 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Imbalanced Datasets Through Optimum-Path Forest
Feb 17, 2022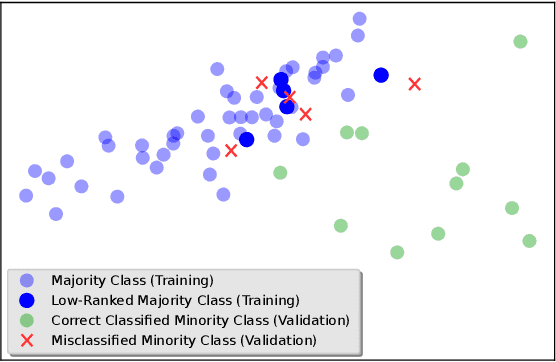
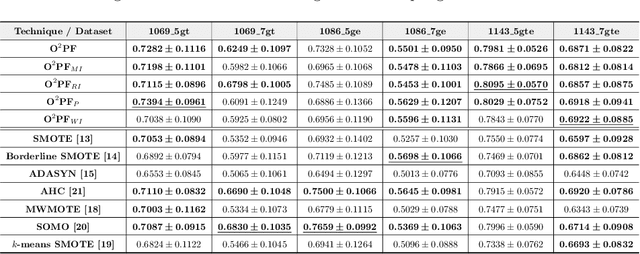
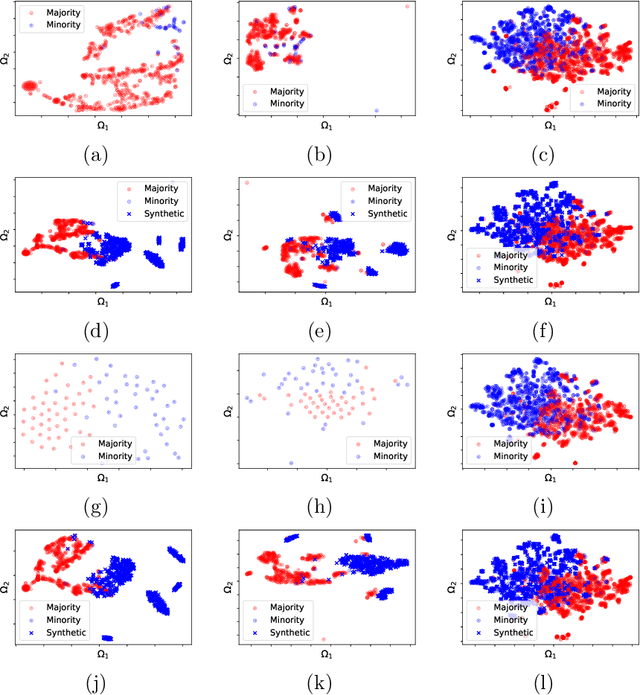
In the last decade, machine learning-based approaches became capable of performing a wide range of complex tasks sometimes better than humans, demanding a fraction of the time. Such an advance is partially due to the exponential growth in the amount of data available, which makes it possible to extract trustworthy real-world information from them. However, such data is generally imbalanced since some phenomena are more likely than others. Such a behavior yields considerable influence on the machine learning model's performance since it becomes biased on the more frequent data it receives. Despite the considerable amount of machine learning methods, a graph-based approach has attracted considerable notoriety due to the outstanding performance over many applications, i.e., the Optimum-Path Forest (OPF). In this paper, we propose three OPF-based strategies to deal with the imbalance problem: the $\text{O}^2$PF and the OPF-US, which are novel approaches for oversampling and undersampling, respectively, as well as a hybrid strategy combining both approaches. The paper also introduces a set of variants concerning the strategies mentioned above. Results compared against several state-of-the-art techniques over public and private datasets confirm the robustness of the proposed approaches.