 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Canonical-Correlated Graph Neural Network for Energy-Efficient Speech Enhancement
Paper and Code
Feb 09, 2022

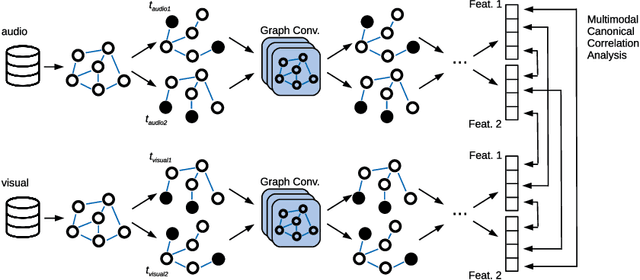

This paper proposes a novel multimodal self-supervised architecture for energy-efficient AV speech enhancement by integrating graph neural networks with canonical correlation analysis (CCA-GNN). This builds on a state-of-the-art CCA-GNN that aims to learn representative embeddings by maximizing the correlation between pairs of augmented views of the same input while decorrelating disconnected features. The key idea of the conventional CCA-GNN involves discarding augmentation-variant information and preserving augmentation-invariant information whilst preventing capturing of redundant information. Our proposed AV CCA-GNN model is designed to deal with the challenging multimodal representation learning context. Specifically, our model improves contextual AV speech processing by maximizing canonical correlation from augmented views of the same channel, as well as canonical correlation from audio and visual embeddings. In addition, we propose a positional encoding of the nodes that considers a prior-frame sequence distance instead of a feature-space representation while computing the node's nearest neighbors. This serves to introduce temporal information in the embeddings through the neighborhood's connectivity. Experiments conducted with the benchmark ChiME3 dataset show that our proposed prior frame-based AV CCA-GNN reinforces better feature learning in the temporal context, leading to more energy-efficient speech reconstruction compared to state-of-the-art CCA-GNN and multi-layer perceptron models. The results demonstrate the potential of our proposed approach for exploitation in future assistive technology and energy-efficient multimodal devices.