 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the main failure scenarios of subsea blowout preventers systems: An approach through Latent Semantic Analysis
Jan 02, 2023The blowout preventer (BOP) system is one of the most important well safety barriers during the drilling phase because it can prevent the development of blowout events. This paper investigates BOP system's main failures using an LSA-based methodology. A total of 1312 failure records from companies worldwide were collected from the International Association of Drilling Contractors' RAPID-S53 database. The database contains recordings of halted drilling operations due to BOP system's failures and component's function deviations. The main failure scenarios of the components annular preventer, shear rams preventer, compensated chamber solenoid valve, and hydraulic regulators were identified using the proposed methodology. The scenarios contained valuable information about corrective maintenance procedures, such as frequently observed failure modes, detection methods used, suspected causes, and corrective actions. The findings highlighted that the major failures of the components under consideration were leakages caused by damaged elastomeric seals. The majority of the failures were detected during function and pressure tests with the BOP system in the rig. This study provides an alternative safety analysis that contributes to understanding blowout preventer system's critical component failures by applying a methodology based on a well-established text mining technique and analyzing failure records from an international database.
Scene Change Detection Using Multiscale Cascade Residual Convolutional Neural Networks
Dec 20, 2022



Scene change detection is an image processing problem related to partitioning pixels of a digital image into foreground and background regions. Mostly, visual knowledge-based computer intelligent systems, like traffic monitoring, video surveillance, and anomaly detection, need to use change detection techniques. Amongst the most prominent detection methods, there are the learning-based ones, which besides sharing similar training and testing protocols, differ from each other in terms of their architecture design strategies. Such architecture design directly impacts on the quality of the detection results, and also in the device resources capacity, like memory. In this work, we propose a novel Multiscale Cascade Residual Convolutional Neural Network that integrates multiscale processing strategy through a Residual Processing Module, with a Segmentation Convolutional Neural Network. Experiments conducted on two different datasets support the effectiveness of the proposed approach, achieving average overall $\boldsymbol{F\text{-}measure}$ results of $\boldsymbol{0.9622}$ and $\boldsymbol{0.9664}$ over Change Detection 2014 and PetrobrasROUTES datasets respectively, besides comprising approximately eight times fewer parameters. Such obtained results place the proposed technique amongst the top four state-of-the-art scene change detection methods.
Video Segmentation Learning Using Cascade Residual Convolutional Neural Network
Dec 20, 2022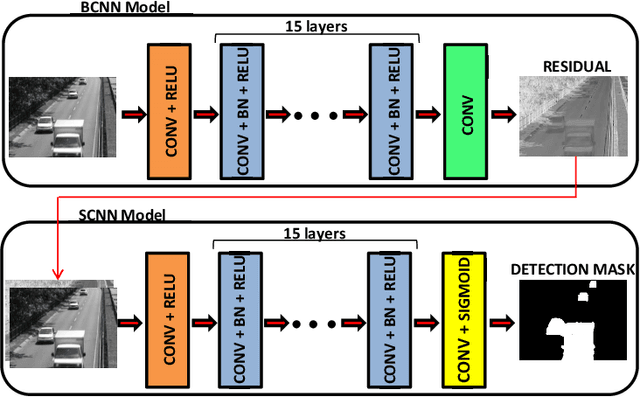

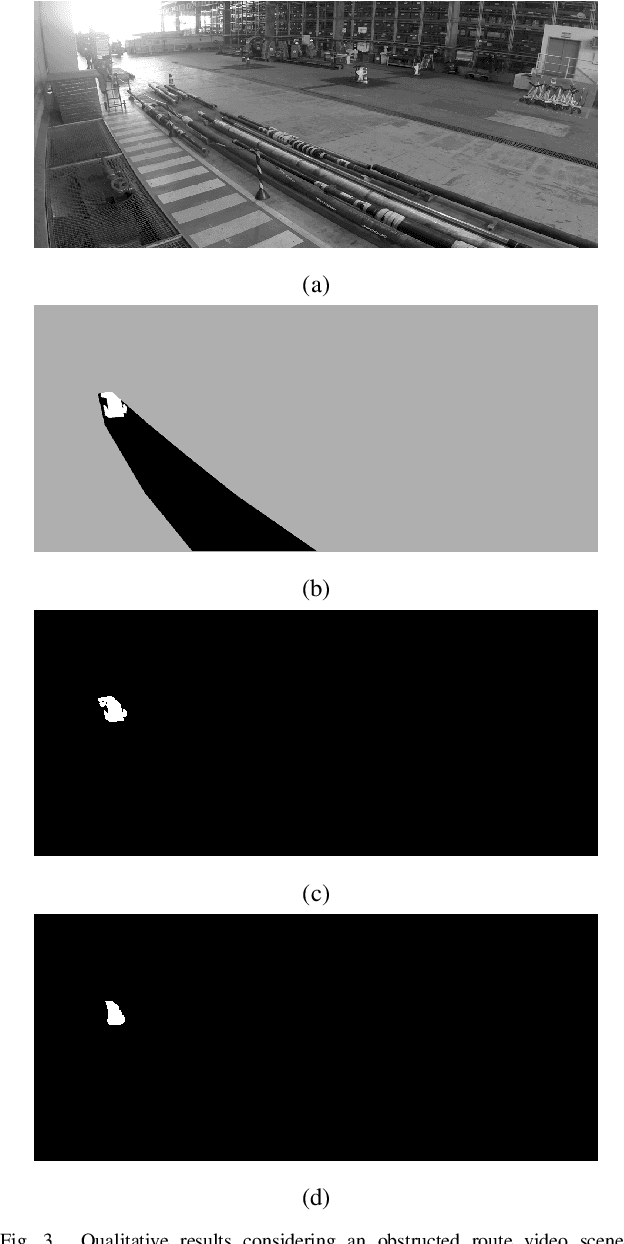

Video segmentation consists of a frame-by-frame selection process of meaningful areas related to foreground moving objects. Some applications include traffic monitoring, human tracking, action recognition, efficient video surveillance, and anomaly detection. In these applications, it is not rare to face challenges such as abrupt changes in weather conditions, illumination issues, shadows, subtle dynamic background motions, and also camouflage effects. In this work, we address such shortcomings by proposing a novel deep learning video segmentation approach that incorporates residual information into the foreground detection learning process. The main goal is to provide a method capable of generating an accurate foreground detection given a grayscale video. Experiments conducted on the Change Detection 2014 and on the private dataset PetrobrasROUTES from Petrobras support the effectiveness of the proposed approach concerning some state-of-the-art video segmentation techniques, with overall F-measures of $\mathbf{0.9535}$ and $\mathbf{0.9636}$ in the Change Detection 2014 and PetrobrasROUTES datasets, respectively. Such a result places the proposed technique amongst the top 3 state-of-the-art video segmentation methods, besides comprising approximately seven times less parameters than its top one counterpart.
A Review of Deep Learning-based Approaches for Deepfake Content Detection
Feb 12, 2022The fast-spreading information over the internet is essential to support the rapid supply of numerous public utility services and entertainment to users. Social networks and online media paved the way for modern, timely-communication-fashion and convenient access to all types of information. However, it also provides new chances for ill use of the massive amount of available data, such as spreading fake content to manipulate public opinion. Detection of counterfeit content has raised attention in the last few years for the advances in deepfake generation. The rapid growth of machine learning techniques, particularly deep learning, can predict fake content in several application domains, including fake image and video manipulation. This paper presents a comprehensive review of recent studies for deepfake content detection using deep learning-based approaches. We aim to broaden the state-of-the-art research by systematically reviewing the different categories of fake content detection. Furthermore, we report the advantages and drawbacks of the examined works and future directions towards the issues and shortcomings still unsolved on deepfake detection.
Gait Recognition Based on Deep Learning: A Survey
Jan 10, 2022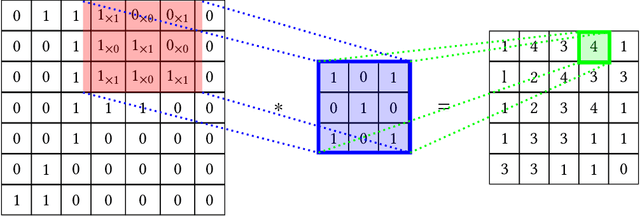
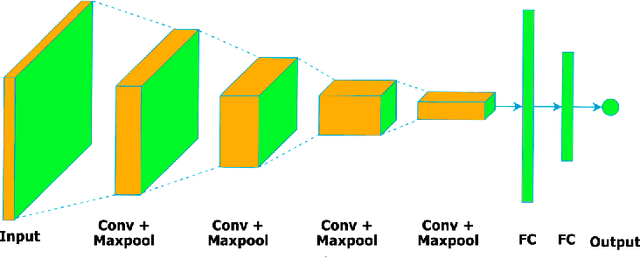
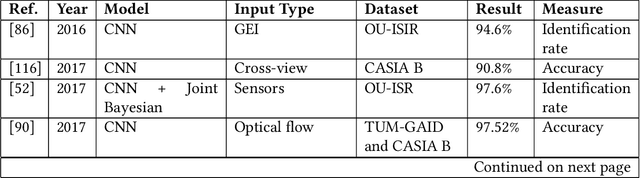
In general, biometry-based control systems may not rely on individual expected behavior or cooperation to operate appropriately. Instead, such systems should be aware of malicious procedures for unauthorized access attempts. Some works available in the literature suggest addressing the problem through gait recognition approaches. Such methods aim at identifying human beings through intrinsic perceptible features, despite dressed clothes or accessories. Although the issue denotes a relatively long-time challenge, most of the techniques developed to handle the problem present several drawbacks related to feature extraction and low classification rates, among other issues. However, deep learning-based approaches recently emerged as a robust set of tools to deal with virtually any image and computer-vision related problem, providing paramount results for gait recognition as well. Therefore, this work provides a surveyed compilation of recent works regarding biometric detection through gait recognition with a focus on deep learning approaches, emphasizing their benefits, and exposing their weaknesses. Besides, it also presents categorized and characterized descriptions of the datasets, approaches, and architectures employed to tackle associated constraints.
Information Ranking Using Optimum-Path Forest
Feb 16, 2021
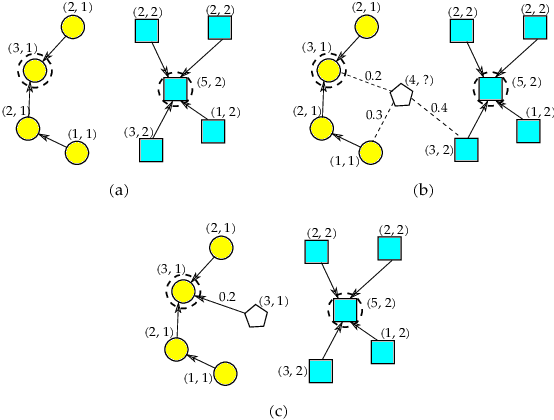


The task of learning to rank has been widely studied by the machine learning community, mainly due to its use and great importance in information retrieval, data mining, and natural language processing. Therefore, ranking accurately and learning to rank are crucial tasks. Context-Based Information Retrieval systems have been of great importance to reduce the effort of finding relevant data. Such systems have evolved by using machine learning techniques to improve their results, but they are mainly dependent on user feedback. Although information retrieval has been addressed in different works along with classifiers based on Optimum-Path Forest (OPF), these have so far not been applied to the learning to rank task. Therefore, the main contribution of this work is to evaluate classifiers based on Optimum-Path Forest, in such a context. Experiments were performed considering the image retrieval and ranking scenarios, and the performance of OPF-based approaches was compared to the well-known SVM-Rank pairwise technique and a baseline based on distance calculation. The experiments showed competitive results concerning precision and outperformed traditional techniques in terms of computational load.
MaxDropout: Deep Neural Network Regularization Based on Maximum Output Values
Jul 27, 2020

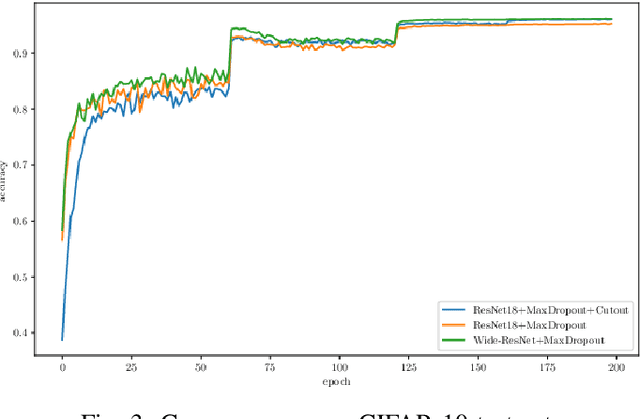
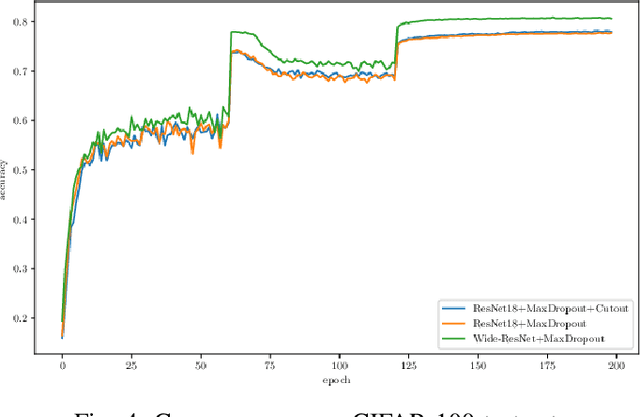
Different techniques have emerged in the deep learning scenario, such as Convolutional Neural Networks, Deep Belief Networks, and Long Short-Term Memory Networks, to cite a few. In lockstep, regularization methods, which aim to prevent overfitting by penalizing the weight connections, or turning off some units, have been widely studied either. In this paper, we present a novel approach called MaxDropout, a regularizer for deep neural network models that works in a supervised fashion by removing (shutting off) the prominent neurons (i.e., most active) in each hidden layer. The model forces fewer activated units to learn more representative information, thus providing sparsity. Regarding the experiments, we show that it is possible to improve existing neural networks and provide better results in neural networks when Dropout is replaced by MaxDropout. The proposed method was evaluated in image classification, achieving comparable results to existing regularizers, such as Cutout and RandomErasing, also improving the accuracy of neural networks that uses Dropout by replacing the existing layer by MaxDropout.