 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeblur4DGS: 4D Gaussian Splatting from Blurry Monocular Video
Dec 09, 2024



Recent 4D reconstruction methods have yielded impressive results but rely on sharp videos as supervision. However, motion blur often occurs in videos due to camera shake and object movement, while existing methods render blurry results when using such videos for reconstructing 4D models. Although a few NeRF-based approaches attempted to address the problem, they struggled to produce high-quality results, due to the inaccuracy in estimating continuous dynamic representations within the exposure time. Encouraged by recent works in 3D motion trajectory modeling using 3D Gaussian Splatting (3DGS), we suggest taking 3DGS as the scene representation manner, and propose the first 4D Gaussian Splatting framework to reconstruct a high-quality 4D model from blurry monocular video, named Deblur4DGS. Specifically, we transform continuous dynamic representations estimation within an exposure time into the exposure time estimation. Moreover, we introduce exposure regularization to avoid trivial solutions, as well as multi-frame and multi-resolution consistency ones to alleviate artifacts. Furthermore, to better represent objects with large motion, we suggest blur-aware variable canonical Gaussians. Beyond novel-view synthesis, Deblur4DGS can be applied to improve blurry video from multiple perspectives, including deblurring, frame interpolation, and video stabilization. Extensive experiments on the above four tasks show that Deblur4DGS outperforms state-of-the-art 4D reconstruction methods. The codes are available at https://github.com/ZcsrenlongZ/Deblur4DGS.
NIR-Assisted Image Denoising: A Selective Fusion Approach and A Real-World Benchmark Datase
Apr 12, 2024Despite the significant progress in image denoising, it is still challenging to restore fine-scale details while removing noise, especially in extremely low-light environments. Leveraging near-infrared (NIR) images to assist visible RGB image denoising shows the potential to address this issue, becoming a promising technology. Nonetheless, existing works still struggle with taking advantage of NIR information effectively for real-world image denoising, due to the content inconsistency between NIR-RGB images and the scarcity of real-world paired datasets. To alleviate the problem, we propose an efficient Selective Fusion Module (SFM), which can be plug-and-played into the advanced denoising networks to merge the deep NIR-RGB features. Specifically, we sequentially perform the global and local modulation for NIR and RGB features, and then integrate the two modulated features. Furthermore, we present a Real-world NIR-Assisted Image Denoising (Real-NAID) dataset, which covers diverse scenarios as well as various noise levels. Extensive experiments on both synthetic and our real-world datasets demonstrate that the proposed method achieves better results than state-of-the-art ones. The dataset, codes, and pre-trained models will be publicly available at https://github.com/ronjonxu/NAID.
Dual-Camera Smooth Zoom on Mobile Phones
Apr 07, 2024When zooming between dual cameras on a mobile, noticeable jumps in geometric content and image color occur in the preview, inevitably affecting the user's zoom experience. In this work, we introduce a new task, ie, dual-camera smooth zoom (DCSZ) to achieve a smooth zoom preview. The frame interpolation (FI) technique is a potential solution but struggles with ground-truth collection. To address the issue, we suggest a data factory solution where continuous virtual cameras are assembled to generate DCSZ data by rendering reconstructed 3D models of the scene. In particular, we propose a novel dual-camera smooth zoom Gaussian Splatting (ZoomGS), where a camera-specific encoding is introduced to construct a specific 3D model for each virtual camera. With the proposed data factory, we construct a synthetic dataset for DCSZ, and we utilize it to fine-tune FI models. In addition, we collect real-world dual-zoom images without ground-truth for evaluation. Extensive experiments are conducted with multiple FI methods. The results show that the fine-tuned FI models achieve a significant performance improvement over the original ones on DCSZ task. The datasets, codes, and pre-trained models will be publicly available.
Self-Supervised Video Desmoking for Laparoscopic Surgery
Mar 17, 2024Due to the difficulty of collecting real paired data, most existing desmoking methods train the models by synthesizing smoke, generalizing poorly to real surgical scenarios. Although a few works have explored single-image real-world desmoking in unpaired learning manners, they still encounter challenges in handling dense smoke. In this work, we address these issues together by introducing the self-supervised surgery video desmoking (SelfSVD). On the one hand, we observe that the frame captured before the activation of high-energy devices is generally clear (named pre-smoke frame, PS frame), thus it can serve as supervision for other smoky frames, making real-world self-supervised video desmoking practically feasible. On the other hand, in order to enhance the desmoking performance, we further feed the valuable information from PS frame into models, where a masking strategy and a regularization term are presented to avoid trivial solutions. In addition, we construct a real surgery video dataset for desmoking, which covers a variety of smoky scenes. Extensive experiments on the dataset show that our SelfSVD can remove smoke more effectively and efficiently while recovering more photo-realistic details than the state-of-the-art methods. The dataset, codes, and pre-trained models are available at \url{https://github.com/ZcsrenlongZ/SelfSVD}.
Bracketing is All You Need: Unifying Image Restoration and Enhancement Tasks with Multi-Exposure Images
Jan 01, 2024



It is challenging but highly desired to acquire high-quality photos with clear content in low-light environments. Although multi-image processing methods (using burst, dual-exposure, or multi-exposure images) have made significant progress in addressing this issue, they typically focus exclusively on specific restoration or enhancement tasks, being insufficient in exploiting multi-image. Motivated by that multi-exposure images are complementary in denoising, deblurring, high dynamic range imaging, and super-resolution, we propose to utilize bracketing photography to unify restoration and enhancement tasks in this work. Due to the difficulty in collecting real-world pairs, we suggest a solution that first pre-trains the model with synthetic paired data and then adapts it to real-world unlabeled images. In particular, a temporally modulated recurrent network (TMRNet) and self-supervised adaptation method are proposed. Moreover, we construct a data simulation pipeline to synthesize pairs and collect real-world images from 200 nighttime scenarios. Experiments on both datasets show that our method performs favorably against the state-of-the-art multi-image processing ones. The dataset, code, and pre-trained models are available at https://github.com/cszhilu1998/BracketIRE.
RBSR: Efficient and Flexible Recurrent Network for Burst Super-Resolution
Jun 30, 2023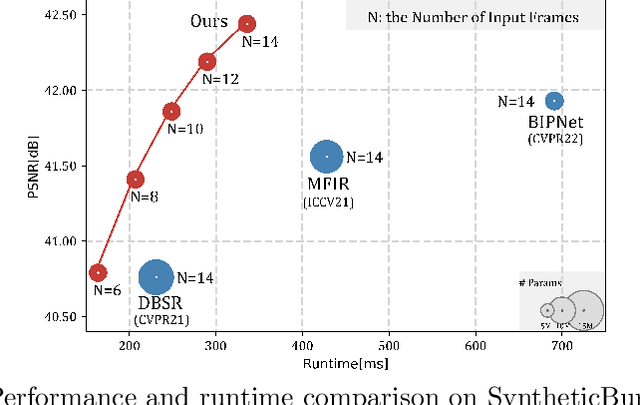
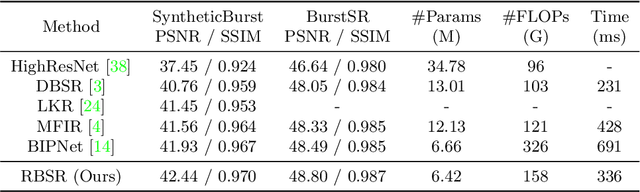
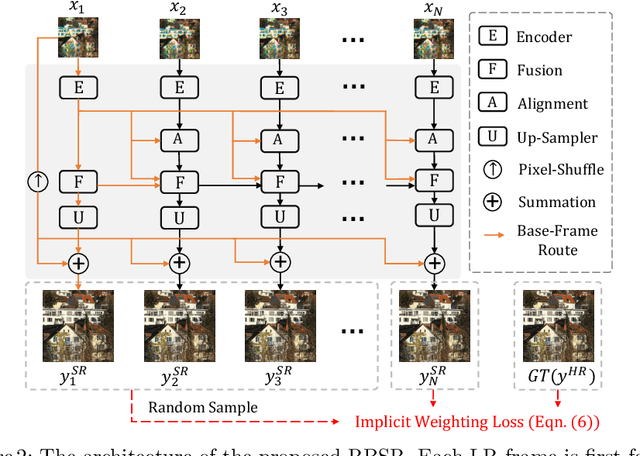

Burst super-resolution (BurstSR) aims at reconstructing a high-resolution (HR) image from a sequence of low-resolution (LR) and noisy images, which is conducive to enhancing the imaging effects of smartphones with limited sensors. The main challenge of BurstSR is to effectively combine the complementary information from input frames, while existing methods still struggle with it. In this paper, we suggest fusing cues frame-by-frame with an efficient and flexible recurrent network. In particular, we emphasize the role of the base-frame and utilize it as a key prompt to guide the knowledge acquisition from other frames in every recurrence. Moreover, we introduce an implicit weighting loss to improve the model's flexibility in facing input frames with variable numbers. Extensive experiments on both synthetic and real-world datasets demonstrate that our method achieves better results than state-of-the-art ones. Codes and pre-trained models are available at https://github.com/ZcsrenlongZ/RBSR.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022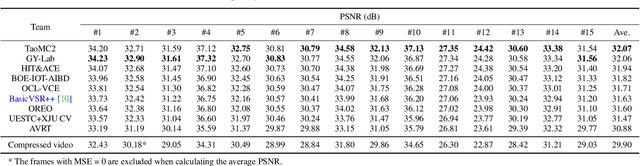
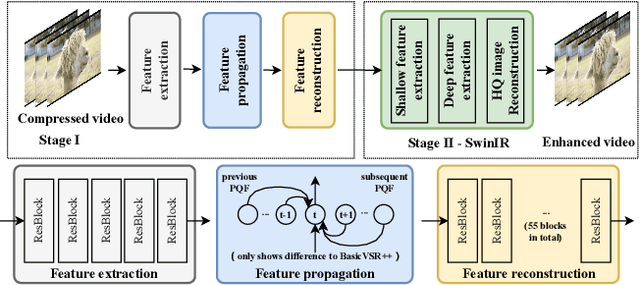
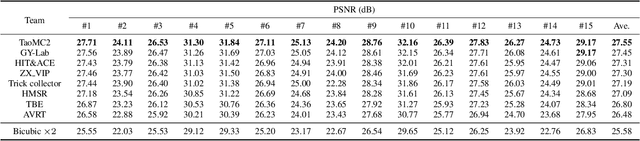

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.