 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for CUDA+MPI Design Rules
Mar 17, 2022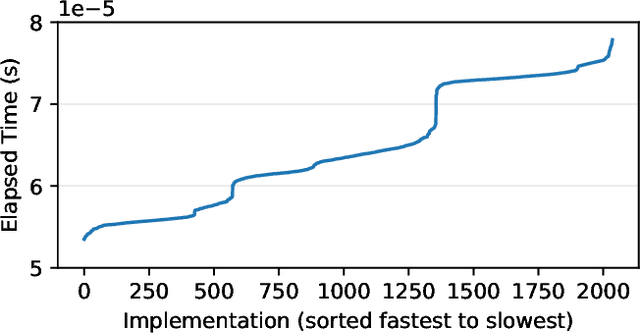
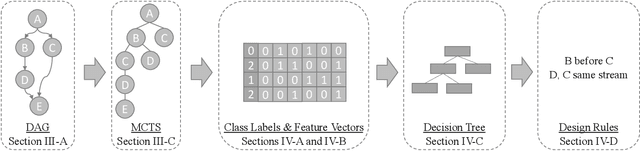
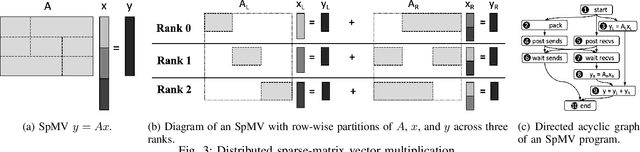
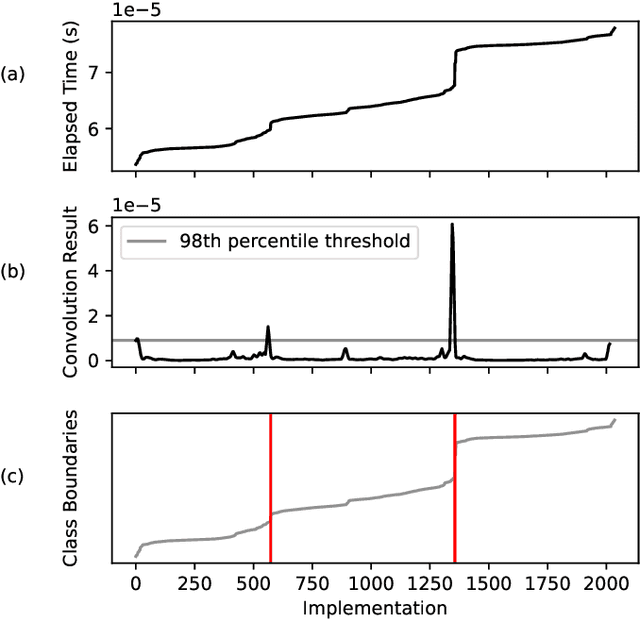
We present a new strategy for automatically exploring the design space of key CUDA+MPI programs and providing design rules that discriminate slow from fast implementations. In such programs, the order of operations (e.g., GPU kernels, MPI communication) and assignment of operations to resources (e.g., GPU streams) makes the space of possible designs enormous. Systems experts have the task of redesigning and reoptimizing these programs to effectively utilize each new platform. This work provides a prototype tool to reduce that burden. In our approach, a directed acyclic graph of CUDA and MPI operations defines the design space for the program. Monte-Carlo tree search discovers regions of the design space that have large impact on the program's performance. A sequence-to-vector transformation defines features for each explored implementation, and each implementation is assigned a class label according to its relative performance. A decision tree is trained on the features and labels to produce design rules for each class; these rules can be used by systems experts to guide their implementations. We demonstrate our strategy using a key kernel from scientific computing -- sparse-matrix vector multiplication -- on a platform with multiple MPI ranks and GPU streams.