 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Prompts Learning with Cross-Modal Alignment for Attribute-based Person Re-Identification
Dec 28, 2023

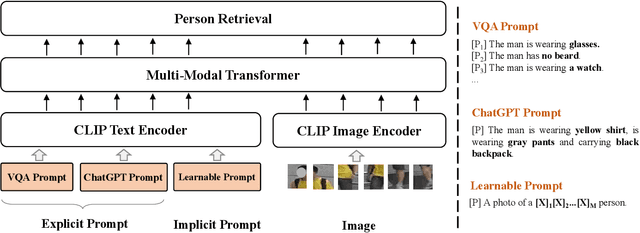

The fine-grained attribute descriptions can significantly supplement the valuable semantic information for person image, which is vital to the success of person re-identification (ReID) task. However, current ReID algorithms typically failed to effectively leverage the rich contextual information available, primarily due to their reliance on simplistic and coarse utilization of image attributes. Recent advances in artificial intelligence generated content have made it possible to automatically generate plentiful fine-grained attribute descriptions and make full use of them. Thereby, this paper explores the potential of using the generated multiple person attributes as prompts in ReID tasks with off-the-shelf (large) models for more accurate retrieval results. To this end, we present a new framework called Multi-Prompts ReID (MP-ReID), based on prompt learning and language models, to fully dip fine attributes to assist ReID task. Specifically, MP-ReID first learns to hallucinate diverse, informative, and promptable sentences for describing the query images. This procedure includes (i) explicit prompts of which attributes a person has and furthermore (ii) implicit learnable prompts for adjusting/conditioning the criteria used towards this person identity matching. Explicit prompts are obtained by ensembling generation models, such as ChatGPT and VQA models. Moreover, an alignment module is designed to fuse multi-prompts (i.e., explicit and implicit ones) progressively and mitigate the cross-modal gap. Extensive experiments on the existing attribute-involved ReID datasets, namely, Market1501 and DukeMTMC-reID, demonstrate the effectiveness and rationality of the proposed MP-ReID solution.
Uncovering Hidden Connections: Iterative Tracking and Reasoning for Video-grounded Dialog
Oct 11, 2023

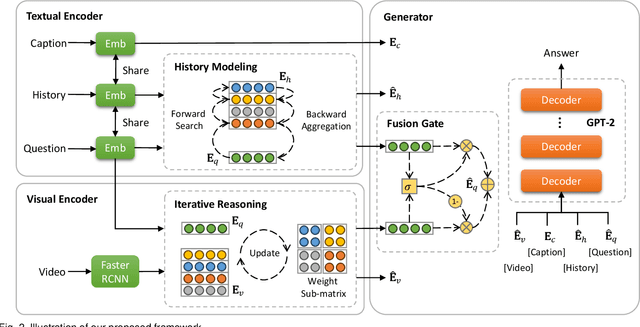

In contrast to conventional visual question answering, video-grounded dialog necessitates a profound understanding of both dialog history and video content for accurate response generation. Despite commendable strides made by existing methodologies, they often grapple with the challenges of incrementally understanding intricate dialog histories and assimilating video information. In response to this gap, we present an iterative tracking and reasoning strategy that amalgamates a textual encoder, a visual encoder, and a generator. At its core, our textual encoder is fortified with a path tracking and aggregation mechanism, adept at gleaning nuances from dialog history that are pivotal to deciphering the posed questions. Concurrently, our visual encoder harnesses an iterative reasoning network, meticulously crafted to distill and emphasize critical visual markers from videos, enhancing the depth of visual comprehension. Culminating this enriched information, we employ the pre-trained GPT-2 model as our response generator, stitching together coherent and contextually apt answers. Our empirical assessments, conducted on two renowned datasets, testify to the prowess and adaptability of our proposed design.
Recall and Learn: A Memory-augmented Solver for Math Word Problems
Sep 27, 2021
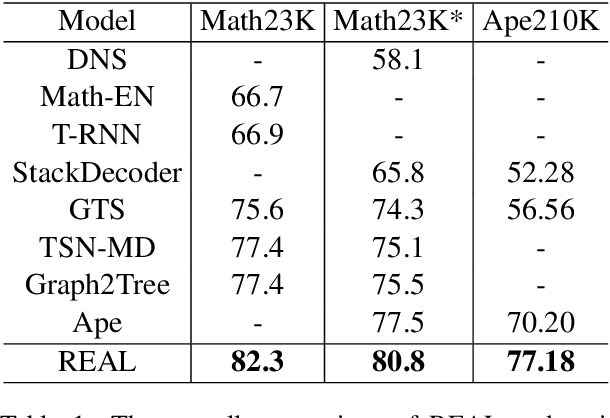
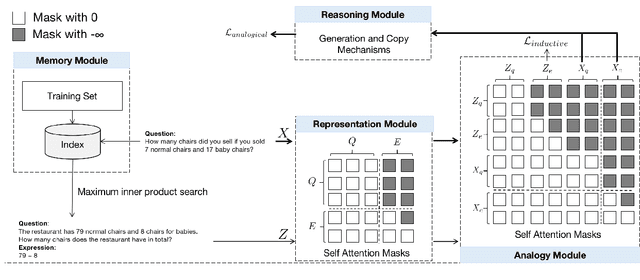

In this article, we tackle the math word problem, namely, automatically answering a mathematical problem according to its textual description. Although recent methods have demonstrated their promising results, most of these methods are based on template-based generation scheme which results in limited generalization capability. To this end, we propose a novel human-like analogical learning method in a recall and learn manner. Our proposed framework is composed of modules of memory, representation, analogy, and reasoning, which are designed to make a new exercise by referring to the exercises learned in the past. Specifically, given a math word problem, the model first retrieves similar questions by a memory module and then encodes the unsolved problem and each retrieved question using a representation module. Moreover, to solve the problem in a way of analogy, an analogy module and a reasoning module with a copy mechanism are proposed to model the interrelationship between the problem and each retrieved question. Extensive experiments on two well-known datasets show the superiority of our proposed algorithm as compared to other state-of-the-art competitors from both overall performance comparison and micro-scope studies.