 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesimpleKT: A Simple But Tough-to-Beat Baseline for Knowledge Tracing
Feb 23, 2023Knowledge tracing (KT) is the problem of predicting students' future performance based on their historical interactions with intelligent tutoring systems. Recently, many works present lots of special methods for applying deep neural networks to KT from different perspectives like model architecture, adversarial augmentation and etc., which make the overall algorithm and system become more and more complex. Furthermore, due to the lack of standardized evaluation protocol \citep{liu2022pykt}, there is no widely agreed KT baselines and published experimental comparisons become inconsistent and self-contradictory, i.e., the reported AUC scores of DKT on ASSISTments2009 range from 0.721 to 0.821 \citep{minn2018deep,yeung2018addressing}. Therefore, in this paper, we provide a strong but simple baseline method to deal with the KT task named \textsc{simpleKT}. Inspired by the Rasch model in psychometrics, we explicitly model question-specific variations to capture the individual differences among questions covering the same set of knowledge components that are a generalization of terms of concepts or skills needed for learners to accomplish steps in a task or a problem. Furthermore, instead of using sophisticated representations to capture student forgetting behaviors, we use the ordinary dot-product attention function to extract the time-aware information embedded in the student learning interactions. Extensive experiments show that such a simple baseline is able to always rank top 3 in terms of AUC scores and achieve 57 wins, 3 ties and 16 loss against 12 DLKT baseline methods on 7 public datasets of different domains. We believe this work serves as a strong baseline for future KT research. Code is available at \url{https://github.com/pykt-team/pykt-toolkit}\footnote{We merged our model to the \textsc{pyKT} benchmark at \url{https://pykt.org/}.}.
Improving Interpretability of Deep Sequential Knowledge Tracing Models with Question-centric Cognitive Representations
Feb 19, 2023Knowledge tracing (KT) is a crucial technique to predict students' future performance by observing their historical learning processes. Due to the powerful representation ability of deep neural networks, remarkable progress has been made by using deep learning techniques to solve the KT problem. The majority of existing approaches rely on the \emph{homogeneous question} assumption that questions have equivalent contributions if they share the same set of knowledge components. Unfortunately, this assumption is inaccurate in real-world educational scenarios. Furthermore, it is very challenging to interpret the prediction results from the existing deep learning based KT models. Therefore, in this paper, we present QIKT, a question-centric interpretable KT model to address the above challenges. The proposed QIKT approach explicitly models students' knowledge state variations at a fine-grained level with question-sensitive cognitive representations that are jointly learned from a question-centric knowledge acquisition module and a question-centric problem solving module. Meanwhile, the QIKT utilizes an item response theory based prediction layer to generate interpretable prediction results. The proposed QIKT model is evaluated on three public real-world educational datasets. The results demonstrate that our approach is superior on the KT prediction task, and it outperforms a wide range of deep learning based KT models in terms of prediction accuracy with better model interpretability. To encourage reproducible results, we have provided all the datasets and code at \url{https://pykt.org/}.
Enhancing Deep Knowledge Tracing with Auxiliary Tasks
Feb 14, 2023
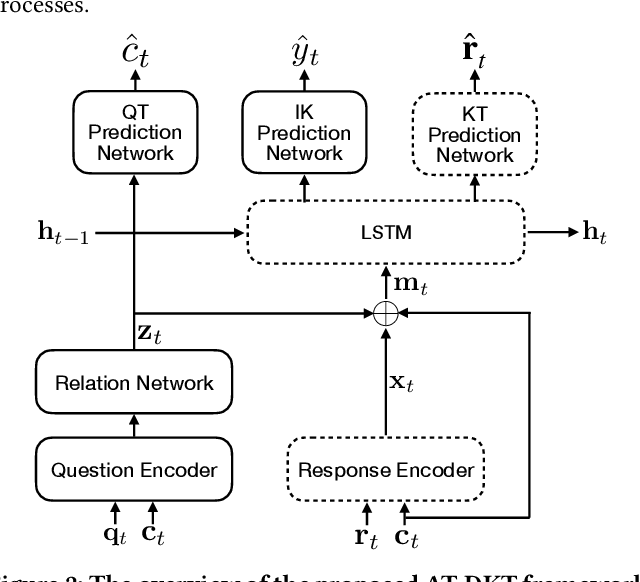

Knowledge tracing (KT) is the problem of predicting students' future performance based on their historical interactions with intelligent tutoring systems. Recent studies have applied multiple types of deep neural networks to solve the KT problem. However, there are two important factors in real-world educational data that are not well represented. First, most existing works augment input representations with the co-occurrence matrix of questions and knowledge components\footnote{\label{ft:kc}A KC is a generalization of everyday terms like concept, principle, fact, or skill.} (KCs) but fail to explicitly integrate such intrinsic relations into the final response prediction task. Second, the individualized historical performance of students has not been well captured. In this paper, we proposed \emph{AT-DKT} to improve the prediction performance of the original deep knowledge tracing model with two auxiliary learning tasks, i.e., \emph{question tagging (QT) prediction task} and \emph{individualized prior knowledge (IK) prediction task}. Specifically, the QT task helps learn better question representations by predicting whether questions contain specific KCs. The IK task captures students' global historical performance by progressively predicting student-level prior knowledge that is hidden in students' historical learning interactions. We conduct comprehensive experiments on three real-world educational datasets and compare the proposed approach to both deep sequential KT models and non-sequential models. Experimental results show that \emph{AT-DKT} outperforms all sequential models with more than 0.9\% improvements of AUC for all datasets, and is almost the second best compared to non-sequential models. Furthermore, we conduct both ablation studies and quantitative analysis to show the effectiveness of auxiliary tasks and the superior prediction outcomes of \emph{AT-DKT}.
SC-Ques: A Sentence Completion Question Dataset for English as a Second Language Learners
Jun 24, 2022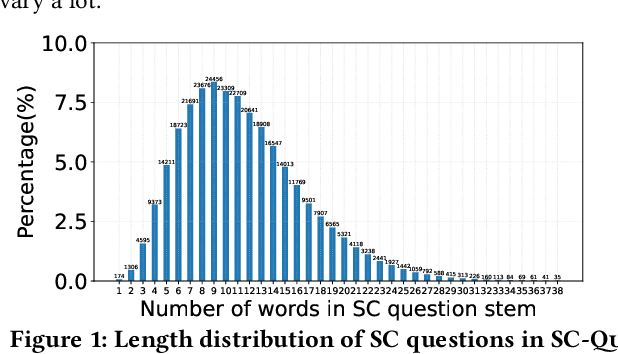


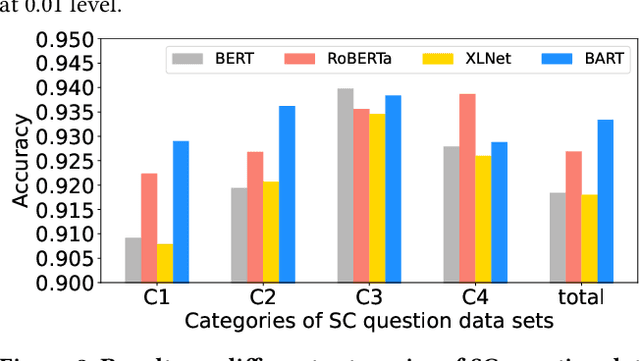
Sentence completion (SC) questions present a sentence with one or more blanks that need to be filled in, three to five possible words or phrases as options. SC questions are widely used for students learning English as a Second Language (ESL). In this paper, we present a large-scale SC dataset, \textsc{SC-Ques}, which is made up of 292,517 ESL SC questions from real-world standardized English examinations. Furthermore, we build a comprehensive benchmark of automatically solving the SC questions by training the large-scale pre-trained language models on the proposed \textsc{SC-Ques} dataset. We conduct detailed analysis of the baseline models performance, limitations and trade-offs. The data and our code are available for research purposes from: \url{https://github.com/ai4ed/SC-Ques}.
A Design of A Simple Yet Effective Exercise Recommendation System in K-12 Online Learning
Jun 23, 2022

We propose a simple but effective method to recommend exercises with high quality and diversity for students. Our method is made up of three key components: (1) candidate generation module; (2) diversity-promoting module; and (3) scope restriction module. The proposed method improves the overall recommendation performance in terms of recall, and increases the diversity of the recommended candidates by 0.81\% compared to the baselines.
pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models
Jun 23, 2022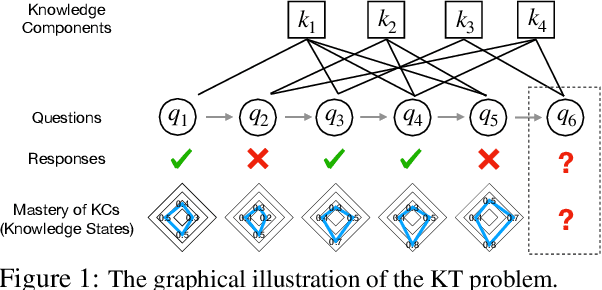
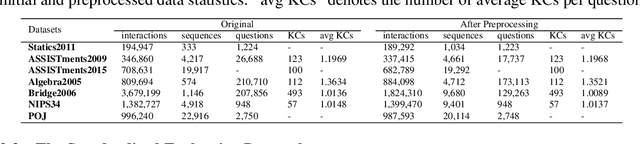
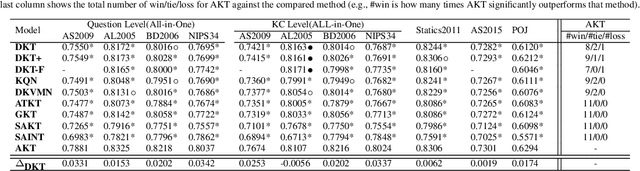
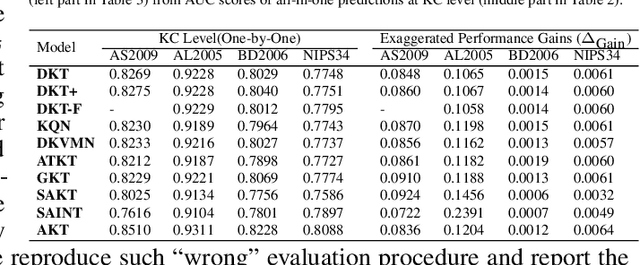
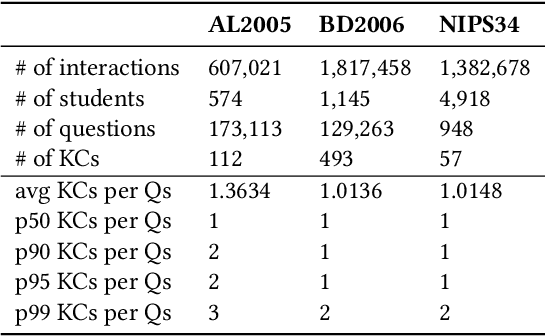
Knowledge tracing (KT) is the task of using students' historical learning interaction data to model their knowledge mastery over time so as to make predictions on their future interaction performance. Recently, remarkable progress has been made of using various deep learning techniques to solve the KT problem. However, the success behind deep learning based knowledge tracing (DLKT) approaches is still left somewhat mysterious and proper measurement and analysis of these DLKT approaches remain a challenge. First, data preprocessing procedures in existing works are often private and/or custom, which limits experimental standardization. Furthermore, existing DLKT studies often differ in terms of the evaluation protocol and are far away real-world educational contexts. To address these problems, we introduce a comprehensive python based benchmark platform, \textsc{pyKT}, to guarantee valid comparisons across DLKT methods via thorough evaluations. The \textsc{pyKT} library consists of a standardized set of integrated data preprocessing procedures on 7 popular datasets across different domains, and 10 frequently compared DLKT model implementations for transparent experiments. Results from our fine-grained and rigorous empirical KT studies yield a set of observations and suggestions for effective DLKT, e.g., wrong evaluation setting may cause label leakage that generally leads to performance inflation; and the improvement of many DLKT approaches is minimal compared to the very first DLKT model proposed by Piech et al. \cite{piech2015deep}. We have open sourced \textsc{pyKT} and our experimental results at \url{https://pykt.org/}. We welcome contributions from other research groups and practitioners.
Solving ESL Sentence Completion Questions via Pre-trained Neural Language Models
Jul 15, 2021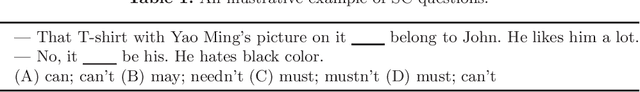
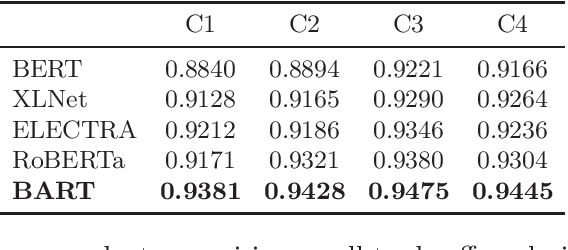
Sentence completion (SC) questions present a sentence with one or more blanks that need to be filled in, three to five possible words or phrases as options. SC questions are widely used for students learning English as a Second Language (ESL) and building computational approaches to automatically solve such questions is beneficial to language learners. In this work, we propose a neural framework to solve SC questions in English examinations by utilizing pre-trained language models. We conduct extensive experiments on a real-world K-12 ESL SC question dataset and the results demonstrate the superiority of our model in terms of prediction accuracy. Furthermore, we run precision-recall trade-off analysis to discuss the practical issues when deploying it in real-life scenarios. To encourage reproducible results, we make our code publicly available at \url{https://github.com/AIED2021/ESL-SentenceCompletion}.