 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based fusion of semantic boundary and non-boundary information to improve semantic segmentation
Aug 05, 2021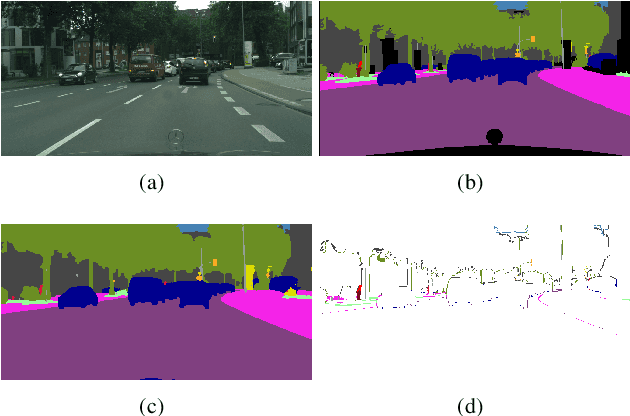
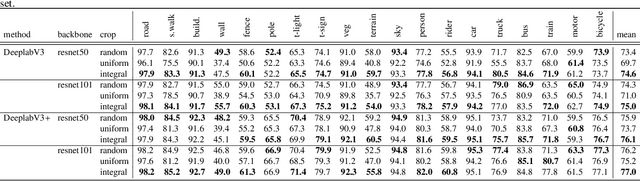
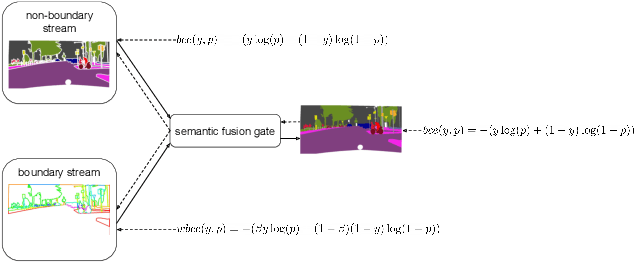

This paper introduces a method for image semantic segmentation grounded on a novel fusion scheme, which takes place inside a deep convolutional neural network. The main goal of our proposal is to explore object boundary information to improve the overall segmentation performance. Unlike previous works that combine boundary and segmentation features, or those that use boundary information to regularize semantic segmentation, we instead propose a novel approach that embodies boundary information onto segmentation. For that, our semantic segmentation method uses two streams, which are combined through an attention gate, forming an end-to-end Y-model. To the best of our knowledge, ours is the first work to show that boundary detection can improve semantic segmentation when fused through a semantic fusion gate (attention model). We performed an extensive evaluation of our method over public data sets. We found competitive results on all data sets after comparing our proposed model with other twelve state-of-the-art segmenters, considering the same training conditions. Our proposed model achieved the best mIoU on the CityScapes, CamVid, and Pascal Context data sets, and the second best on Mapillary Vistas.
On estimating gaze by self-attention augmented convolutions
Aug 25, 2020
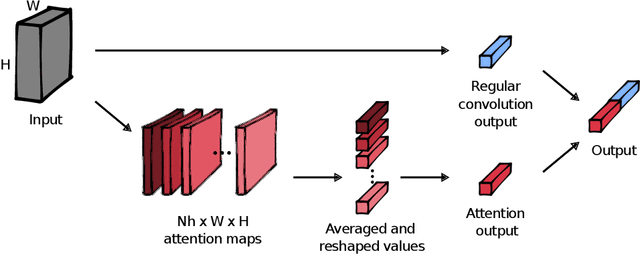
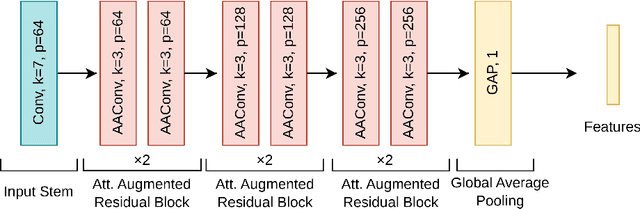
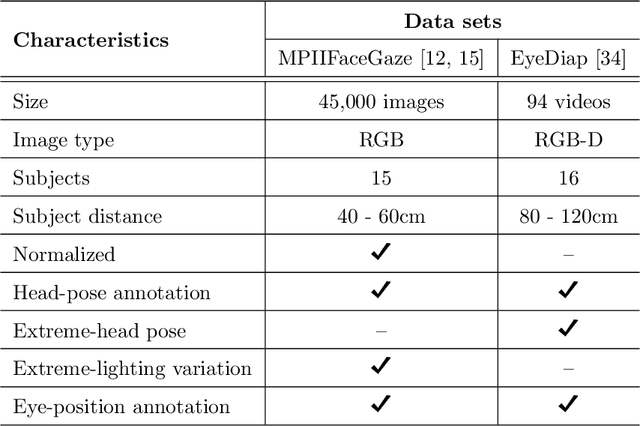
Estimation of 3D gaze is highly relevant to multiple fields, including but not limited to interactive systems, specialized human-computer interfaces, and behavioral research. Although recently deep learning methods have boosted the accuracy of appearance-based gaze estimation, there is still room for improvement in the network architectures for this particular task. Therefore we propose here a novel network architecture grounded on self-attention augmented convolutions to improve the quality of the learned features during the training of a shallower residual network. The rationale is that self-attention mechanism can help outperform deeper architectures by learning dependencies between distant regions in full-face images. This mechanism can also create better and more spatially-aware feature representations derived from the face and eye images before gaze regression. We dubbed our framework ARes-gaze, which explores our Attention-augmented ResNet (ARes-14) as twin convolutional backbones. In our experiments, results showed a decrease of the average angular error by 2.38% when compared to state-of-the-art methods on the MPIIFaceGaze data set, and a second-place on the EyeDiap data set. It is noteworthy that our proposed framework was the only one to reach high accuracy simultaneously on both data sets.