Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAL EmotioNet Challenge 2020 Rethinking the Model Chosen Problem in Multi-Task Learning
Paper and Code
Apr 21, 2020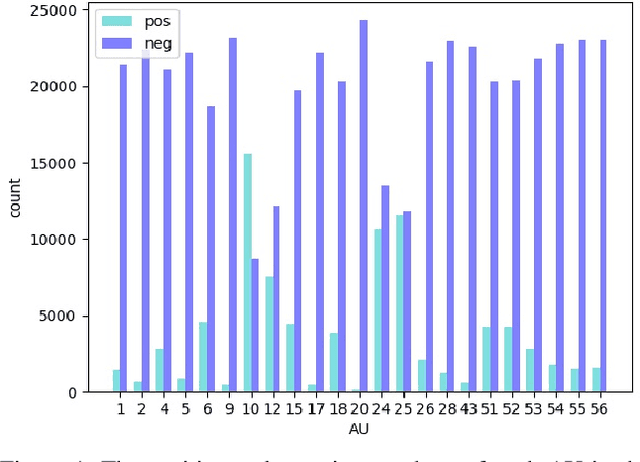
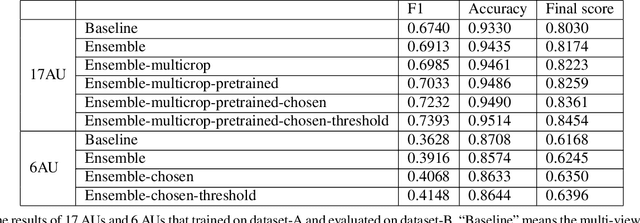
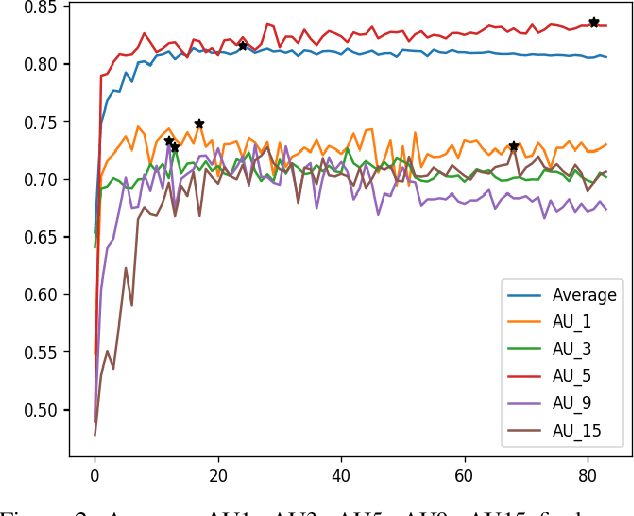

This paper introduces our approach to the EmotioNet Challenge 2020. We pose the AU recognition problem as a multi-task learning problem, where the non-rigid facial muscle motion (mainly the first 17 AUs) and the rigid head motion (the last 6 AUs) are modeled separately. The co-occurrence of the expression features and the head pose features are explored. We observe that different AUs converge at various speed. By choosing the optimal checkpoint for each AU, the recognition results are improved. We are able to obtain a final score of 0.746 in validation set and 0.7306 in the test set of the challenge.
* 4 pages, 2 figures, 3 tables, CVPRW2020
View paper on