 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuCrowd: Neural Sampling Network for Representation Learning with Crowdsourced Labels
Paper and Code

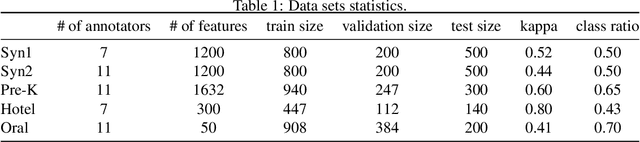
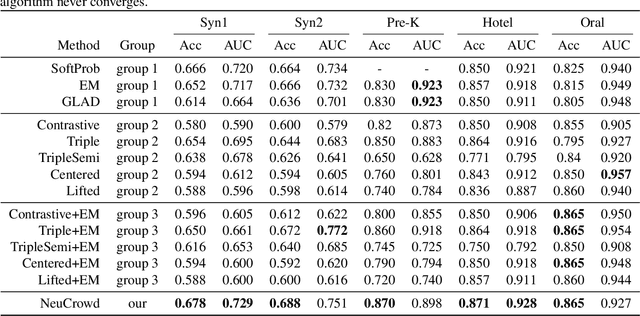

Representation learning approaches require a massive amount of discriminative training data, which is unavailable in many scenarios, such as healthcare, small city, education, etc. In practice, people refer to crowdsourcing to get annotated labels. However, due to issues like data privacy, budget limitation, shortage of domain-specific annotators, the number of crowdsourced labels are still very limited. Moreover, because of annotators' diverse expertises, crowdsourced labels are often inconsistent. Thus, directly applying existing representation learning algorithms may easily get the overfitting problem and yield suboptimal solutions. In this paper, we propose \emph{NeuCrowd}, a unified framework for representation learning from crowdsourced labels. The proposed framework (1) creates a sufficient number of high-quality \emph{n}-tuplet training samples by utilizing safety-aware sampling and robust anchor generation; and (2) automatically learns a neural sampling network that adaptively learns to select effective samples for representation learning network. The proposed framework is evaluated on both synthetic and real-world data sets. The results show that our approach outperforms a wide range of state-of-the-art baselines in terms of prediction accuracy and AUC\footnote{To encourage the reproducible results, we make our code public on a github repository, i.e., \url{https://github.com/crowd-data-mining/NeuCrowd}}.