 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection and Hyperparameter Fine-tuning in Artificial Neural Networks for Wood Quality Classification
Oct 20, 2023Quality classification of wood boards is an essential task in the sawmill industry, which is still usually performed by human operators in small to median companies in developing countries. Machine learning algorithms have been successfully employed to investigate the problem, offering a more affordable alternative compared to other solutions. However, such approaches usually present some drawbacks regarding the proper selection of their hyperparameters. Moreover, the models are susceptible to the features extracted from wood board images, which influence the induction of the model and, consequently, its generalization power. Therefore, in this paper, we investigate the problem of simultaneously tuning the hyperparameters of an artificial neural network (ANN) as well as selecting a subset of characteristics that better describes the wood board quality. Experiments were conducted over a private dataset composed of images obtained from a sawmill industry and described using different feature descriptors. The predictive performance of the model was compared against five baseline methods as well as a random search, performing either ANN hyperparameter tuning and feature selection. Experimental results suggest that hyperparameters should be adjusted according to the feature set, or the features should be selected considering the hyperparameter values. In summary, the best predictive performance, i.e., a balanced accuracy of $0.80$, was achieved in two distinct scenarios: (i) performing only feature selection, and (ii) performing both tasks concomitantly. Thus, we suggest that at least one of the two approaches should be considered in the context of industrial applications.
PL-kNN: A Parameterless Nearest Neighbors Classifier
Sep 30, 2022

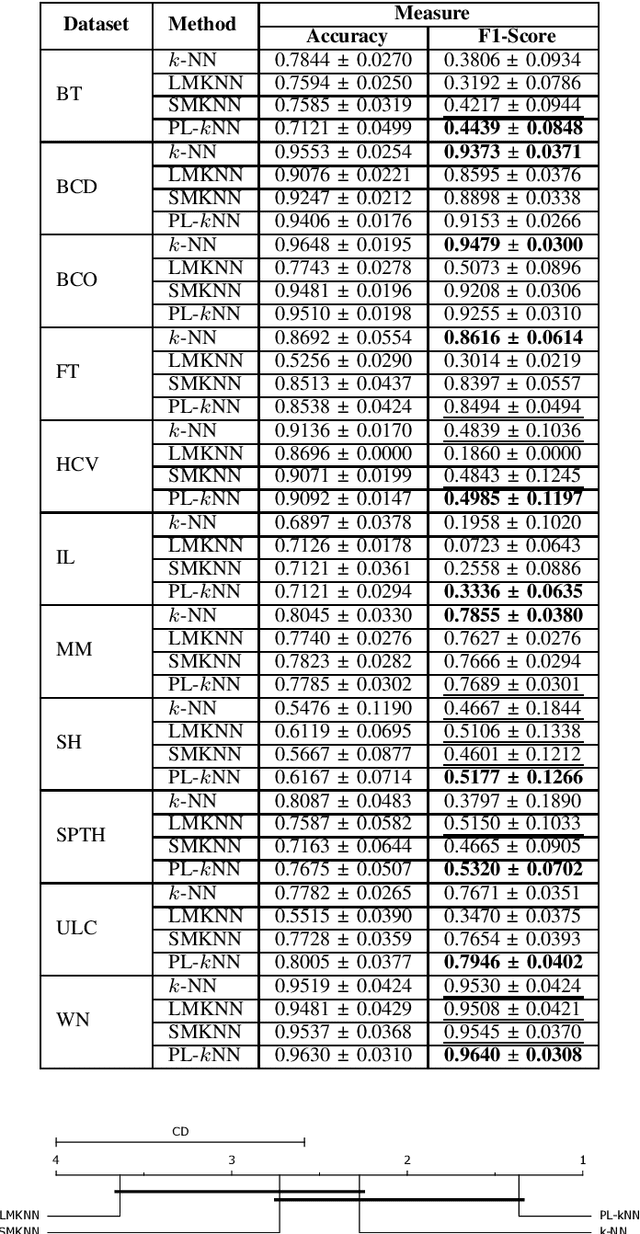
Demands for minimum parameter setup in machine learning models are desirable to avoid time-consuming optimization processes. The $k$-Nearest Neighbors is one of the most effective and straightforward models employed in numerous problems. Despite its well-known performance, it requires the value of $k$ for specific data distribution, thus demanding expensive computational efforts. This paper proposes a $k$-Nearest Neighbors classifier that bypasses the need to define the value of $k$. The model computes the $k$ value adaptively considering the data distribution of the training set. We compared the proposed model against the standard $k$-Nearest Neighbors classifier and two parameterless versions from the literature. Experiments over 11 public datasets confirm the robustness of the proposed approach, for the obtained results were similar or even better than its counterpart versions.
Handling Imbalanced Datasets Through Optimum-Path Forest
Feb 17, 2022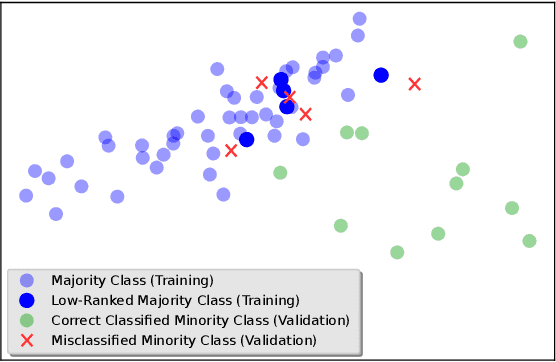
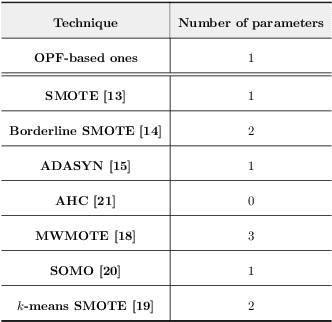
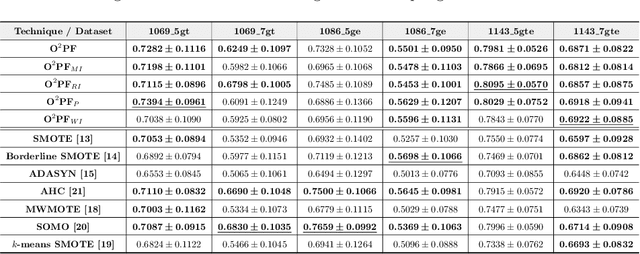
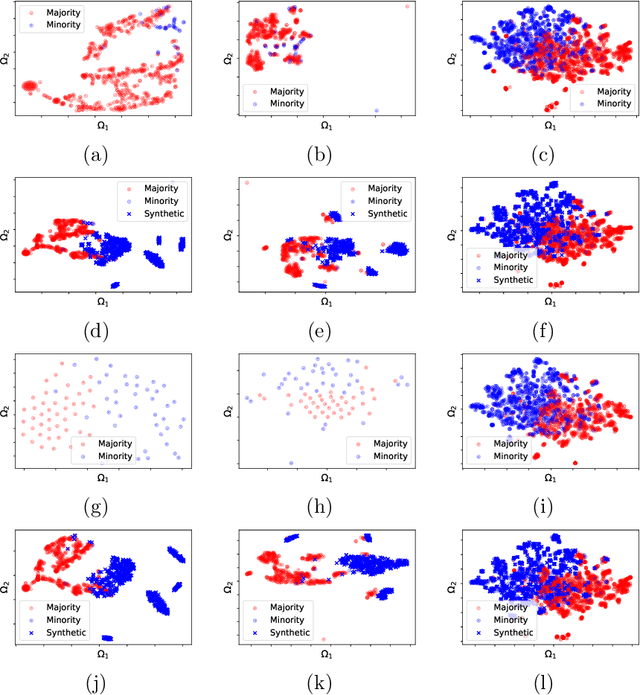
In the last decade, machine learning-based approaches became capable of performing a wide range of complex tasks sometimes better than humans, demanding a fraction of the time. Such an advance is partially due to the exponential growth in the amount of data available, which makes it possible to extract trustworthy real-world information from them. However, such data is generally imbalanced since some phenomena are more likely than others. Such a behavior yields considerable influence on the machine learning model's performance since it becomes biased on the more frequent data it receives. Despite the considerable amount of machine learning methods, a graph-based approach has attracted considerable notoriety due to the outstanding performance over many applications, i.e., the Optimum-Path Forest (OPF). In this paper, we propose three OPF-based strategies to deal with the imbalance problem: the $\text{O}^2$PF and the OPF-US, which are novel approaches for oversampling and undersampling, respectively, as well as a hybrid strategy combining both approaches. The paper also introduces a set of variants concerning the strategies mentioned above. Results compared against several state-of-the-art techniques over public and private datasets confirm the robustness of the proposed approaches.
A Multimodal Canonical-Correlated Graph Neural Network for Energy-Efficient Speech Enhancement
Feb 09, 2022

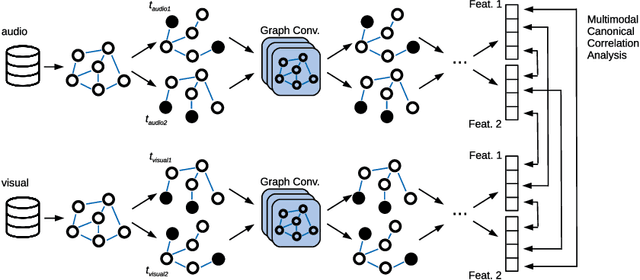

This paper proposes a novel multimodal self-supervised architecture for energy-efficient AV speech enhancement by integrating graph neural networks with canonical correlation analysis (CCA-GNN). This builds on a state-of-the-art CCA-GNN that aims to learn representative embeddings by maximizing the correlation between pairs of augmented views of the same input while decorrelating disconnected features. The key idea of the conventional CCA-GNN involves discarding augmentation-variant information and preserving augmentation-invariant information whilst preventing capturing of redundant information. Our proposed AV CCA-GNN model is designed to deal with the challenging multimodal representation learning context. Specifically, our model improves contextual AV speech processing by maximizing canonical correlation from augmented views of the same channel, as well as canonical correlation from audio and visual embeddings. In addition, we propose a positional encoding of the nodes that considers a prior-frame sequence distance instead of a feature-space representation while computing the node's nearest neighbors. This serves to introduce temporal information in the embeddings through the neighborhood's connectivity. Experiments conducted with the benchmark ChiME3 dataset show that our proposed prior frame-based AV CCA-GNN reinforces better feature learning in the temporal context, leading to more energy-efficient speech reconstruction compared to state-of-the-art CCA-GNN and multi-layer perceptron models. The results demonstrate the potential of our proposed approach for exploitation in future assistive technology and energy-efficient multimodal devices.
A Metaheuristic-Driven Approach to Fine-Tune Deep Boltzmann Machines
Jan 14, 2021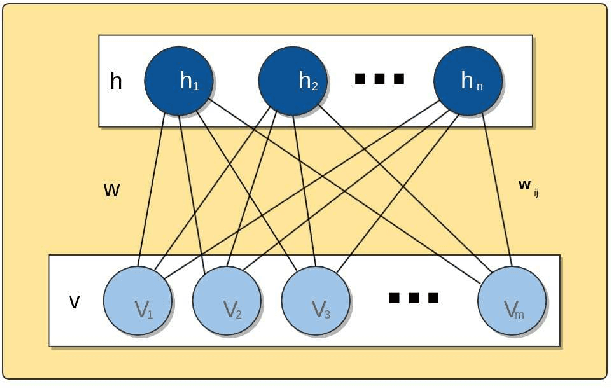
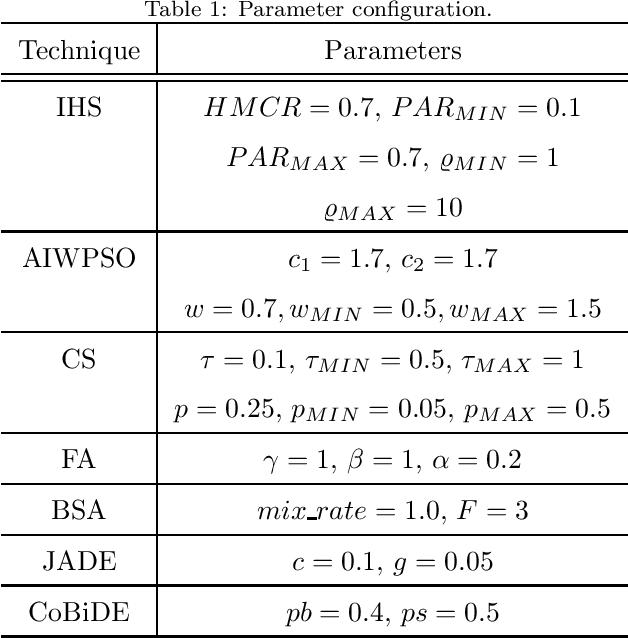
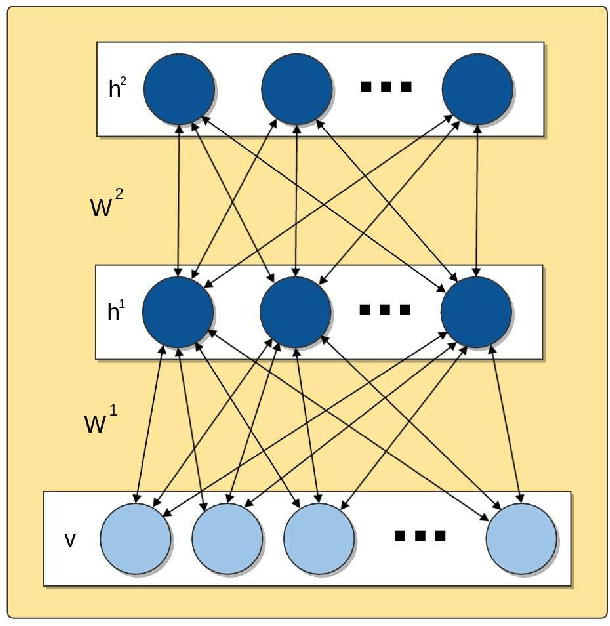
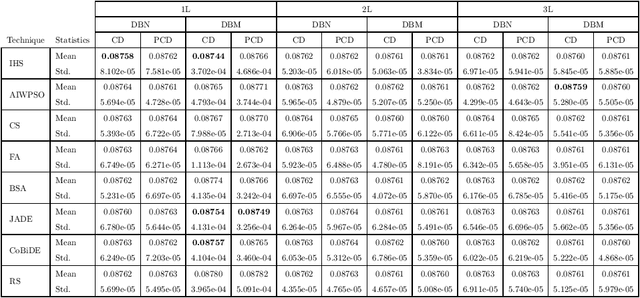
Deep learning techniques, such as Deep Boltzmann Machines (DBMs), have received considerable attention over the past years due to the outstanding results concerning a variable range of domains. One of the main shortcomings of these techniques involves the choice of their hyperparameters, since they have a significant impact on the final results. This work addresses the issue of fine-tuning hyperparameters of Deep Boltzmann Machines using metaheuristic optimization techniques with different backgrounds, such as swarm intelligence, memory- and evolutionary-based approaches. Experiments conducted in three public datasets for binary image reconstruction showed that metaheuristic techniques can obtain reasonable results.
* 30 pages, 7 figures
$\text{O}^2$PF: Oversampling via Optimum-Path Forest for Breast Cancer Detection
Jan 14, 2021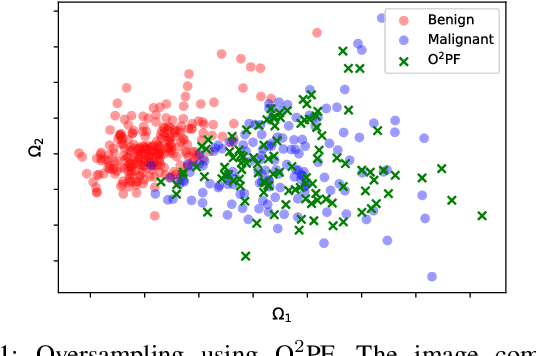
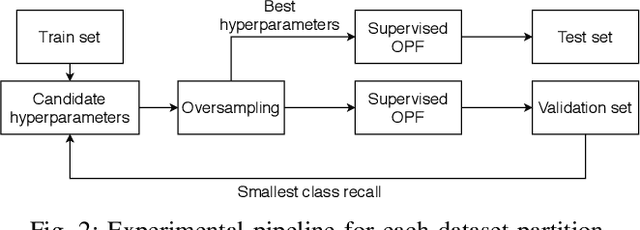
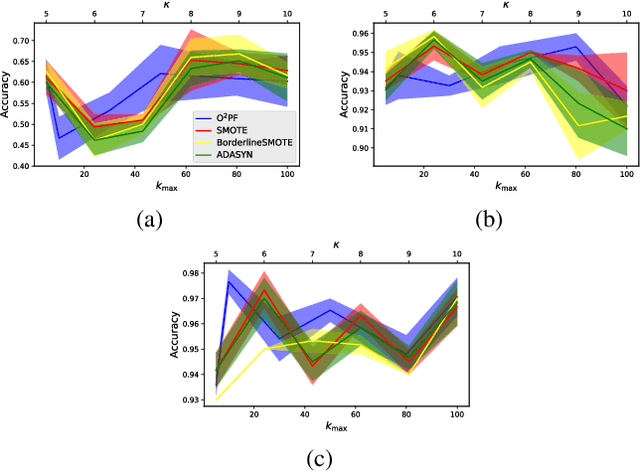
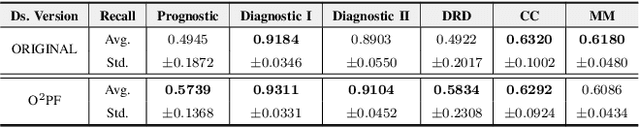
Breast cancer is among the most deadly diseases, distressing mostly women worldwide. Although traditional methods for detection have presented themselves as valid for the task, they still commonly present low accuracies and demand considerable time and effort from professionals. Therefore, a computer-aided diagnosis (CAD) system capable of providing early detection becomes hugely desirable. In the last decade, machine learning-based techniques have been of paramount importance in this context, since they are capable of extracting essential information from data and reasoning about it. However, such approaches still suffer from imbalanced data, specifically on medical issues, where the number of healthy people samples is, in general, considerably higher than the number of patients. Therefore this paper proposes the $\text{O}^2$PF, a data oversampling method based on the unsupervised Optimum-Path Forest Algorithm. Experiments conducted over the full oversampling scenario state the robustness of the model, which is compared against three well-established oversampling methods considering three breast cancer and three general-purpose tasks for medical issues datasets.