 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxDropoutV2: An Improved Method to Drop out Neurons in Convolutional Neural Networks
Paper and Code
Mar 05, 2022
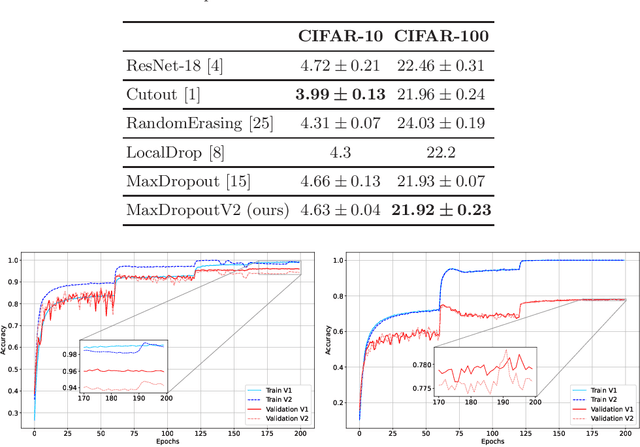
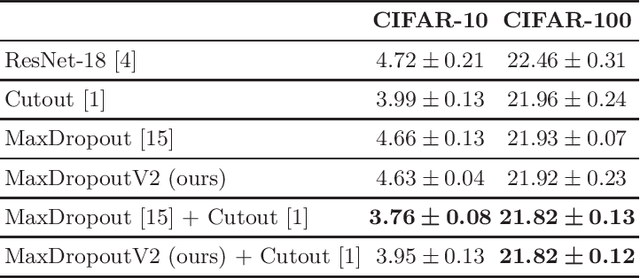

In the last decade, exponential data growth supplied the machine learning-based algorithms' capacity and enabled their usage in daily life activities. Additionally, such an improvement is partially explained due to the advent of deep learning techniques, i.e., stacks of simple architectures that end up in more complex models. Although both factors produce outstanding results, they also pose drawbacks regarding the learning process since training complex models denotes an expensive task and results are prone to overfit the training data. A supervised regularization technique called MaxDropout was recently proposed to tackle the latter, providing several improvements concerning traditional regularization approaches. In this paper, we present its improved version called MaxDropoutV2. Results considering two public datasets show that the model performs faster than the standard version and, in most cases, provides more accurate results.