 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate Distillation: Data-Efficient Distillation from Black-Box LLMs for Information Retrieval
Paper and Code
Jun 18, 2024
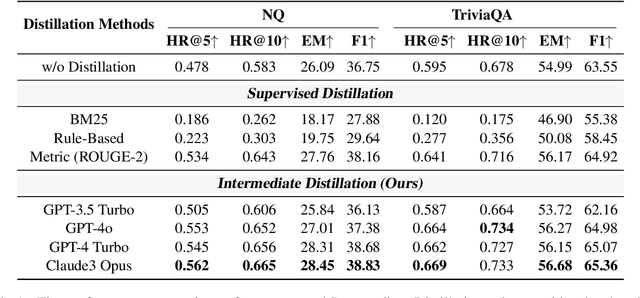
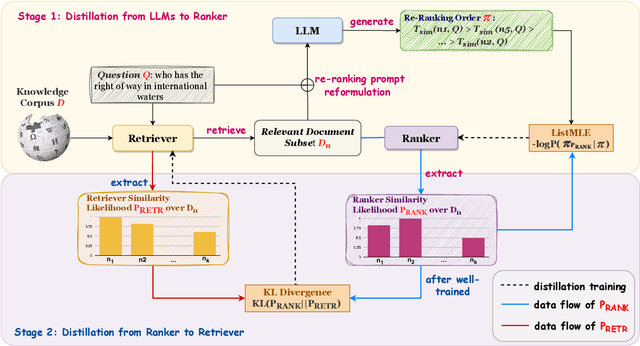
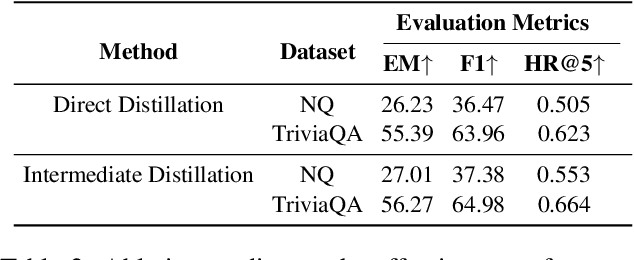
Recent research has explored distilling knowledge from large language models (LLMs) to optimize retriever models, especially within the retrieval-augmented generation (RAG) framework. However, most existing training methods rely on extracting supervision signals from LLMs' weights or their output probabilities, which is not only resource-intensive but also incompatible with black-box LLMs. In this paper, we introduce \textit{Intermediate Distillation}, a data-efficient knowledge distillation training scheme that treats LLMs as black boxes and distills their knowledge via an innovative LLM-ranker-retriever pipeline, solely using LLMs' ranking generation as the supervision signal. Extensive experiments demonstrate that our proposed method can significantly improve the performance of retriever models with only 1,000 training instances. Moreover, our distilled retriever model significantly boosts performance in question-answering tasks within the RAG framework, demonstrating the potential of LLMs to economically and effectively train smaller models.