 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised classification of dental conditions in panoramic radiographs using large language model and instance segmentation: A real-world dataset evaluation
Jun 25, 2024



Dental panoramic radiographs offer vast diagnostic opportunities, but training supervised deep learning networks for automatic analysis of those radiology images is hampered by a shortage of labeled data. Here, a different perspective on this problem is introduced. A semi-supervised learning framework is proposed to classify thirteen dental conditions on panoramic radiographs, with a particular emphasis on teeth. Large language models were explored to annotate the most common dental conditions based on dental reports. Additionally, a masked autoencoder was employed to pre-train the classification neural network, and a Vision Transformer was used to leverage the unlabeled data. The analyses were validated using two of the most extensive datasets in the literature, comprising 8,795 panoramic radiographs and 8,029 paired reports and images. Encouragingly, the results consistently met or surpassed the baseline metrics for the Matthews correlation coefficient. A comparison of the proposed solution with human practitioners, supported by statistical analysis, highlighted its effectiveness and performance limitations; based on the degree of agreement among specialists, the solution demonstrated an accuracy level comparable to that of a junior specialist.
OdontoAI: A human-in-the-loop labeled data set and an online platform to boost research on dental panoramic radiographs
Mar 29, 2022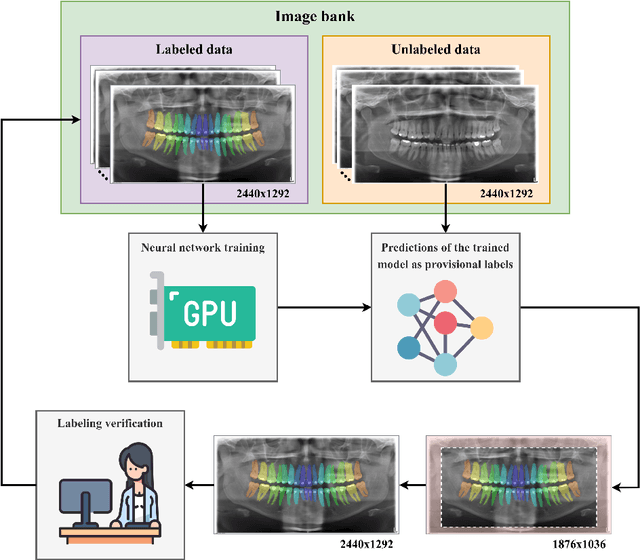

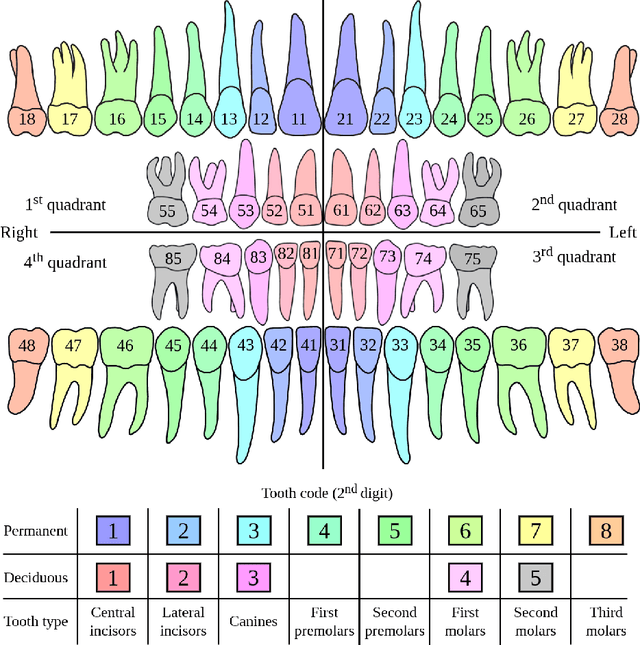

Deep learning has remarkably advanced in the last few years, supported by large labeled data sets. These data sets are precious yet scarce because of the time-consuming labeling procedures, discouraging researchers from producing them. This scarcity is especially true in dentistry, where deep learning applications are still in an embryonic stage. Motivated by this background, we address in this study the construction of a public data set of dental panoramic radiographs. Our objects of interest are the teeth, which are segmented and numbered, as they are the primary targets for dentists when screening a panoramic radiograph. We benefited from the human-in-the-loop (HITL) concept to expedite the labeling procedure, using predictions from deep neural networks as provisional labels, later verified by human annotators. All the gathering and labeling procedures of this novel data set is thoroughly analyzed. The results were consistent and behaved as expected: At each HITL iteration, the model predictions improved. Our results demonstrated a 51% labeling time reduction using HITL, saving us more than 390 continuous working hours. In a novel online platform, called OdontoAI, created to work as task central for this novel data set, we released 4,000 images, from which 2,000 have their labels publicly available for model fitting. The labels of the other 2,000 images are private and used for model evaluation considering instance and semantic segmentation and numbering. To the best of our knowledge, this is the largest-scale publicly available data set for panoramic radiographs, and the OdontoAI is the first platform of its kind in dentistry.
Attention-based fusion of semantic boundary and non-boundary information to improve semantic segmentation
Aug 05, 2021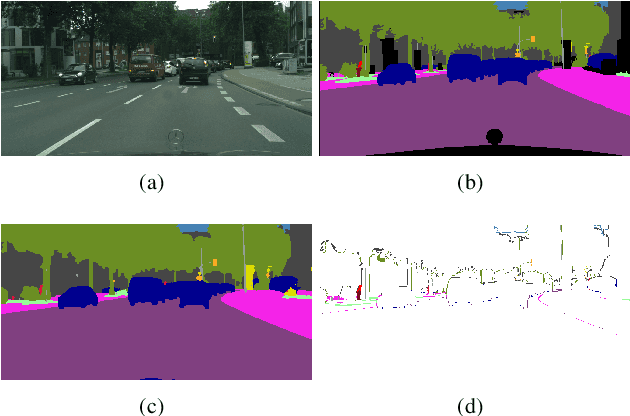
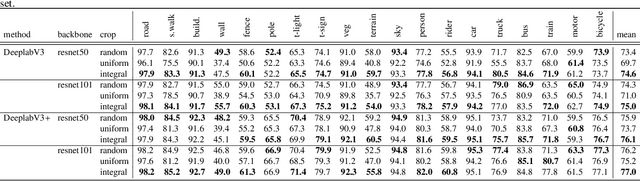
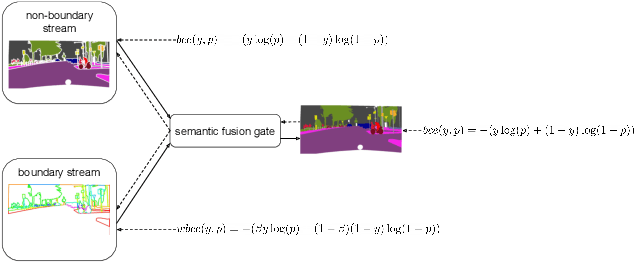

This paper introduces a method for image semantic segmentation grounded on a novel fusion scheme, which takes place inside a deep convolutional neural network. The main goal of our proposal is to explore object boundary information to improve the overall segmentation performance. Unlike previous works that combine boundary and segmentation features, or those that use boundary information to regularize semantic segmentation, we instead propose a novel approach that embodies boundary information onto segmentation. For that, our semantic segmentation method uses two streams, which are combined through an attention gate, forming an end-to-end Y-model. To the best of our knowledge, ours is the first work to show that boundary detection can improve semantic segmentation when fused through a semantic fusion gate (attention model). We performed an extensive evaluation of our method over public data sets. We found competitive results on all data sets after comparing our proposed model with other twelve state-of-the-art segmenters, considering the same training conditions. Our proposed model achieved the best mIoU on the CityScapes, CamVid, and Pascal Context data sets, and the second best on Mapillary Vistas.
Information Ranking Using Optimum-Path Forest
Feb 16, 2021


The task of learning to rank has been widely studied by the machine learning community, mainly due to its use and great importance in information retrieval, data mining, and natural language processing. Therefore, ranking accurately and learning to rank are crucial tasks. Context-Based Information Retrieval systems have been of great importance to reduce the effort of finding relevant data. Such systems have evolved by using machine learning techniques to improve their results, but they are mainly dependent on user feedback. Although information retrieval has been addressed in different works along with classifiers based on Optimum-Path Forest (OPF), these have so far not been applied to the learning to rank task. Therefore, the main contribution of this work is to evaluate classifiers based on Optimum-Path Forest, in such a context. Experiments were performed considering the image retrieval and ranking scenarios, and the performance of OPF-based approaches was compared to the well-known SVM-Rank pairwise technique and a baseline based on distance calculation. The experiments showed competitive results concerning precision and outperformed traditional techniques in terms of computational load.
On estimating gaze by self-attention augmented convolutions
Aug 25, 2020
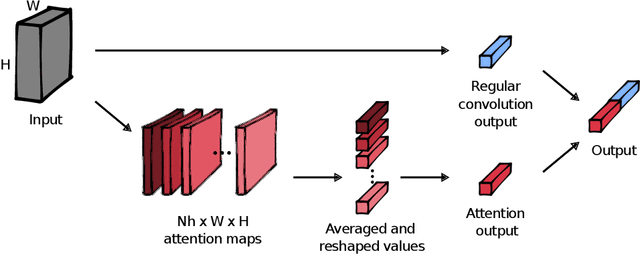
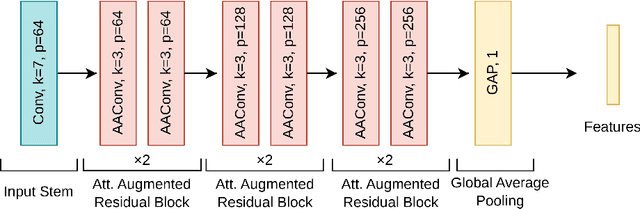
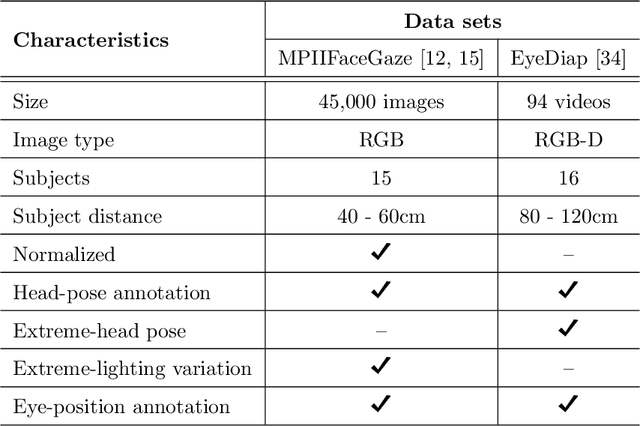
Estimation of 3D gaze is highly relevant to multiple fields, including but not limited to interactive systems, specialized human-computer interfaces, and behavioral research. Although recently deep learning methods have boosted the accuracy of appearance-based gaze estimation, there is still room for improvement in the network architectures for this particular task. Therefore we propose here a novel network architecture grounded on self-attention augmented convolutions to improve the quality of the learned features during the training of a shallower residual network. The rationale is that self-attention mechanism can help outperform deeper architectures by learning dependencies between distant regions in full-face images. This mechanism can also create better and more spatially-aware feature representations derived from the face and eye images before gaze regression. We dubbed our framework ARes-gaze, which explores our Attention-augmented ResNet (ARes-14) as twin convolutional backbones. In our experiments, results showed a decrease of the average angular error by 2.38% when compared to state-of-the-art methods on the MPIIFaceGaze data set, and a second-place on the EyeDiap data set. It is noteworthy that our proposed framework was the only one to reach high accuracy simultaneously on both data sets.
A rasterized ray-tracer pipeline for real-time, multi-device sonar simulation
Jan 08, 2020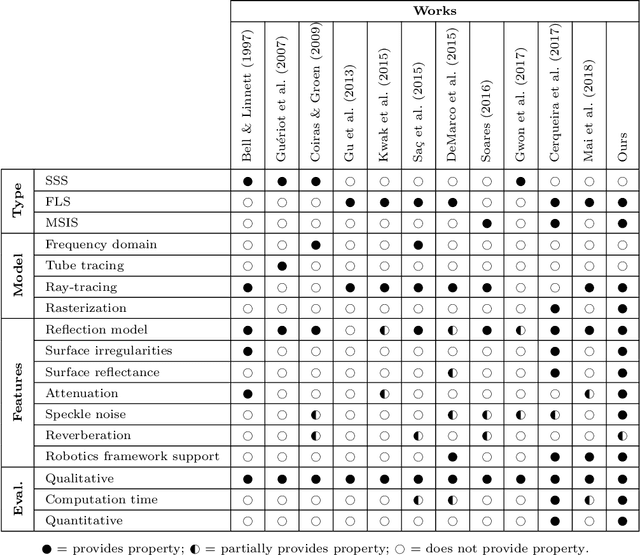

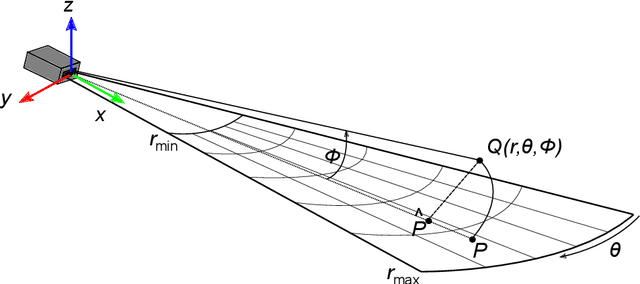

Simulating sonar devices requires modeling complex underwater acoustics, simultaneously rendering time-efficient data. Existing methods focus on basic implementation of one sonar type, where most of sound properties are disregarded. In this context, this work presents a multi-device sonar simulator capable of processing an underwater scene by a hybrid pipeline on GPU: Rasterization computes the primary intersections, while only the reflective areas are ray-traced. Our proposed system launches few rays when compared to a full ray-tracing based method, achieving a significant performance gain without quality loss in the final rendering. Resulting reflections are then characterized as two sonar parameters: Echo intensity and pulse distance. Underwater acoustic features, such as speckle noise, transmission loss, reverberation and material properties of observable objects are also computed in the final generated acoustic image. Visual and numerical performance assessments demonstrated the effectiveness of the proposed simulator to render underwater scenes in comparison to real-world sonar devices.
Rotation-invariant shipwreck recognition with forward-looking sonar
Oct 11, 2019


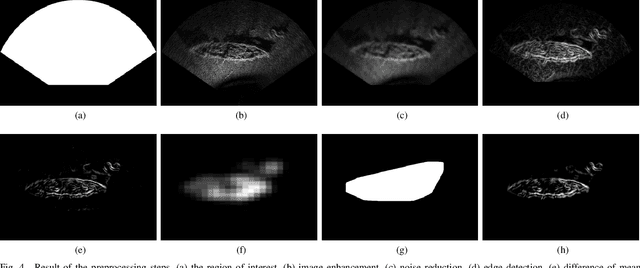
Under the sea, visible spectrum cameras have limited sensing capacity, being able to detect objects only in clear water, but in a constrained range. Considering any sea water condition, sonars are more suitable to support autonomous underwater vehicles' navigation, even in turbid condition. Despite that sonar suitability, this type of sensor does not provide high-density information, such as optical sensors, making the process of object recognition to be more complex. To deal with that problem, we propose a novel trainable method to detect and recognize (identify) specific target objects under the sea with a forward-looking sonar. Our method has a preprocessing step in charge of strongly reducing the sensor noise and seabed background. To represent the object, our proposed method uses histogram of orientation gradient (HOG) as feature extractor. HOG ultimately feed a multi-scale oriented detector combined with a support vector machine to recognize specific trained objects in a rotation-invariant way. Performance assessment demonstrated promising results, favoring the method to be applied in underwater remote sensing.
Classification of glomerular hypercellularity using convolutional features and support vector machine
Jun 28, 2019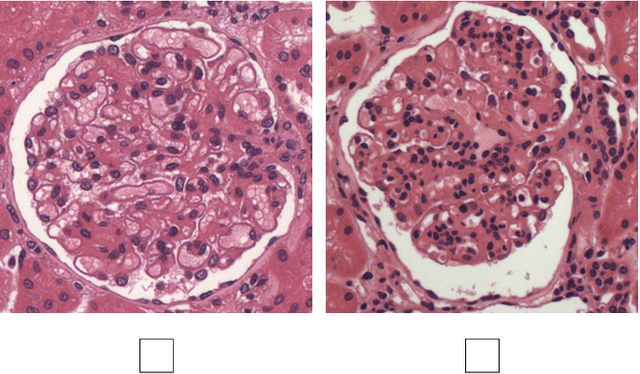
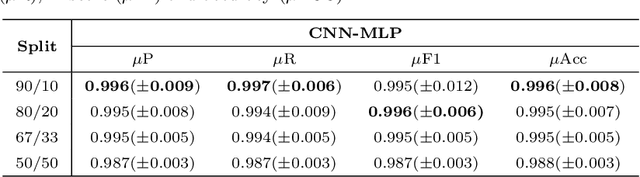
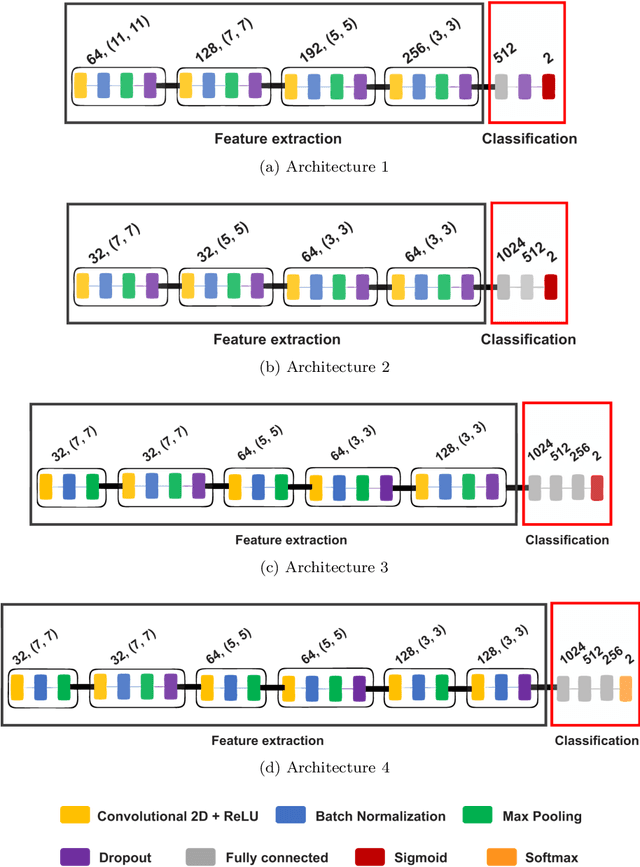
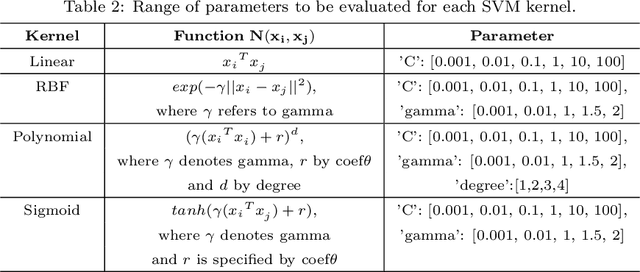
Glomeruli are histological structures of the kidney cortex formed by interwoven blood capillaries, and are responsible for blood filtration. Glomerular lesions impair kidney filtration capability, leading to protein loss and metabolic waste retention. An example of lesion is the glomerular hypercellularity, which is characterized by an increase in the number of cell nuclei in different areas of the glomeruli. Glomerular hypercellularity is a frequent lesion present in different kidney diseases. Automatic detection of glomerular hypercellularity would accelerate the screening of scanned histological slides for the lesion, enhancing clinical diagnosis. Having this in mind, we propose a new approach for classification of hypercellularity in human kidney images. Our proposed method introduces a novel architecture of a convolutional neural network (CNN) along with a support vector machine, achieving near perfect average results with the FIOCRUZ data set in a binary classification (lesion or normal). Our deep-based classifier outperformed the state-of-the-art results on the same data set. Additionally, classification of hypercellularity sub-lesions was also performed, considering mesangial, endocapilar and both lesions; in this multi-classification task, our proposed method just failed in 4\% of the cases. To the best of our knowledge, this is the first study on deep learning over a data set of glomerular hypercellularity images of human kidney.
How far did we get in face spoofing detection?
Sep 29, 2018


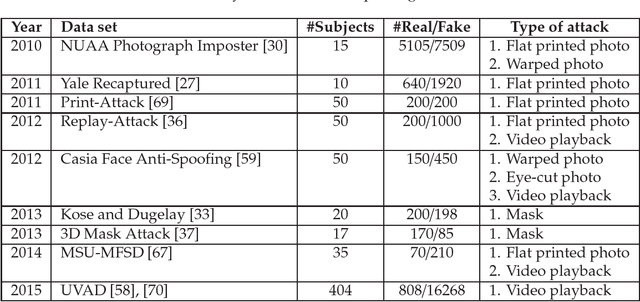
The growing use of control access systems based on face recognition shed light over the need for even more accurate systems to detect face spoofing attacks. In this paper, an extensive analysis on face spoofing detection works published in the last decade is presented. The analyzed works are categorized by their fundamental parts, i.e., descriptors and classifiers. This structured survey also brings the temporal evolution of the face spoofing detection field, as well as a comparative analysis of the works considering the most important public data sets in the field. The methodology followed in this work is particularly relevant to observe trends in the existing approaches, to discuss still opened issues, and to propose new perspectives for the future of face spoofing detection.
ISEC: Iterative over-Segmentation via Edge Clustering
Feb 16, 2018
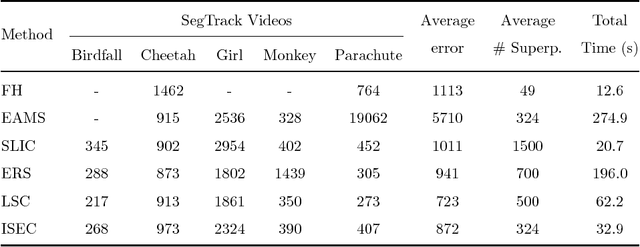
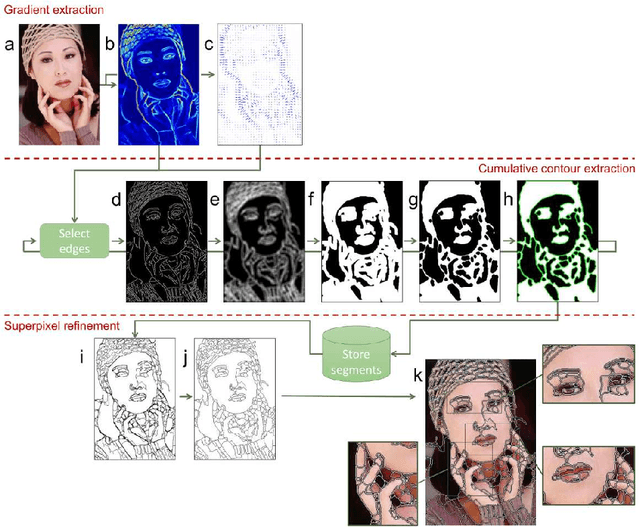
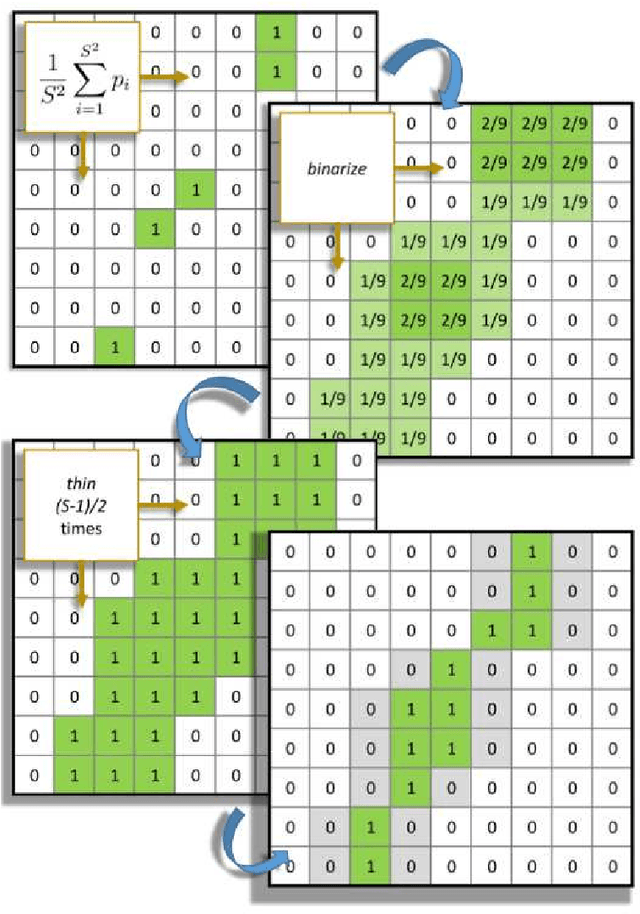
Several image pattern recognition tasks rely on superpixel generation as a fundamental step. Image analysis based on superpixels facilitates domain-specific applications, also speeding up the overall processing time of the task. Recent superpixel methods have been designed to fit boundary adherence, usually regulating the size and shape of each superpixel in order to mitigate the occurrence of undersegmentation failures. Superpixel regularity and compactness sometimes imposes an excessive number of segments in the image, which ultimately decreases the efficiency of the final segmentation, specially in video segmentation. We propose here a novel method to generate superpixels, called iterative over-segmentation via edge clustering (ISEC), which addresses the over-segmentation problem from a different perspective in contrast to recent state-of-the-art approaches. ISEC iteratively clusters edges extracted from the image objects, providing adaptive superpixels in size, shape and quantity, while preserving suitable adherence to the real object boundaries. All this is achieved at a very low computational cost. Experiments show that ISEC stands out from existing methods, meeting a favorable balance between segmentation stability and accurate representation of motion discontinuities, which are features specially suitable to video segmentation.