 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTTER: Open-Tagging via Text-Image Representation for Multi-modal Understanding
Oct 01, 2025



We introduce OTTER, a unified open-set multi-label tagging framework that harmonizes the stability of a curated, predefined category set with the adaptability of user-driven open tags. OTTER is built upon a large-scale, hierarchically organized multi-modal dataset, collected from diverse online repositories and annotated through a hybrid pipeline combining automated vision-language labeling with human refinement. By leveraging a multi-head attention architecture, OTTER jointly aligns visual and textual representations with both fixed and open-set label embeddings, enabling dynamic and semantically consistent tagging. OTTER consistently outperforms competitive baselines on two benchmark datasets: it achieves an overall F1 score of 0.81 on Otter and 0.75 on Favorite, surpassing the next-best results by margins of 0.10 and 0.02, respectively. OTTER attains near-perfect performance on open-set labels, with F1 of 0.99 on Otter and 0.97 on Favorite, while maintaining competitive accuracy on predefined labels. These results demonstrate OTTER's effectiveness in bridging closed-set consistency with open-vocabulary flexibility for multi-modal tagging applications.
M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions
May 26, 2024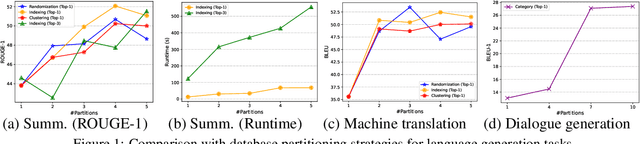
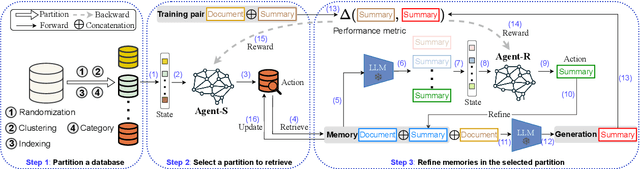


Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant memories from an external database. However, existing RAG methods typically organize all memories in a whole database, potentially limiting focus on crucial memories and introducing noise. In this paper, we introduce a multiple partition paradigm for RAG (called M-RAG), where each database partition serves as a basic unit for RAG execution. Based on this paradigm, we propose a novel framework that leverages LLMs with Multi-Agent Reinforcement Learning to optimize different language generation tasks explicitly. Through comprehensive experiments conducted on seven datasets, spanning three language generation tasks and involving three distinct language model architectures, we confirm that M-RAG consistently outperforms various baseline methods, achieving improvements of 11%, 8%, and 12% for text summarization, machine translation, and dialogue generation, respectively.