 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning User Interests via Reasoning and Distillation for Cross-Domain News Recommendation
Feb 16, 2026News recommendation plays a critical role in online news platforms by helping users discover relevant content. Cross-domain news recommendation further requires inferring user's underlying information needs from heterogeneous signals that often extend beyond direct news consumption. A key challenge lies in moving beyond surface-level behaviors to capture deeper, reusable user interests while maintaining scalability in large-scale production systems. In this paper, we present a reinforcement learning framework that trains large language models to generate high-quality lists of interest-driven news search queries from cross-domain user signals. We formulate query-list generation as a policy optimization problem and employ GRPO with multiple reward signals. We systematically study two compute dimensions: inference-time sampling and model capacity, and empirically observe consistent improvements with increased compute that exhibit scaling-like behavior. Finally, we perform on-policy distillation to transfer the learned policy from a large, compute-intensive teacher to a compact student model suitable for scalable deployment. Extensive offline experiments, ablation studies and large-scale online A/B tests in a production news recommendation system demonstrate consistent gains in both interest modeling quality and downstream recommendation performance.
MASTER: A Multi-Agent System with LLM Specialized MCTS
Jan 24, 2025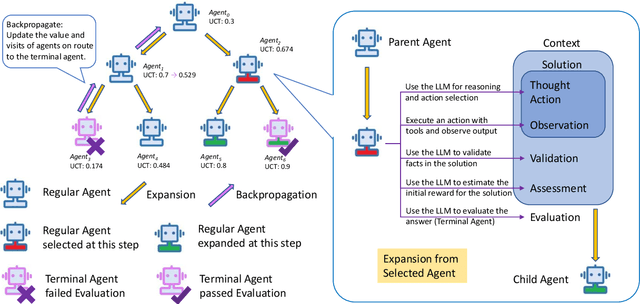
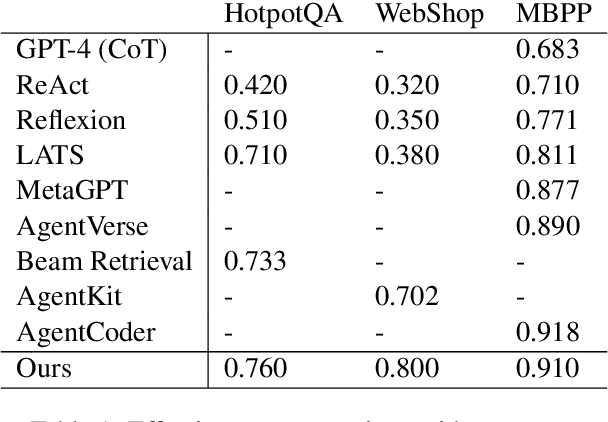
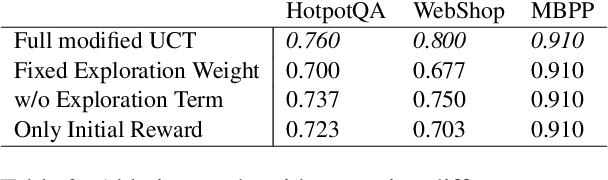
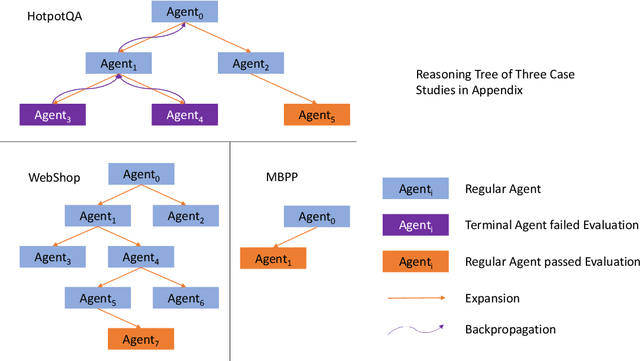
Large Language Models (LLM) are increasingly being explored for problem-solving tasks. However, their strategic planning capability is often viewed with skepticism. Recent studies have incorporated the Monte Carlo Tree Search (MCTS) algorithm to augment the planning capacity of LLM. Despite its potential, MCTS relies on extensive sampling simulations to approximate the true reward distribution, leading to two primary issues. Firstly, MCTS is effective for tasks like the Game of Go, where simulation results can yield objective rewards (e.g., 1 for a win and 0 for a loss). However, for tasks such as question answering, the result of a simulation is the answer to the question, which cannot obtain an objective reward without the ground truth. Secondly, obtaining statistically significant reward estimations typically requires a sample size exceeding 30 simulations, resulting in excessive token usage and time consumption. To address these challenges, we present Multi-Agent System with Tactical Execution and Reasoning using LLM Specialized MCTS (MASTER), a novel framework that coordinates agent recruitment and communication using LLM specialized MCTS. This system autonomously adjusts the number of agents based on task complexity and ensures focused communication among them. Comprehensive experiments across various tasks demonstrate the effectiveness of our proposed framework. It achieves 76% accuracy on HotpotQA and 80% on WebShop, setting new state-of-the-art performance on these datasets.
Are Pre-trained Language Models Knowledgeable to Ground Open Domain Dialogues?
Nov 19, 2020

We study knowledge-grounded dialogue generation with pre-trained language models. Instead of pursuing new state-of-the-art on benchmarks, we try to understand if the knowledge stored in parameters of the pre-trained models is already enough to ground open domain dialogues, and thus allows us to get rid of the dependency on external knowledge sources in generation. Through extensive experiments on benchmarks, we find that by fine-tuning with a few dialogues containing knowledge, the pre-trained language models can outperform the state-of-the-art model that requires external knowledge in automatic evaluation and human judgment, suggesting a positive answer to the question we raised.
Zero-Resource Knowledge-Grounded Dialogue Generation
Aug 29, 2020


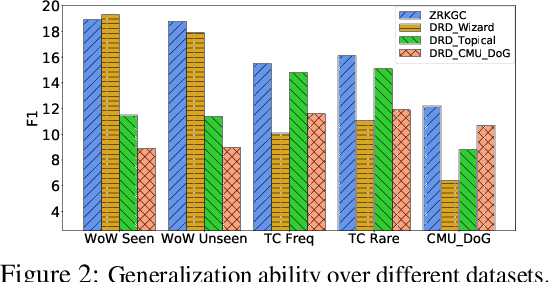
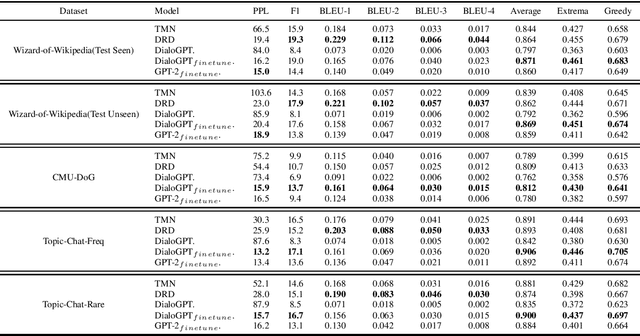
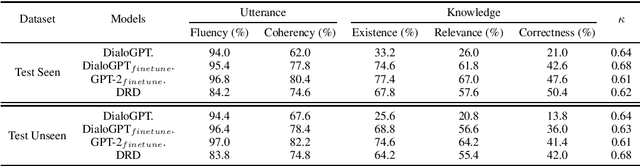
While neural conversation models have shown great potentials towards generating informative and engaging responses via introducing external knowledge, learning such a model often requires knowledge-grounded dialogues that are difficult to obtain. To overcome the data challenge and reduce the cost of building a knowledge-grounded dialogue system, we explore the problem under a zero-resource setting by assuming no context-knowledge-response triples are needed for training. To this end, we propose representing the knowledge that bridges a context and a response and the way that the knowledge is expressed as latent variables, and devise a variational approach that can effectively estimate a generation model from a dialogue corpus and a knowledge corpus that are independent with each other. Evaluation results on three benchmarks of knowledge-grounded dialogue generation indicate that our model can achieve comparable performance with state-of-the-art methods that rely on knowledge-grounded dialogues for training, and exhibits a good generalization ability over different topics and different datasets.
Learning a Simple and Effective Model for Multi-turn Response Generation with Auxiliary Tasks
Apr 04, 2020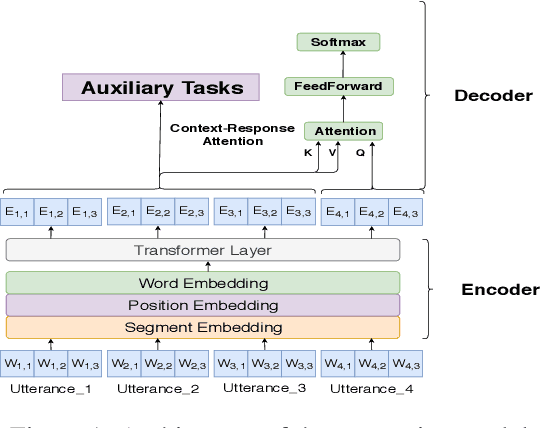
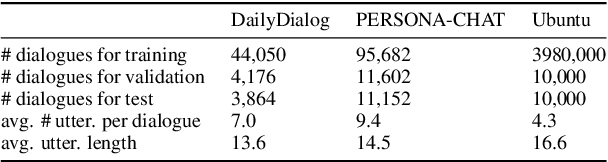

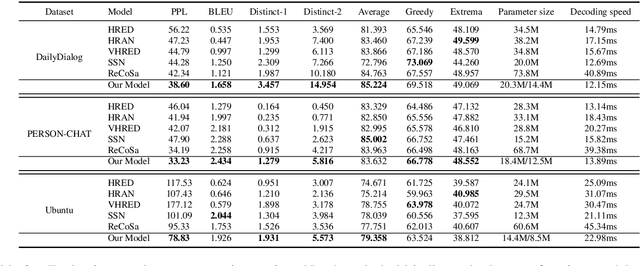
We study multi-turn response generation for open-domain dialogues. The existing state-of-the-art addresses the problem with deep neural architectures. While these models improved response quality, their complexity also hinders the application of the models in real systems. In this work, we pursue a model that has a simple structure yet can effectively leverage conversation contexts for response generation. To this end, we propose four auxiliary tasks including word order recovery, utterance order recovery, masked word recovery, and masked utterance recovery, and optimize the objectives of these tasks together with maximizing the likelihood of generation. By this means, the auxiliary tasks that relate to context understanding can guide the learning of the generation model to achieve a better local optimum. Empirical studies with three benchmarks indicate that our model can significantly outperform state-of-the-art generation models in terms of response quality on both automatic evaluation and human judgment, and at the same time enjoys a much faster decoding process.