 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQGEval: A Benchmark for Question Generation Evaluation
Paper and Code

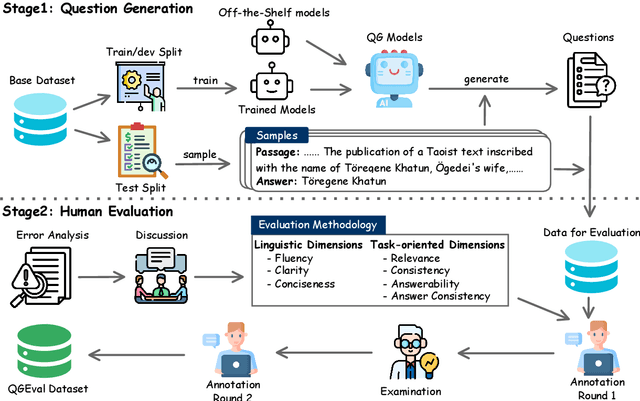
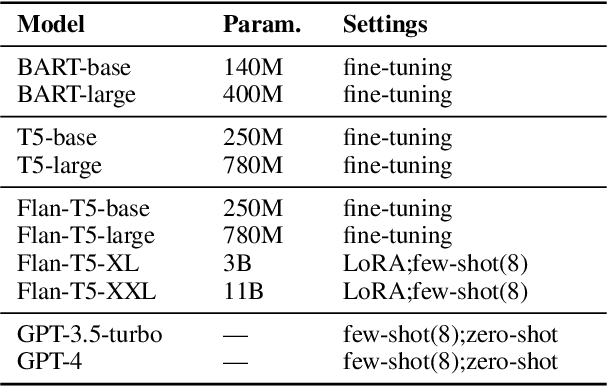
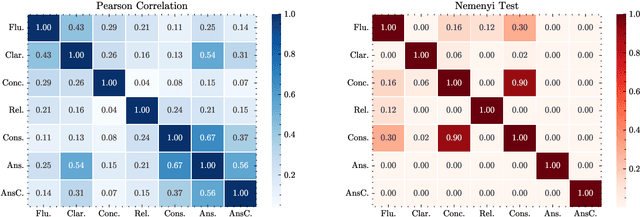
Automatically generated questions often suffer from problems such as unclear expression or factual inaccuracies, requiring a reliable and comprehensive evaluation of their quality. Human evaluation is frequently used in the field of question generation (QG) and is one of the most accurate evaluation methods. It also serves as the standard for automatic metrics. However, there is a lack of unified evaluation criteria, which hampers the development of both QG technologies and automatic evaluation methods. To address this, we propose QGEval, a multi-dimensional Evaluation benchmark for Question Generation, which evaluates both generated questions and existing automatic metrics across 7 dimensions: fluency, clarity, conciseness, relevance, consistency, answerability, and answer consistency. We demonstrate the appropriateness of these dimensions by examining their correlations and distinctions. Analysis with QGEval reveals that 1) most QG models perform unsatisfactorily in terms of answerability and answer consistency, and 2) existing metrics fail to align well with human assessments when evaluating generated questions across the 7 dimensions. We expect this work to foster the development of both QG technologies and automatic metrics for QG.