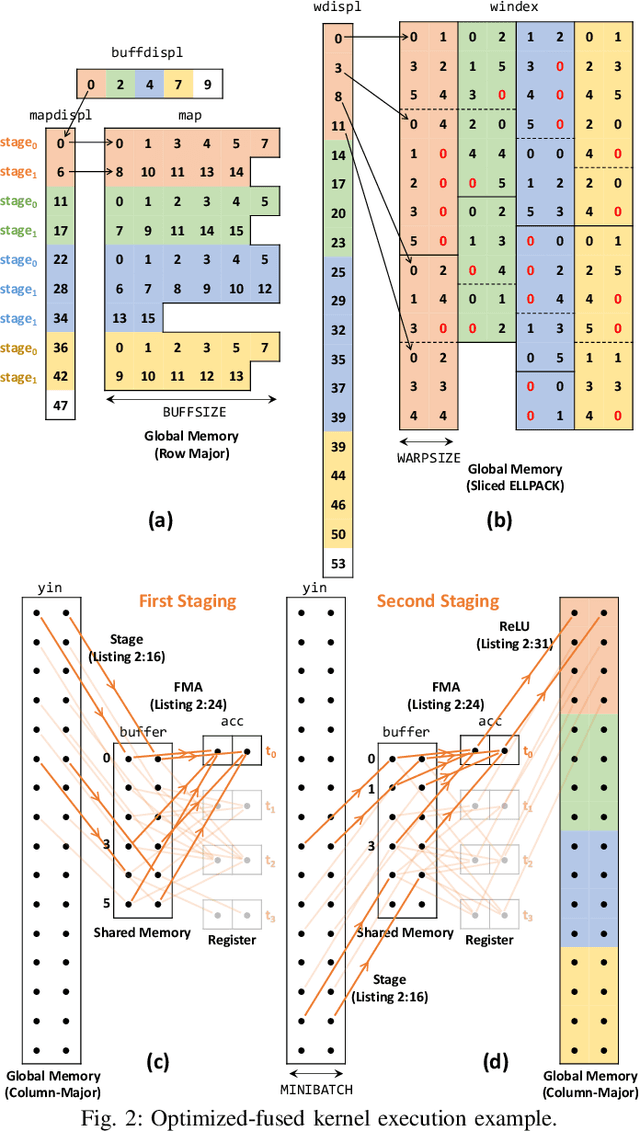
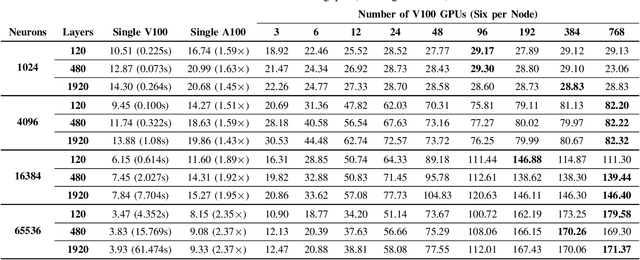
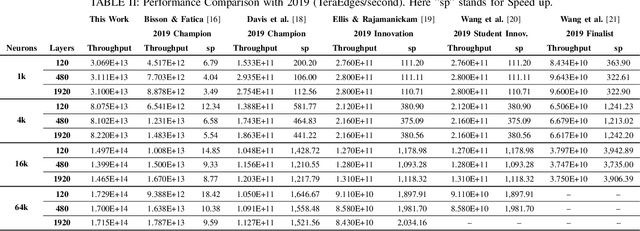
This paper presents GPU performance optimization and scaling results for inference models of the Sparse Deep Neural Network Challenge 2020. Demands for network quality have increased rapidly, pushing the size and thus the memory requirements of many neural networks beyond the capacity of available accelerators. Sparse deep neural networks (SpDNN) have shown promise for reining in the memory footprint of large neural networks. However, there is room for improvement in implementing SpDNN operations on GPUs. This work presents optimized sparse matrix multiplication kernels fused with the ReLU function. The optimized kernels reuse input feature maps from the shared memory and sparse weights from registers. For multi-GPU parallelism, our SpDNN implementation duplicates weights and statically partition the feature maps across GPUs. Results for the challenge benchmarks show that the proposed kernel design and multi-GPU parallelization achieve up to 180 tera-edges per second inference throughput. These results are up to 4.3x faster for a single GPU and an order of magnitude faster at full scale than those of the champion of the 2019 Sparse Deep Neural Network Graph Challenge for the same generation of NVIDIA V100 GPUs. Using the same implementation, we also show single-GPU throughput on NVIDIA A100 is 2.37$\times$ faster than V100.
* 7 pages