 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised classification of dental conditions in panoramic radiographs using large language model and instance segmentation: A real-world dataset evaluation
Jun 25, 2024



Dental panoramic radiographs offer vast diagnostic opportunities, but training supervised deep learning networks for automatic analysis of those radiology images is hampered by a shortage of labeled data. Here, a different perspective on this problem is introduced. A semi-supervised learning framework is proposed to classify thirteen dental conditions on panoramic radiographs, with a particular emphasis on teeth. Large language models were explored to annotate the most common dental conditions based on dental reports. Additionally, a masked autoencoder was employed to pre-train the classification neural network, and a Vision Transformer was used to leverage the unlabeled data. The analyses were validated using two of the most extensive datasets in the literature, comprising 8,795 panoramic radiographs and 8,029 paired reports and images. Encouragingly, the results consistently met or surpassed the baseline metrics for the Matthews correlation coefficient. A comparison of the proposed solution with human practitioners, supported by statistical analysis, highlighted its effectiveness and performance limitations; based on the degree of agreement among specialists, the solution demonstrated an accuracy level comparable to that of a junior specialist.
OdontoAI: A human-in-the-loop labeled data set and an online platform to boost research on dental panoramic radiographs
Mar 29, 2022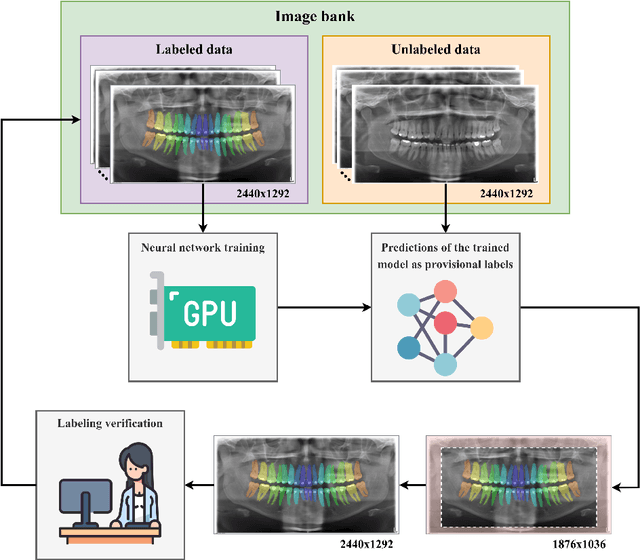


Deep learning has remarkably advanced in the last few years, supported by large labeled data sets. These data sets are precious yet scarce because of the time-consuming labeling procedures, discouraging researchers from producing them. This scarcity is especially true in dentistry, where deep learning applications are still in an embryonic stage. Motivated by this background, we address in this study the construction of a public data set of dental panoramic radiographs. Our objects of interest are the teeth, which are segmented and numbered, as they are the primary targets for dentists when screening a panoramic radiograph. We benefited from the human-in-the-loop (HITL) concept to expedite the labeling procedure, using predictions from deep neural networks as provisional labels, later verified by human annotators. All the gathering and labeling procedures of this novel data set is thoroughly analyzed. The results were consistent and behaved as expected: At each HITL iteration, the model predictions improved. Our results demonstrated a 51% labeling time reduction using HITL, saving us more than 390 continuous working hours. In a novel online platform, called OdontoAI, created to work as task central for this novel data set, we released 4,000 images, from which 2,000 have their labels publicly available for model fitting. The labels of the other 2,000 images are private and used for model evaluation considering instance and semantic segmentation and numbering. To the best of our knowledge, this is the largest-scale publicly available data set for panoramic radiographs, and the OdontoAI is the first platform of its kind in dentistry.