 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Magic: Investigating Attention Distillation in Retrieval-augmented Generation
Paper and Code
Feb 19, 2024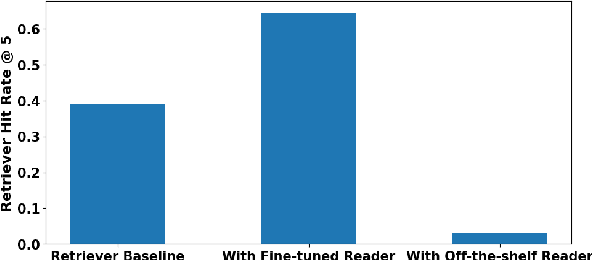
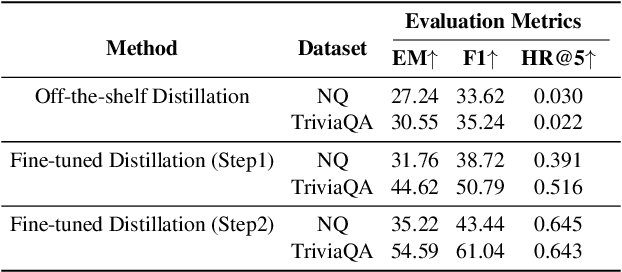
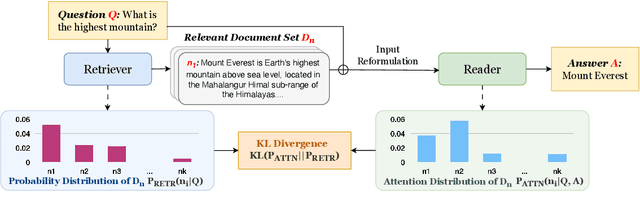
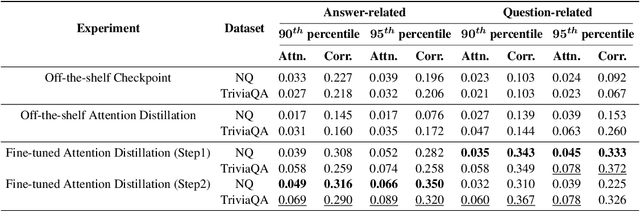
Retrieval-augmented generation framework can address the limitations of large language models by enabling real-time knowledge updates for more accurate answers. An efficient way in the training phase of retrieval-augmented models is attention distillation, which uses attention scores as a supervision signal instead of manually annotated query-document pairs. Despite its growing popularity, the detailed mechanisms behind the success of attention distillation remain unexplored, particularly the specific patterns it leverages to benefit training. In this paper, we address this gap by conducting a comprehensive review of attention distillation workflow and identifying key factors influencing the learning quality of retrieval-augmented language models. We further propose indicators for optimizing models' training methods and avoiding ineffective training.