 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpIDER: Spatially Informed Dense Embedding Retrieval for Software Issue Localization
Dec 18, 2025Retrieving code units (e.g., files, classes, functions) that are semantically relevant to a given user query, bug report, or feature request from large codebases is a fundamental challenge for LLM-based coding agents. Agentic approaches typically employ sparse retrieval methods like BM25 or dense embedding strategies to identify relevant units. While embedding-based approaches can outperform BM25 by large margins, they often lack exploration of the codebase and underutilize its underlying graph structure. To address this, we propose SpIDER (Spatially Informed Dense Embedding Retrieval), an enhanced dense retrieval approach that incorporates LLM-based reasoning over auxiliary context obtained through graph-based exploration of the codebase. Empirical results show that SpIDER consistently improves dense retrieval performance across several programming languages.
MoVE-KD: Knowledge Distillation for VLMs with Mixture of Visual Encoders
Jan 03, 2025



Visual encoders are fundamental components in vision-language models (VLMs), each showcasing unique strengths derived from various pre-trained visual foundation models. To leverage the various capabilities of these encoders, recent studies incorporate multiple encoders within a single VLM, leading to a considerable increase in computational cost. In this paper, we present Mixture-of-Visual-Encoder Knowledge Distillation (MoVE-KD), a novel framework that distills the unique proficiencies of multiple vision encoders into a single, efficient encoder model. Specifically, to mitigate conflicts and retain the unique characteristics of each teacher encoder, we employ low-rank adaptation (LoRA) and mixture-of-experts (MoEs) to selectively activate specialized knowledge based on input features, enhancing both adaptability and efficiency. To regularize the KD process and enhance performance, we propose an attention-based distillation strategy that adaptively weighs the different visual encoders and emphasizes valuable visual tokens, reducing the burden of replicating comprehensive but distinct features from multiple teachers. Comprehensive experiments on popular VLMs, such as LLaVA and LLaVA-NeXT, validate the effectiveness of our method. The code will be released.
[CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster
Dec 02, 2024![Figure 1 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F8-Table1-1.png&w=640&q=75)
![Figure 2 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F5-Figure3-1.png&w=640&q=75)
![Figure 4 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F9-Table3-1.png&w=640&q=75)
Large vision-language models (VLMs) often rely on a substantial number of visual tokens when interacting with large language models (LLMs), which has proven to be inefficient. Recent efforts have aimed to accelerate VLM inference by pruning visual tokens. Most existing methods assess the importance of visual tokens based on the text-visual cross-attentions in LLMs. In this study, we find that the cross-attentions between text and visual tokens in LLMs are inaccurate. Pruning tokens based on these inaccurate attentions leads to significant performance degradation, especially at high reduction ratios. To this end, we introduce FasterVLM, a simple yet effective training-free visual token pruning method that evaluates the importance of visual tokens more accurately by utilizing attentions between the [CLS] token and image tokens from the visual encoder. Since FasterVLM eliminates redundant visual tokens immediately after the visual encoder, ensuring they do not interact with LLMs and resulting in faster VLM inference. It is worth noting that, benefiting from the accuracy of [CLS] cross-attentions, FasterVLM can prune 95\% of visual tokens while maintaining 90\% of the performance of LLaVA-1.5-7B. We apply FasterVLM to various VLMs, including LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA, to demonstrate its effectiveness. Experimental results show that our FasterVLM maintains strong performance across various VLM architectures and reduction ratios, significantly outperforming existing text-visual attention-based methods. Our code is available at https://github.com/Theia-4869/FasterVLM.
MC-LLaVA: Multi-Concept Personalized Vision-Language Model
Nov 18, 2024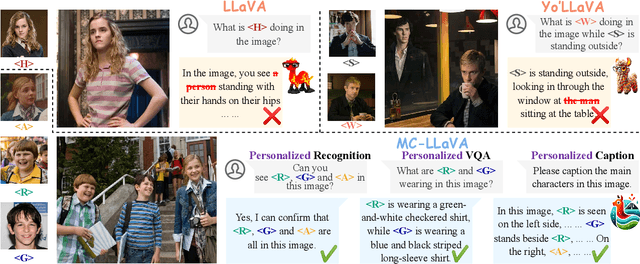

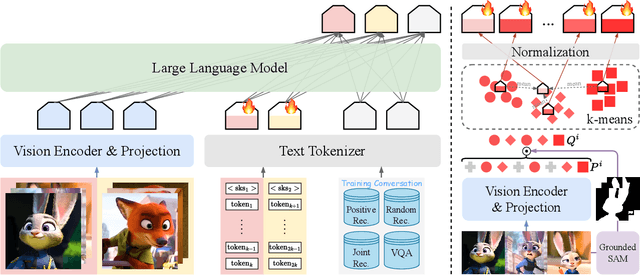
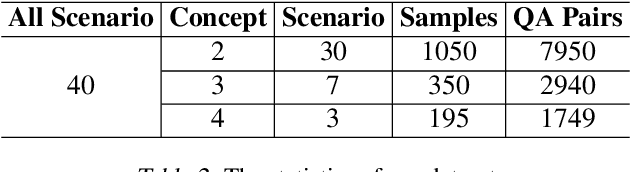
Current vision-language models (VLMs) show exceptional abilities across diverse tasks including visual question answering. To enhance user experience in practical applications, recent studies investigate VLM personalization to understand user-provided concepts. However, existing studies mainly focus on single-concept personalization, neglecting the existence and interplay of multiple concepts, which limits the real-world applicability of personalized VLMs. In this paper, we propose the first multi-concept personalization method named MC-LLaVA along with a high-quality multi-concept personalization dataset. Specifically, MC-LLaVA uses a joint training strategy incorporating multiple concepts in a single training step, allowing VLMs to perform accurately in multi-concept personalization. To reduce the cost of joint training, MC-LLaVA leverages visual token information for concept token initialization, yielding improved concept representation and accelerating joint training. To advance multi-concept personalization research, we further contribute a high-quality dataset. We carefully collect images from various movies that contain multiple characters and manually generate the multi-concept question-answer samples. Our dataset features diverse movie types and question-answer types. We conduct comprehensive qualitative and quantitative experiments to demonstrate that MC-LLaVA can achieve impressive multi-concept personalized responses, paving the way for VLMs to become better user-specific assistants. The code and dataset will be publicly available at https://github.com/arctanxarc/MC-LLaVA.
I-MedSAM: Implicit Medical Image Segmentation with Segment Anything
Nov 28, 2023With the development of Deep Neural Networks (DNNs), many efforts have been made to handle medical image segmentation. Traditional methods such as nnUNet train specific segmentation models on the individual datasets. Plenty of recent methods have been proposed to adapt the foundational Segment Anything Model (SAM) to medical image segmentation. However, they still focus on discrete representations to generate pixel-wise predictions, which are spatially inflexible and scale poorly to higher resolution. In contrast, implicit methods learn continuous representations for segmentation, which is crucial for medical image segmentation. In this paper, we propose I-MedSAM, which leverages the benefits of both continuous representations and SAM, to obtain better cross-domain ability and accurate boundary delineation. Since medical image segmentation needs to predict detailed segmentation boundaries, we designed a novel adapter to enhance the SAM features with high-frequency information during Parameter Efficient Fine Tuning (PEFT). To convert the SAM features and coordinates into continuous segmentation output, we utilize Implicit Neural Representation (INR) to learn an implicit segmentation decoder. We also propose an uncertainty-guided sampling strategy for efficient learning of INR. Extensive evaluations on 2D medical image segmentation tasks have shown that our proposed method with only 1.6M trainable parameters outperforms existing methods including discrete and continuous methods. The code will be released.