 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamic Collaborative Network for Semi-supervised 3D Vessel Segmentation
Jan 12, 2026In this paper, we present a new dynamic collaborative network for semi-supervised 3D vessel segmentation, termed DiCo. Conventional mean teacher (MT) methods typically employ a static approach, where the roles of the teacher and student models are fixed. However, due to the complexity of 3D vessel data, the teacher model may not always outperform the student model, leading to cognitive biases that can limit performance. To address this issue, we propose a dynamic collaborative network that allows the two models to dynamically switch their teacher-student roles. Additionally, we introduce a multi-view integration module to capture various perspectives of the inputs, mirroring the way doctors conduct medical analysis. We also incorporate adversarial supervision to constrain the shape of the segmented vessels in unlabeled data. In this process, the 3D volume is projected into 2D views to mitigate the impact of label inconsistencies. Experiments demonstrate that our DiCo method sets new state-of-the-art performance on three 3D vessel segmentation benchmarks. The code repository address is https://github.com/xujiaommcome/DiCo
PulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
Hard Thresholding Pursuit Algorithms for Least Absolute Deviations Problem
Jan 10, 2026Least absolute deviations (LAD) is a statistical optimality criterion widely utilized in scenarios where a minority of measurements are contaminated by outliers of arbitrary magnitudes. In this paper, we delve into the robustness of the variant of adaptive iterative hard thresholding to outliers, known as graded fast hard thresholding pursuit (GFHTP$_1$) algorithm. Unlike the majority of the state-of-the-art algorithms in this field, GFHTP$_1$ does not require prior information about the signal's sparsity. Moreover, its design is parameterless, which not only simplifies the implementation process but also removes the intricacies of parameter optimization. Numerical experiments reveal that the GFHTP$_1$ algorithm consistently outperforms competing algorithms in terms of both robustness and computational efficiency.
Recall and Learn: A Memory-augmented Solver for Math Word Problems
Sep 27, 2021
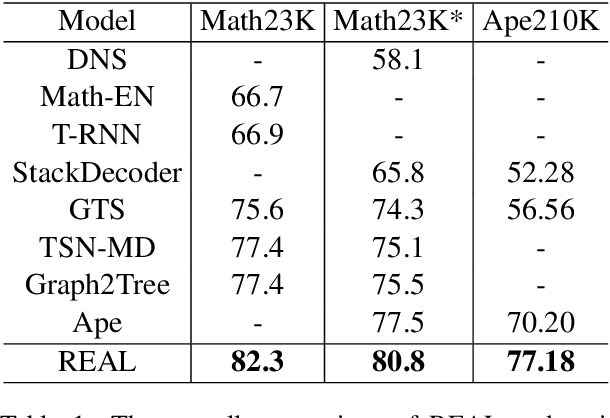
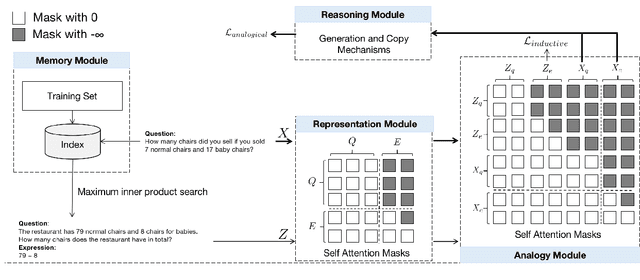

In this article, we tackle the math word problem, namely, automatically answering a mathematical problem according to its textual description. Although recent methods have demonstrated their promising results, most of these methods are based on template-based generation scheme which results in limited generalization capability. To this end, we propose a novel human-like analogical learning method in a recall and learn manner. Our proposed framework is composed of modules of memory, representation, analogy, and reasoning, which are designed to make a new exercise by referring to the exercises learned in the past. Specifically, given a math word problem, the model first retrieves similar questions by a memory module and then encodes the unsolved problem and each retrieved question using a representation module. Moreover, to solve the problem in a way of analogy, an analogy module and a reasoning module with a copy mechanism are proposed to model the interrelationship between the problem and each retrieved question. Extensive experiments on two well-known datasets show the superiority of our proposed algorithm as compared to other state-of-the-art competitors from both overall performance comparison and micro-scope studies.