 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructRAG: Leveraging Retrieval-Augmented Generation on Instruction Graphs for LLM-Based Task Planning
Apr 17, 2025Recent advancements in large language models (LLMs) have enabled their use as agents for planning complex tasks. Existing methods typically rely on a thought-action-observation (TAO) process to enhance LLM performance, but these approaches are often constrained by the LLMs' limited knowledge of complex tasks. Retrieval-augmented generation (RAG) offers new opportunities by leveraging external databases to ground generation in retrieved information. In this paper, we identify two key challenges (enlargability and transferability) in applying RAG to task planning. We propose InstructRAG, a novel solution within a multi-agent meta-reinforcement learning framework, to address these challenges. InstructRAG includes a graph to organize past instruction paths (sequences of correct actions), an RL-Agent with Reinforcement Learning to expand graph coverage for enlargability, and an ML-Agent with Meta-Learning to improve task generalization for transferability. The two agents are trained end-to-end to optimize overall planning performance. Our experiments on four widely used task planning datasets demonstrate that InstructRAG significantly enhances performance and adapts efficiently to new tasks, achieving up to a 19.2% improvement over the best existing approach.
MASTER: A Multi-Agent System with LLM Specialized MCTS
Jan 24, 2025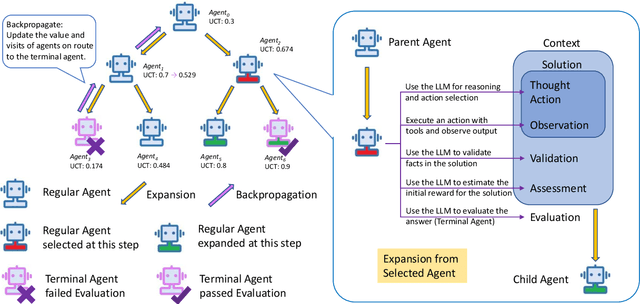
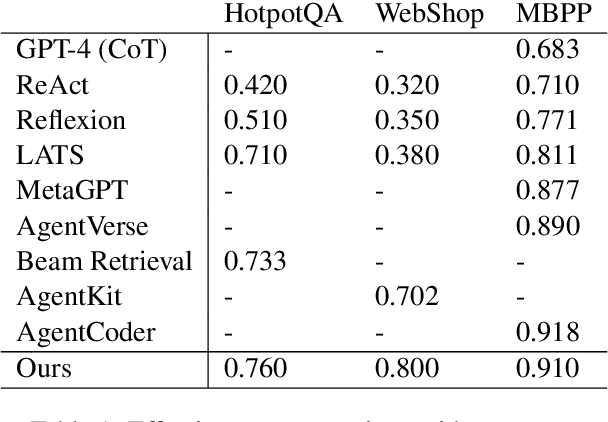
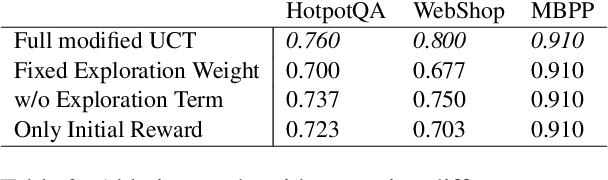
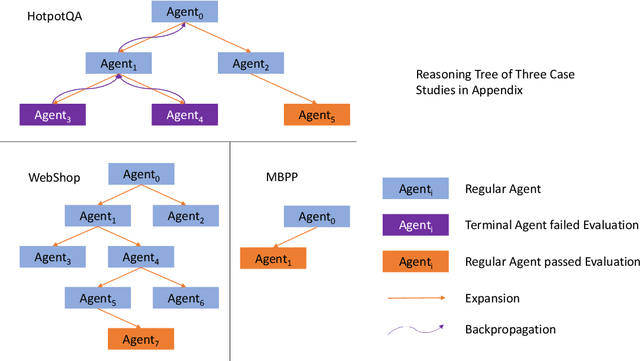
Large Language Models (LLM) are increasingly being explored for problem-solving tasks. However, their strategic planning capability is often viewed with skepticism. Recent studies have incorporated the Monte Carlo Tree Search (MCTS) algorithm to augment the planning capacity of LLM. Despite its potential, MCTS relies on extensive sampling simulations to approximate the true reward distribution, leading to two primary issues. Firstly, MCTS is effective for tasks like the Game of Go, where simulation results can yield objective rewards (e.g., 1 for a win and 0 for a loss). However, for tasks such as question answering, the result of a simulation is the answer to the question, which cannot obtain an objective reward without the ground truth. Secondly, obtaining statistically significant reward estimations typically requires a sample size exceeding 30 simulations, resulting in excessive token usage and time consumption. To address these challenges, we present Multi-Agent System with Tactical Execution and Reasoning using LLM Specialized MCTS (MASTER), a novel framework that coordinates agent recruitment and communication using LLM specialized MCTS. This system autonomously adjusts the number of agents based on task complexity and ensures focused communication among them. Comprehensive experiments across various tasks demonstrate the effectiveness of our proposed framework. It achieves 76% accuracy on HotpotQA and 80% on WebShop, setting new state-of-the-art performance on these datasets.
M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions
May 26, 2024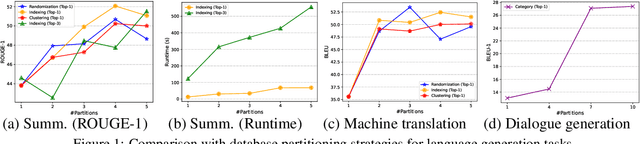
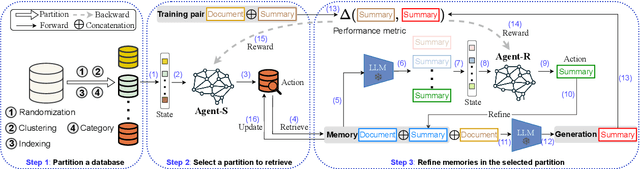


Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant memories from an external database. However, existing RAG methods typically organize all memories in a whole database, potentially limiting focus on crucial memories and introducing noise. In this paper, we introduce a multiple partition paradigm for RAG (called M-RAG), where each database partition serves as a basic unit for RAG execution. Based on this paradigm, we propose a novel framework that leverages LLMs with Multi-Agent Reinforcement Learning to optimize different language generation tasks explicitly. Through comprehensive experiments conducted on seven datasets, spanning three language generation tasks and involving three distinct language model architectures, we confirm that M-RAG consistently outperforms various baseline methods, achieving improvements of 11%, 8%, and 12% for text summarization, machine translation, and dialogue generation, respectively.