 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTAL: Pre-training Cross-modal Transformer for Audio-and-Language Representations
Paper and Code
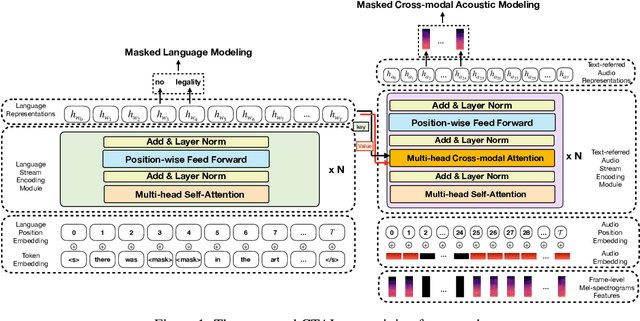
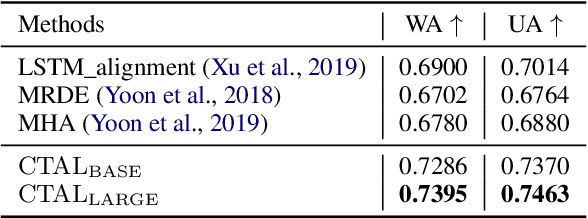
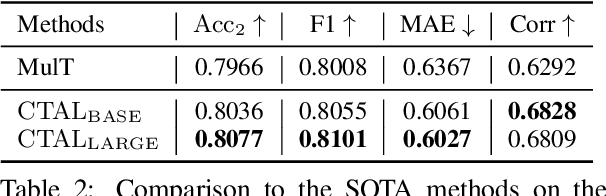
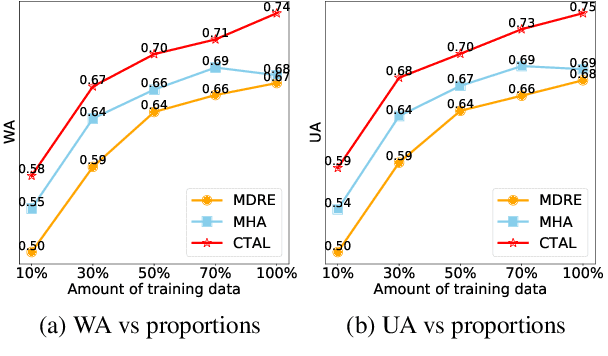
Existing audio-language task-specific predictive approaches focus on building complicated late-fusion mechanisms. However, these models are facing challenges of overfitting with limited labels and low model generalization abilities. In this paper, we present a Cross-modal Transformer for Audio-and-Language, i.e., CTAL, which aims to learn the intra-modality and inter-modality connections between audio and language through two proxy tasks on a large amount of audio-and-language pairs: masked language modeling and masked cross-modal acoustic modeling. After fine-tuning our pre-trained model on multiple downstream audio-and-language tasks, we observe significant improvements across various tasks, such as, emotion classification, sentiment analysis, and speaker verification. On this basis, we further propose a specially-designed fusion mechanism that can be used in fine-tuning phase, which allows our pre-trained model to achieve better performance. Lastly, we demonstrate detailed ablation studies to prove that both our novel cross-modality fusion component and audio-language pre-training methods significantly contribute to the promising results.