 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised classification of dental conditions in panoramic radiographs using large language model and instance segmentation: A real-world dataset evaluation
Jun 25, 2024



Dental panoramic radiographs offer vast diagnostic opportunities, but training supervised deep learning networks for automatic analysis of those radiology images is hampered by a shortage of labeled data. Here, a different perspective on this problem is introduced. A semi-supervised learning framework is proposed to classify thirteen dental conditions on panoramic radiographs, with a particular emphasis on teeth. Large language models were explored to annotate the most common dental conditions based on dental reports. Additionally, a masked autoencoder was employed to pre-train the classification neural network, and a Vision Transformer was used to leverage the unlabeled data. The analyses were validated using two of the most extensive datasets in the literature, comprising 8,795 panoramic radiographs and 8,029 paired reports and images. Encouragingly, the results consistently met or surpassed the baseline metrics for the Matthews correlation coefficient. A comparison of the proposed solution with human practitioners, supported by statistical analysis, highlighted its effectiveness and performance limitations; based on the degree of agreement among specialists, the solution demonstrated an accuracy level comparable to that of a junior specialist.
Attention-based fusion of semantic boundary and non-boundary information to improve semantic segmentation
Aug 05, 2021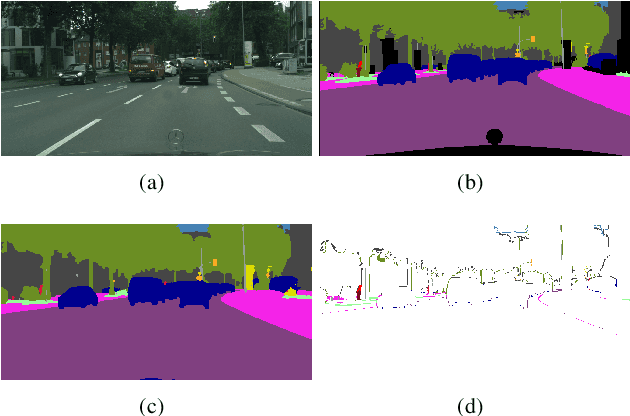
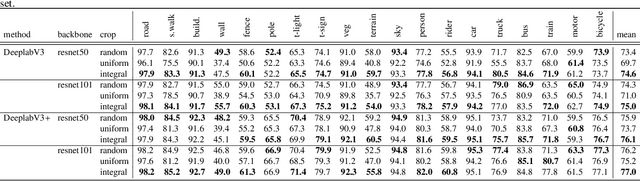
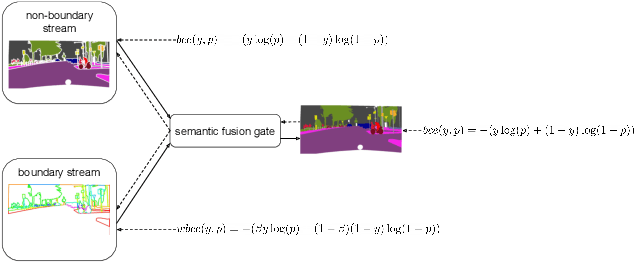

This paper introduces a method for image semantic segmentation grounded on a novel fusion scheme, which takes place inside a deep convolutional neural network. The main goal of our proposal is to explore object boundary information to improve the overall segmentation performance. Unlike previous works that combine boundary and segmentation features, or those that use boundary information to regularize semantic segmentation, we instead propose a novel approach that embodies boundary information onto segmentation. For that, our semantic segmentation method uses two streams, which are combined through an attention gate, forming an end-to-end Y-model. To the best of our knowledge, ours is the first work to show that boundary detection can improve semantic segmentation when fused through a semantic fusion gate (attention model). We performed an extensive evaluation of our method over public data sets. We found competitive results on all data sets after comparing our proposed model with other twelve state-of-the-art segmenters, considering the same training conditions. Our proposed model achieved the best mIoU on the CityScapes, CamVid, and Pascal Context data sets, and the second best on Mapillary Vistas.