 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-aware Language Representation Learning From Crowdsourced Labels
Paper and Code
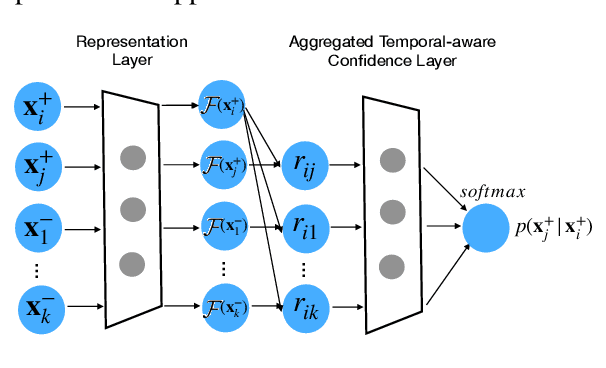


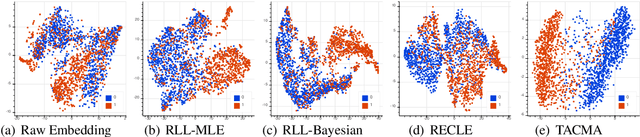
Learning effective language representations from crowdsourced labels is crucial for many real-world machine learning tasks. A challenging aspect of this problem is that the quality of crowdsourced labels suffer high intra- and inter-observer variability. Since the high-capacity deep neural networks can easily memorize all disagreements among crowdsourced labels, directly applying existing supervised language representation learning algorithms may yield suboptimal solutions. In this paper, we propose \emph{TACMA}, a \underline{t}emporal-\underline{a}ware language representation learning heuristic for \underline{c}rowdsourced labels with \underline{m}ultiple \underline{a}nnotators. The proposed approach (1) explicitly models the intra-observer variability with attention mechanism; (2) computes and aggregates per-sample confidence scores from multiple workers to address the inter-observer disagreements. The proposed heuristic is extremely easy to implement in around 5 lines of code. The proposed heuristic is evaluated on four synthetic and four real-world data sets. The results show that our approach outperforms a wide range of state-of-the-art baselines in terms of prediction accuracy and AUC. To encourage the reproducible results, we make our code publicly available at \url{https://github.com/CrowdsourcingMining/TACMA}.