 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCon: Image-To-Video Model Transfer for Video-To-Video Translation Tasks
Paper and Code
Dec 10, 2019
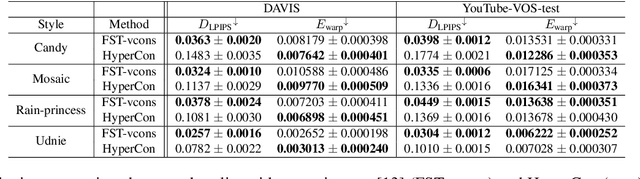
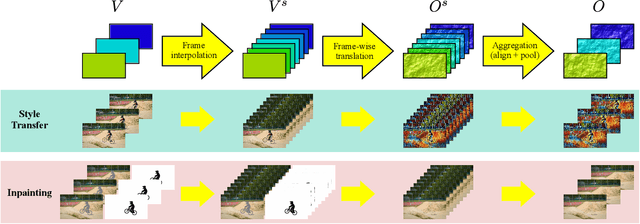

Video-to-video translation for super-resolution, inpainting, style transfer, etc. is more difficult than corresponding image-to-image translation tasks due to the temporal consistency problem that, if left unaddressed, results in distracting flickering effects. Although video models designed from scratch produce temporally consistent results, training them to match the vast visual knowledge captured by image models requires an intractable number of videos. To combine the benefits of image and video models, we propose an image-to-video model transfer method called Hyperconsistency (HyperCon) that transforms any well-trained image model into a temporally consistent video model without fine-tuning. HyperCon works by translating a synthetic temporally interpolated video frame-wise and then aggregating over temporally localized windows on the interpolated video. It handles both masked and unmasked inputs, enabling support for even more video-to-video tasks than prior image-to-video model transfer techniques. We demonstrate HyperCon on video style transfer and inpainting, where it performs favorably compared to prior state-of-the-art video consistency and video inpainting methods, all without training on a single stylized or incomplete video.