 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIGVE-Tool: AI-Generated Video Evaluation Toolkit with Multifaceted Benchmark
Mar 18, 2025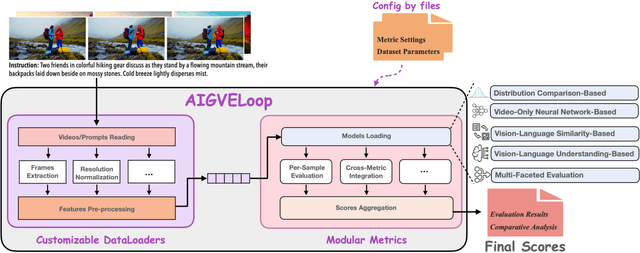
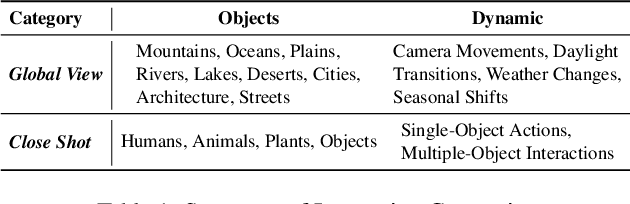
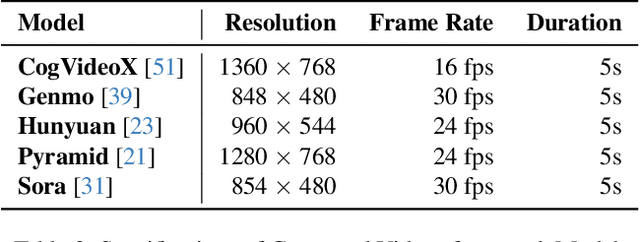
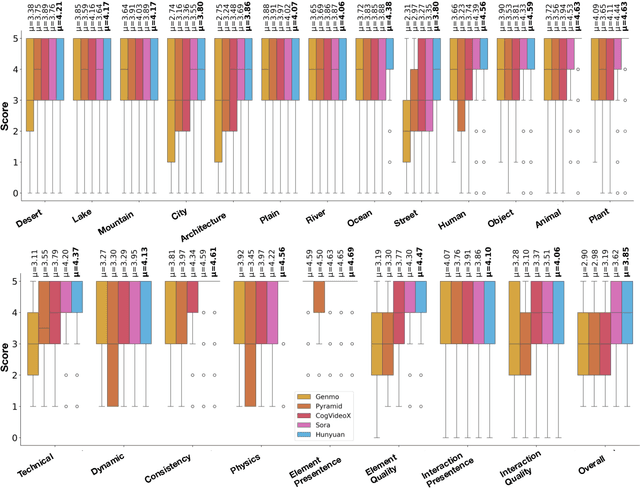
The rapid advancement in AI-generated video synthesis has led to a growth demand for standardized and effective evaluation metrics. Existing metrics lack a unified framework for systematically categorizing methodologies, limiting a holistic understanding of the evaluation landscape. Additionally, fragmented implementations and the absence of standardized interfaces lead to redundant processing overhead. Furthermore, many prior approaches are constrained by dataset-specific dependencies, limiting their applicability across diverse video domains. To address these challenges, we introduce AIGVE-Tool (AI-Generated Video Evaluation Toolkit), a unified framework that provides a structured and extensible evaluation pipeline for a comprehensive AI-generated video evaluation. Organized within a novel five-category taxonomy, AIGVE-Tool integrates multiple evaluation methodologies while allowing flexible customization through a modular configuration system. Additionally, we propose AIGVE-Bench, a large-scale benchmark dataset created with five SOTA video generation models based on hand-crafted instructions and prompts. This dataset systematically evaluates various video generation models across nine critical quality dimensions. Extensive experiments demonstrate the effectiveness of AIGVE-Tool in providing standardized and reliable evaluation results, highlighting specific strengths and limitations of current models and facilitating the advancements of next-generation AI-generated video techniques.
A Survey of AI-Generated Video Evaluation
Oct 24, 2024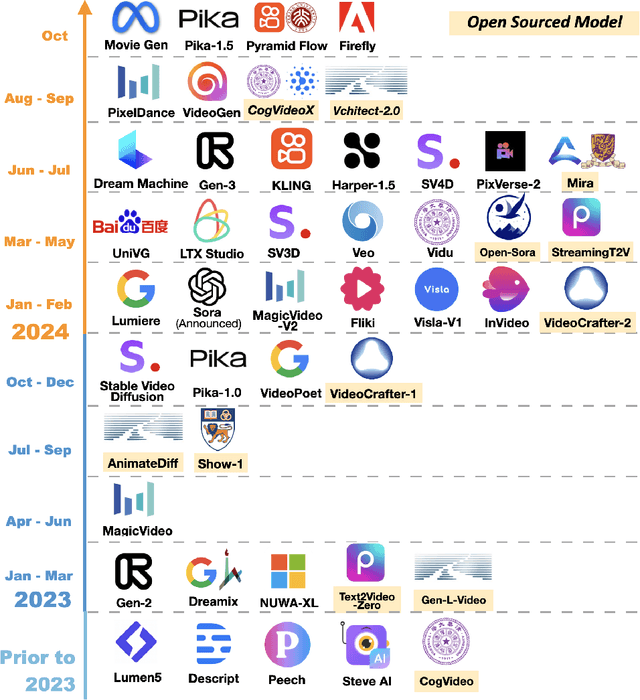
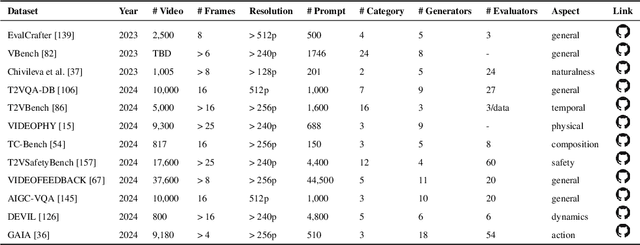

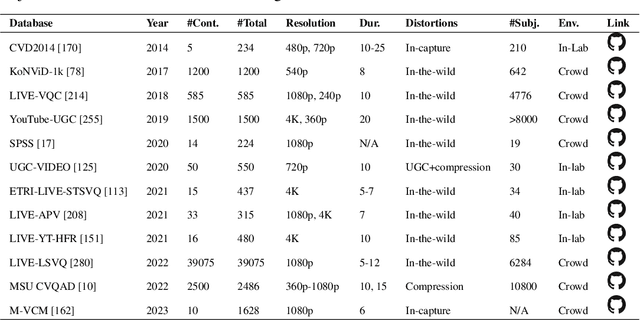
The growing capabilities of AI in generating video content have brought forward significant challenges in effectively evaluating these videos. Unlike static images or text, video content involves complex spatial and temporal dynamics which may require a more comprehensive and systematic evaluation of its contents in aspects like video presentation quality, semantic information delivery, alignment with human intentions, and the virtual-reality consistency with our physical world. This survey identifies the emerging field of AI-Generated Video Evaluation (AIGVE), highlighting the importance of assessing how well AI-generated videos align with human perception and meet specific instructions. We provide a structured analysis of existing methodologies that could be potentially used to evaluate AI-generated videos. By outlining the strengths and gaps in current approaches, we advocate for the development of more robust and nuanced evaluation frameworks that can handle the complexities of video content, which include not only the conventional metric-based evaluations, but also the current human-involved evaluations, and the future model-centered evaluations. This survey aims to establish a foundational knowledge base for both researchers from academia and practitioners from the industry, facilitating the future advancement of evaluation methods for AI-generated video content.
Intermediate Distillation: Data-Efficient Distillation from Black-Box LLMs for Information Retrieval
Jun 18, 2024
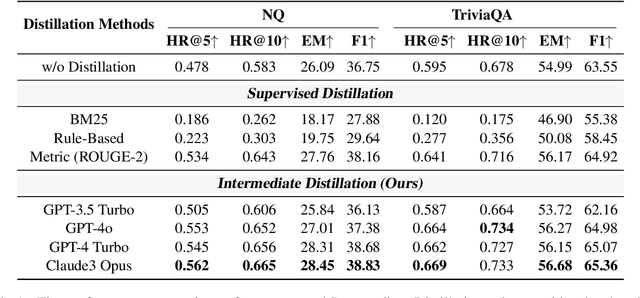
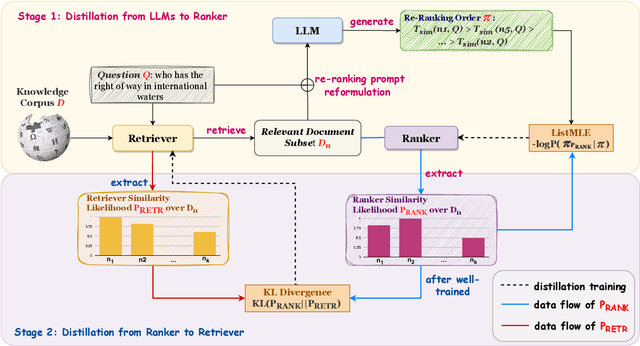
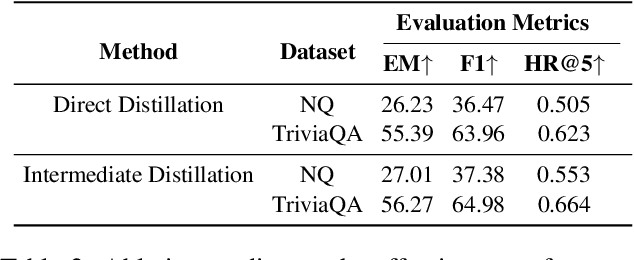
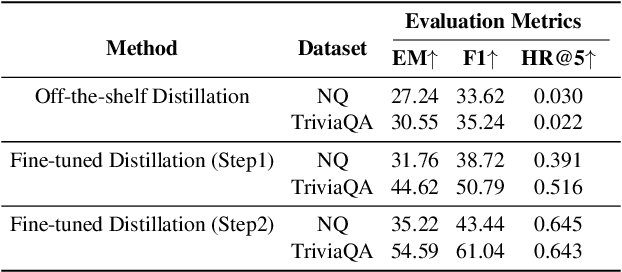
Recent research has explored distilling knowledge from large language models (LLMs) to optimize retriever models, especially within the retrieval-augmented generation (RAG) framework. However, most existing training methods rely on extracting supervision signals from LLMs' weights or their output probabilities, which is not only resource-intensive but also incompatible with black-box LLMs. In this paper, we introduce \textit{Intermediate Distillation}, a data-efficient knowledge distillation training scheme that treats LLMs as black boxes and distills their knowledge via an innovative LLM-ranker-retriever pipeline, solely using LLMs' ranking generation as the supervision signal. Extensive experiments demonstrate that our proposed method can significantly improve the performance of retriever models with only 1,000 training instances. Moreover, our distilled retriever model significantly boosts performance in question-answering tasks within the RAG framework, demonstrating the potential of LLMs to economically and effectively train smaller models.
Unveiling the Magic: Investigating Attention Distillation in Retrieval-augmented Generation
Feb 19, 2024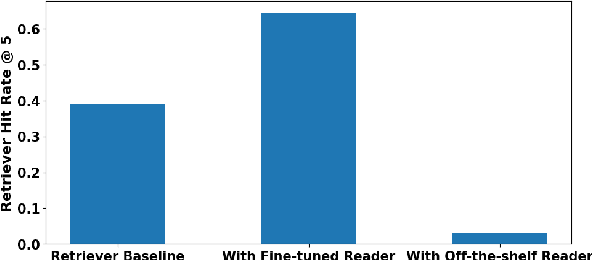
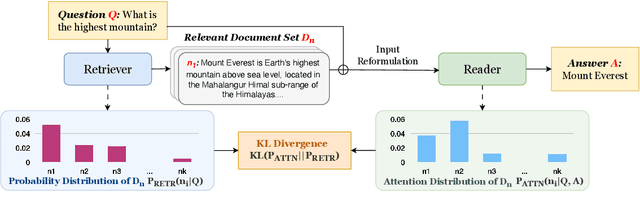
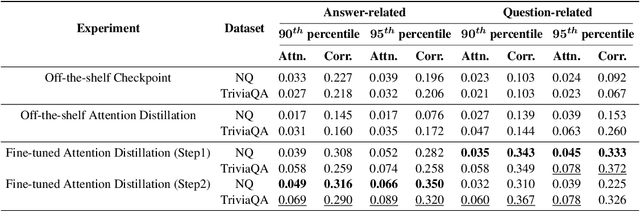
Retrieval-augmented generation framework can address the limitations of large language models by enabling real-time knowledge updates for more accurate answers. An efficient way in the training phase of retrieval-augmented models is attention distillation, which uses attention scores as a supervision signal instead of manually annotated query-document pairs. Despite its growing popularity, the detailed mechanisms behind the success of attention distillation remain unexplored, particularly the specific patterns it leverages to benefit training. In this paper, we address this gap by conducting a comprehensive review of attention distillation workflow and identifying key factors influencing the learning quality of retrieval-augmented language models. We further propose indicators for optimizing models' training methods and avoiding ineffective training.
A Revisit of Fake News Dataset with Augmented Fact-checking by ChatGPT
Dec 19, 2023The proliferation of fake news has emerged as a critical issue in recent years, requiring significant efforts to detect it. However, the existing fake news detection datasets are sourced from human journalists, which are likely to have inherent bias limitations due to the highly subjective nature of this task. In this paper, we revisit the existing fake news dataset verified by human journalists with augmented fact-checking by large language models (ChatGPT), and we name the augmented fake news dataset ChatGPT-FC. We quantitatively analyze the distinctions and resemblances between human journalists and LLM in assessing news subject credibility, news creator credibility, time-sensitive, and political framing. Our findings highlight LLM's potential to serve as a preliminary screening method, offering a promising avenue to mitigate the inherent biases of human journalists and enhance fake news detection.
Microstructure-Empowered Stock Factor Extraction and Utilization
Aug 16, 2023High-frequency quantitative investment is a crucial aspect of stock investment. Notably, order flow data plays a critical role as it provides the most detailed level of information among high-frequency trading data, including comprehensive data from the order book and transaction records at the tick level. The order flow data is extremely valuable for market analysis as it equips traders with essential insights for making informed decisions. However, extracting and effectively utilizing order flow data present challenges due to the large volume of data involved and the limitations of traditional factor mining techniques, which are primarily designed for coarser-level stock data. To address these challenges, we propose a novel framework that aims to effectively extract essential factors from order flow data for diverse downstream tasks across different granularities and scenarios. Our method consists of a Context Encoder and an Factor Extractor. The Context Encoder learns an embedding for the current order flow data segment's context by considering both the expected and actual market state. In addition, the Factor Extractor uses unsupervised learning methods to select such important signals that are most distinct from the majority within the given context. The extracted factors are then utilized for downstream tasks. In empirical studies, our proposed framework efficiently handles an entire year of stock order flow data across diverse scenarios, offering a broader range of applications compared to existing tick-level approaches that are limited to only a few days of stock data. We demonstrate that our method extracts superior factors from order flow data, enabling significant improvement for stock trend prediction and order execution tasks at the second and minute level.
RiSAWOZ: A Large-Scale Multi-Domain Wizard-of-Oz Dataset with Rich Semantic Annotations for Task-Oriented Dialogue Modeling
Oct 17, 2020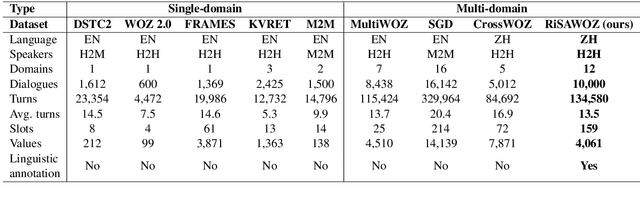
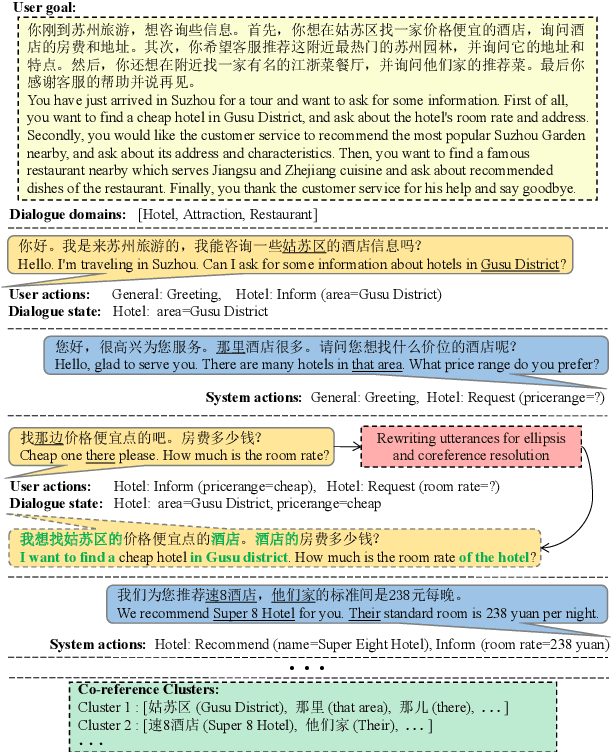
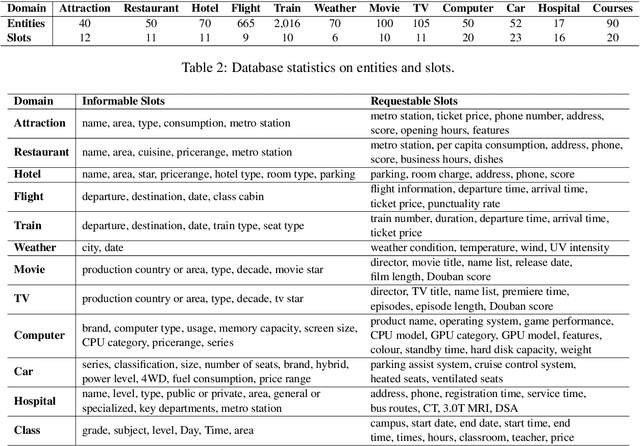

In order to alleviate the shortage of multi-domain data and to capture discourse phenomena for task-oriented dialogue modeling, we propose RiSAWOZ, a large-scale multi-domain Chinese Wizard-of-Oz dataset with Rich Semantic Annotations. RiSAWOZ contains 11.2K human-to-human (H2H) multi-turn semantically annotated dialogues, with more than 150K utterances spanning over 12 domains, which is larger than all previous annotated H2H conversational datasets. Both single- and multi-domain dialogues are constructed, accounting for 65% and 35%, respectively. Each dialogue is labeled with comprehensive dialogue annotations, including dialogue goal in the form of natural language description, domain, dialogue states and acts at both the user and system side. In addition to traditional dialogue annotations, we especially provide linguistic annotations on discourse phenomena, e.g., ellipsis and coreference, in dialogues, which are useful for dialogue coreference and ellipsis resolution tasks. Apart from the fully annotated dataset, we also present a detailed description of the data collection procedure, statistics and analysis of the dataset. A series of benchmark models and results are reported, including natural language understanding (intent detection & slot filling), dialogue state tracking and dialogue context-to-text generation, as well as coreference and ellipsis resolution, which facilitate the baseline comparison for future research on this corpus.