 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccFace: Unified Occlusion-Aware Facial Landmark Detection with Per-Point Visibility
Feb 11, 2026Accurate facial landmark detection under occlusion remains challenging, especially for human-like faces with large appearance variation and rotation-driven self-occlusion. Existing detectors typically localize landmarks while handling occlusion implicitly, without predicting per-point visibility that downstream applications can benefits. We present OccFace, an occlusion-aware framework for universal human-like faces, including humans, stylized characters, and other non-human designs. OccFace adopts a unified dense 100-point layout and a heatmap-based backbone, and adds an occlusion module that jointly predicts landmark coordinates and per-point visibility by combining local evidence with cross-landmark context. Visibility supervision mixes manual labels with landmark-aware masking that derives pseudo visibility from mask-heatmap overlap. We also create an occlusion-aware evaluation suite reporting NME on visible vs. occluded landmarks and benchmarking visibility with Occ AP, F1@0.5, and ROC-AUC, together with a dataset annotated with 100-point landmarks and per-point visibility. Experiments show improved robustness under external occlusion and large head rotations, especially on occluded regions, while preserving accuracy on visible landmarks.
TTSA3R: Training-Free Temporal-Spatial Adaptive Persistent State for Streaming 3D Reconstruction
Jan 30, 2026Streaming recurrent models enable efficient 3D reconstruction by maintaining persistent state representations. However, they suffer from catastrophic memory forgetting over long sequences due to balancing historical information with new observations. Recent methods alleviate this by deriving adaptive signals from attention perspective, but they operate on single dimensions without considering temporal and spatial consistency. To this end, we propose a training-free framework termed TTSA3R that leverages both temporal state evolution and spatial observation quality for adaptive state updates in 3D reconstruction. In particular, we devise a Temporal Adaptive Update Module that regulates update magnitude by analyzing temporal state evolution patterns. Then, a Spatial Contextual Update Module is introduced to localize spatial regions that require updates through observation-state alignment and scene dynamics. These complementary signals are finally fused to determine the state updating strategies. Extensive experiments demonstrate the effectiveness of TTSA3R in diverse 3D tasks. Moreover, our method exhibits only 15% error increase compared to over 200% degradation in baseline models on extended sequences, significantly improving long-term reconstruction stability. Our codes will be available soon.
AIGVE-Tool: AI-Generated Video Evaluation Toolkit with Multifaceted Benchmark
Mar 18, 2025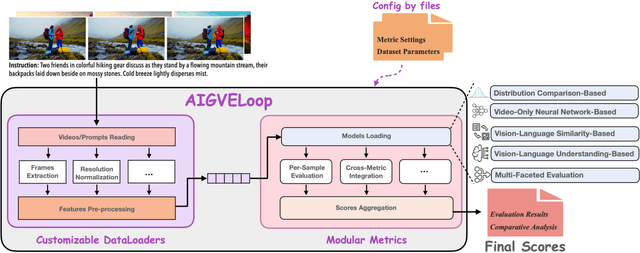
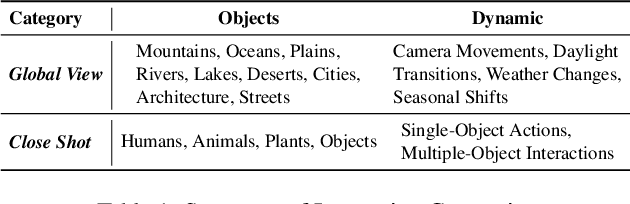
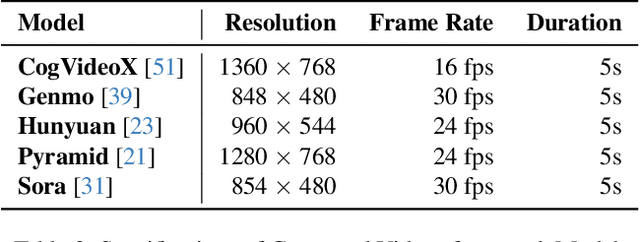
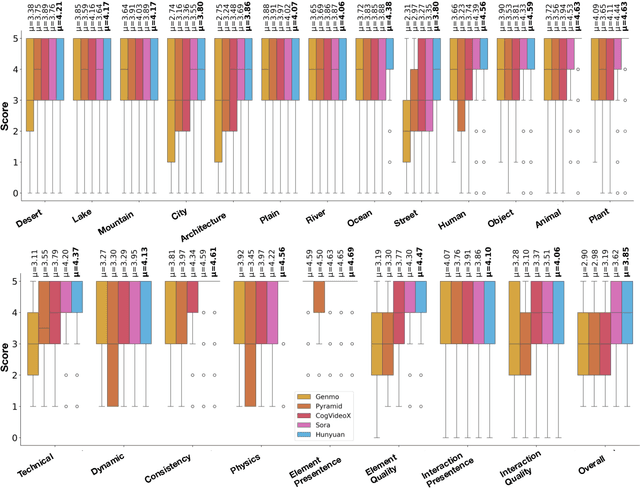
The rapid advancement in AI-generated video synthesis has led to a growth demand for standardized and effective evaluation metrics. Existing metrics lack a unified framework for systematically categorizing methodologies, limiting a holistic understanding of the evaluation landscape. Additionally, fragmented implementations and the absence of standardized interfaces lead to redundant processing overhead. Furthermore, many prior approaches are constrained by dataset-specific dependencies, limiting their applicability across diverse video domains. To address these challenges, we introduce AIGVE-Tool (AI-Generated Video Evaluation Toolkit), a unified framework that provides a structured and extensible evaluation pipeline for a comprehensive AI-generated video evaluation. Organized within a novel five-category taxonomy, AIGVE-Tool integrates multiple evaluation methodologies while allowing flexible customization through a modular configuration system. Additionally, we propose AIGVE-Bench, a large-scale benchmark dataset created with five SOTA video generation models based on hand-crafted instructions and prompts. This dataset systematically evaluates various video generation models across nine critical quality dimensions. Extensive experiments demonstrate the effectiveness of AIGVE-Tool in providing standardized and reliable evaluation results, highlighting specific strengths and limitations of current models and facilitating the advancements of next-generation AI-generated video techniques.
A Survey of AI-Generated Video Evaluation
Oct 24, 2024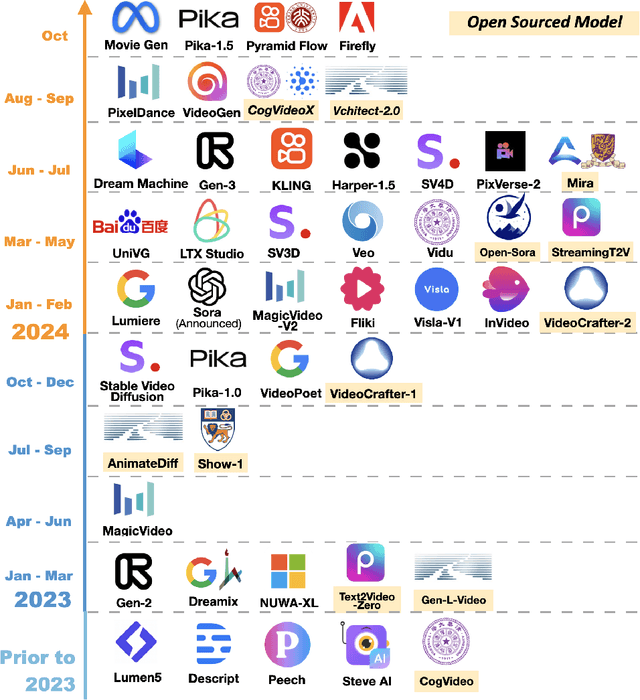
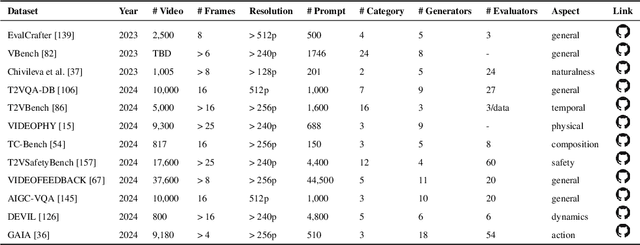

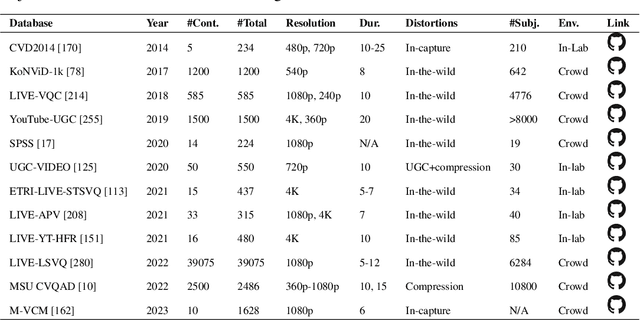
The growing capabilities of AI in generating video content have brought forward significant challenges in effectively evaluating these videos. Unlike static images or text, video content involves complex spatial and temporal dynamics which may require a more comprehensive and systematic evaluation of its contents in aspects like video presentation quality, semantic information delivery, alignment with human intentions, and the virtual-reality consistency with our physical world. This survey identifies the emerging field of AI-Generated Video Evaluation (AIGVE), highlighting the importance of assessing how well AI-generated videos align with human perception and meet specific instructions. We provide a structured analysis of existing methodologies that could be potentially used to evaluate AI-generated videos. By outlining the strengths and gaps in current approaches, we advocate for the development of more robust and nuanced evaluation frameworks that can handle the complexities of video content, which include not only the conventional metric-based evaluations, but also the current human-involved evaluations, and the future model-centered evaluations. This survey aims to establish a foundational knowledge base for both researchers from academia and practitioners from the industry, facilitating the future advancement of evaluation methods for AI-generated video content.
EffiPerception: an Efficient Framework for Various Perception Tasks
Mar 18, 2024



The accuracy-speed-memory trade-off is always the priority to consider for several computer vision perception tasks. Previous methods mainly focus on a single or small couple of these tasks, such as creating effective data augmentation, feature extractor, learning strategies, etc. These approaches, however, could be inherently task-specific: their proposed model's performance may depend on a specific perception task or a dataset. Targeting to explore common learning patterns and increasing the module robustness, we propose the EffiPerception framework. It could achieve great accuracy-speed performance with relatively low memory cost under several perception tasks: 2D Object Detection, 3D Object Detection, 2D Instance Segmentation, and 3D Point Cloud Segmentation. Overall, the framework consists of three parts: (1) Efficient Feature Extractors, which extract the input features for each modality. (2) Efficient Layers, plug-in plug-out layers that further process the feature representation, aggregating core learned information while pruning noisy proposals. (3) The EffiOptim, an 8-bit optimizer to further cut down the computational cost and facilitate performance stability. Extensive experiments on the KITTI, semantic-KITTI, and COCO datasets revealed that EffiPerception could show great accuracy-speed-memory overall performance increase within the four detection and segmentation tasks, in comparison to earlier, well-respected methods.
3DifFusionDet: Diffusion Model for 3D Object Detection with Robust LiDAR-Camera Fusion
Nov 07, 2023



Good 3D object detection performance from LiDAR-Camera sensors demands seamless feature alignment and fusion strategies. We propose the 3DifFusionDet framework in this paper, which structures 3D object detection as a denoising diffusion process from noisy 3D boxes to target boxes. In this framework, ground truth boxes diffuse in a random distribution for training, and the model learns to reverse the noising process. During inference, the model gradually refines a set of boxes that were generated at random to the outcomes. Under the feature align strategy, the progressive refinement method could make a significant contribution to robust LiDAR-Camera fusion. The iterative refinement process could also demonstrate great adaptability by applying the framework to various detecting circumstances where varying levels of accuracy and speed are required. Extensive experiments on KITTI, a benchmark for real-world traffic object identification, revealed that 3DifFusionDet is able to perform favorably in comparison to earlier, well-respected detectors.
FusionViT: Hierarchical 3D Object Detection via LiDAR-Camera Vision Transformer Fusion
Nov 07, 2023



For 3D object detection, both camera and lidar have been demonstrated to be useful sensory devices for providing complementary information about the same scenery with data representations in different modalities, e.g., 2D RGB image vs 3D point cloud. An effective representation learning and fusion of such multi-modal sensor data is necessary and critical for better 3D object detection performance. To solve the problem, in this paper, we will introduce a novel vision transformer-based 3D object detection model, namely FusionViT. Different from the existing 3D object detection approaches, FusionViT is a pure-ViT based framework, which adopts a hierarchical architecture by extending the transformer model to embed both images and point clouds for effective representation learning. Such multi-modal data embedding representations will be further fused together via a fusion vision transformer model prior to feeding the learned features to the object detection head for both detection and localization of the 3D objects in the input scenery. To demonstrate the effectiveness of FusionViT, extensive experiments have been done on real-world traffic object detection benchmark datasets KITTI and Waymo Open. Notably, our FusionViT model can achieve state-of-the-art performance and outperforms not only the existing baseline methods that merely rely on camera images or lidar point clouds, but also the latest multi-modal image-point cloud deep fusion approaches.