 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Text Tracking With a Spatio-Temporal Complementary Model
Paper and Code

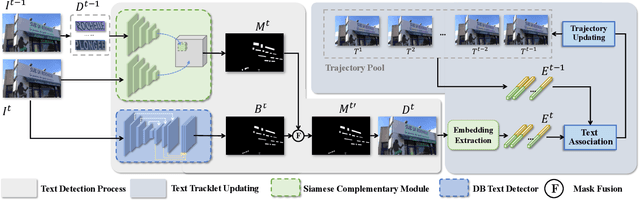
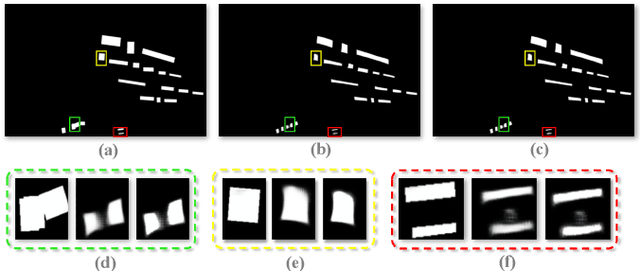

Text tracking is to track multiple texts in a video,and construct a trajectory for each text. Existing methodstackle this task by utilizing the tracking-by-detection frame-work, i.e., detecting the text instances in each frame andassociating the corresponding text instances in consecutiveframes. We argue that the tracking accuracy of this paradigmis severely limited in more complex scenarios, e.g., owing tomotion blur, etc., the missed detection of text instances causesthe break of the text trajectory. In addition, different textinstances with similar appearance are easily confused, leadingto the incorrect association of the text instances. To this end,a novel spatio-temporal complementary text tracking model isproposed in this paper. We leverage a Siamese ComplementaryModule to fully exploit the continuity characteristic of the textinstances in the temporal dimension, which effectively alleviatesthe missed detection of the text instances, and hence ensuresthe completeness of each text trajectory. We further integratethe semantic cues and the visual cues of the text instance intoa unified representation via a text similarity learning network,which supplies a high discriminative power in the presence oftext instances with similar appearance, and thus avoids the mis-association between them. Our method achieves state-of-the-art performance on several public benchmarks. The source codeis available at https://github.com/lsabrinax/VideoTextSCM.