 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DEVIL is in the Details: A Diagnostic Evaluation Benchmark for Video Inpainting
May 11, 2021


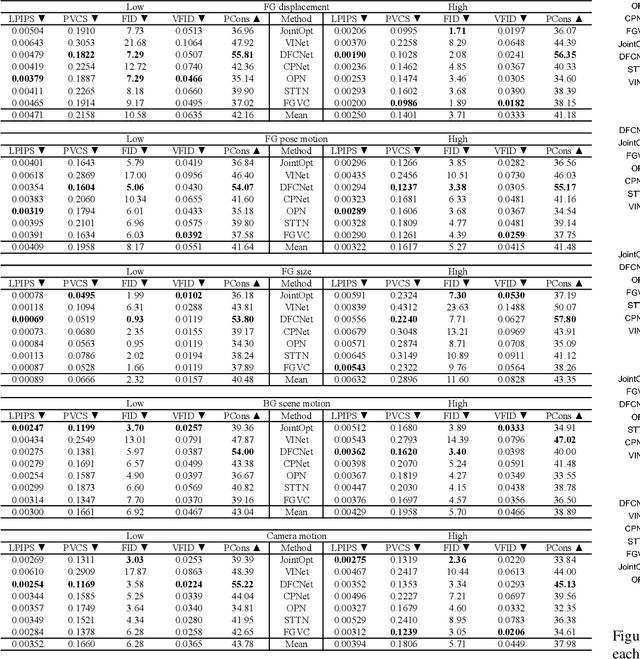
Quantitative evaluation has increased dramatically among recent video inpainting work, but the video and mask content used to gauge performance has received relatively little attention. Although attributes such as camera and background scene motion inherently change the difficulty of the task and affect methods differently, existing evaluation schemes fail to control for them, thereby providing minimal insight into inpainting failure modes. To address this gap, we propose the Diagnostic Evaluation of Video Inpainting on Landscapes (DEVIL) benchmark, which consists of two contributions: (i) a novel dataset of videos and masks labeled according to several key inpainting failure modes, and (ii) an evaluation scheme that samples slices of the dataset characterized by a fixed content attribute, and scores performance on each slice according to reconstruction, realism, and temporal consistency quality. By revealing systematic changes in performance induced by particular characteristics of the input content, our challenging benchmark enables more insightful analysis into video inpainting methods and serves as an invaluable diagnostic tool for the field. Our code is available at https://github.com/MichiganCOG/devil .
HyperCon: Image-To-Video Model Transfer for Video-To-Video Translation Tasks
Dec 10, 2019
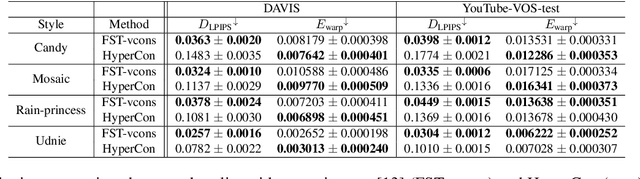
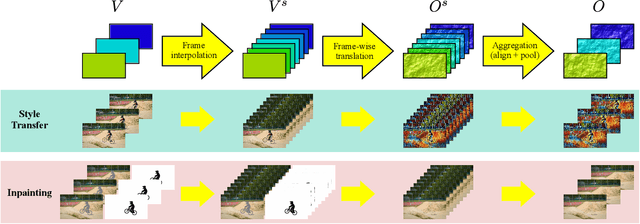

Video-to-video translation for super-resolution, inpainting, style transfer, etc. is more difficult than corresponding image-to-image translation tasks due to the temporal consistency problem that, if left unaddressed, results in distracting flickering effects. Although video models designed from scratch produce temporally consistent results, training them to match the vast visual knowledge captured by image models requires an intractable number of videos. To combine the benefits of image and video models, we propose an image-to-video model transfer method called Hyperconsistency (HyperCon) that transforms any well-trained image model into a temporally consistent video model without fine-tuning. HyperCon works by translating a synthetic temporally interpolated video frame-wise and then aggregating over temporally localized windows on the interpolated video. It handles both masked and unmasked inputs, enabling support for even more video-to-video tasks than prior image-to-video model transfer techniques. We demonstrate HyperCon on video style transfer and inpainting, where it performs favorably compared to prior state-of-the-art video consistency and video inpainting methods, all without training on a single stylized or incomplete video.
A Temporally-Aware Interpolation Network for Video Frame Inpainting
Nov 03, 2018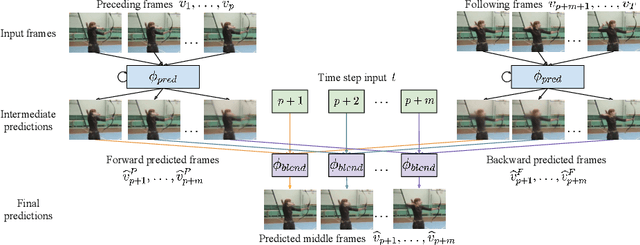
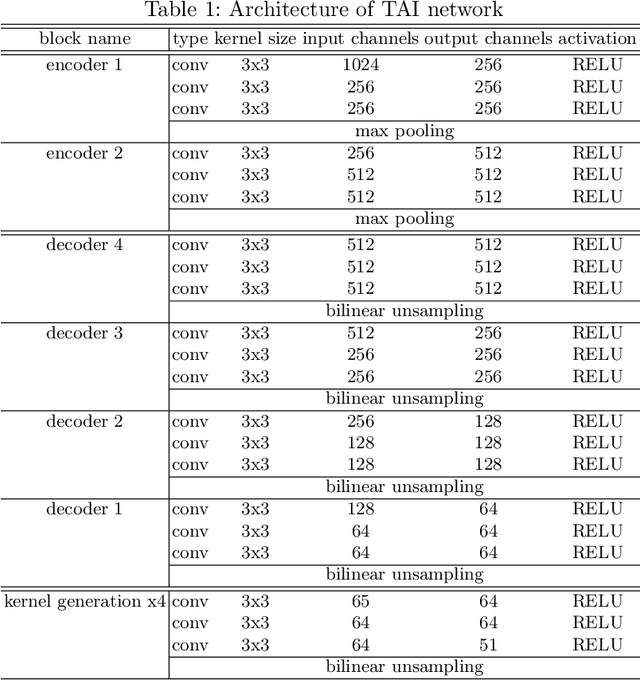
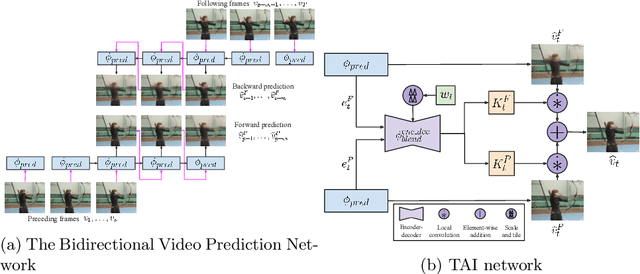
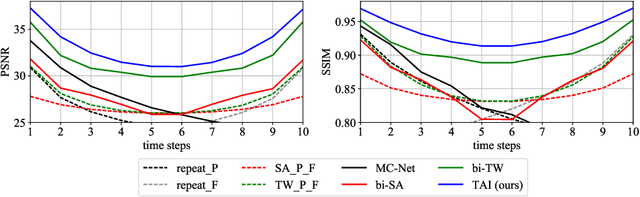
We propose the first deep learning solution to video frame inpainting, a challenging instance of the general video inpainting problem with applications in video editing, manipulation, and forensics. Our task is less ambiguous than frame interpolation and video prediction because we have access to both the temporal context and a partial glimpse of the future, allowing us to better evaluate the quality of a model's predictions objectively. We devise a pipeline composed of two modules: a bidirectional video prediction module, and a temporally-aware frame interpolation module. The prediction module makes two intermediate predictions of the missing frames, one conditioned on the preceding frames and the other conditioned on the following frames, using a shared convolutional LSTM-based encoder-decoder. The interpolation module blends the intermediate predictions to form the final result. Specifically, it utilizes time information and hidden activations from the video prediction module to resolve disagreements between the predictions. Our experiments demonstrate that our approach produces more accurate and qualitatively satisfying results than a state-of-the-art video prediction method and many strong frame inpainting baselines.
A Dataset To Evaluate The Representations Learned By Video Prediction Models
Mar 22, 2018


We present a parameterized synthetic dataset called Moving Symbols to support the objective study of video prediction networks. Using several instantiations of the dataset in which variation is explicitly controlled, we highlight issues in an existing state-of-the-art approach and propose the use of a performance metric with greater semantic meaning to improve experimental interpretability. Our dataset provides canonical test cases that will help the community better understand, and eventually improve, the representations learned by such networks in the future. Code is available at https://github.com/rszeto/moving-symbols .
Click Here: Human-Localized Keypoints as Guidance for Viewpoint Estimation
Aug 04, 2017
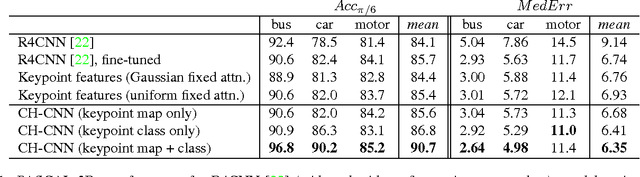
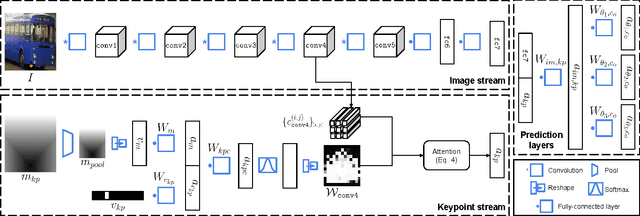

We motivate and address a human-in-the-loop variant of the monocular viewpoint estimation task in which the location and class of one semantic object keypoint is available at test time. In order to leverage the keypoint information, we devise a Convolutional Neural Network called Click-Here CNN (CH-CNN) that integrates the keypoint information with activations from the layers that process the image. It transforms the keypoint information into a 2D map that can be used to weigh features from certain parts of the image more heavily. The weighted sum of these spatial features is combined with global image features to provide relevant information to the prediction layers. To train our network, we collect a novel dataset of 3D keypoint annotations on thousands of CAD models, and synthetically render millions of images with 2D keypoint information. On test instances from PASCAL 3D+, our model achieves a mean class accuracy of 90.7%, whereas the state-of-the-art baseline only obtains 85.7% mean class accuracy, justifying our argument for human-in-the-loop inference.