 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversified in-domain synthesis with efficient fine-tuning for few-shot classification
Dec 07, 2023Few-shot image classification aims to learn an image classifier using only a small set of labeled examples per class. A recent research direction for improving few-shot classifiers involves augmenting the labelled samples with synthetic images created by state-of-the-art text-to-image generation models. Following this trend, we propose Diversified In-domain Synthesis with Efficient Fine-tuning (DISEF), a novel approach which addresses the generalization challenge in few-shot learning using synthetic data. DISEF consists of two main components. First, we propose a novel text-to-image augmentation pipeline that, by leveraging the real samples and their rich semantics coming from an advanced captioning model, promotes in-domain sample diversity for better generalization. Second, we emphasize the importance of effective model fine-tuning in few-shot recognition, proposing to use Low-Rank Adaptation (LoRA) for joint adaptation of the text and image encoders in a Vision Language Model. We validate our method in ten different benchmarks, consistently outperforming baselines and establishing a new state-of-the-art for few-shot classification. Code is available at https://github.com/vturrisi/disef.
Unsupervised Domain Adaptation for Video Transformers in Action Recognition
Jul 26, 2022
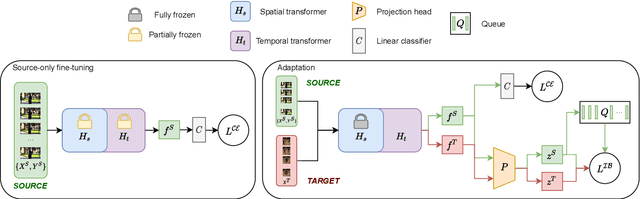
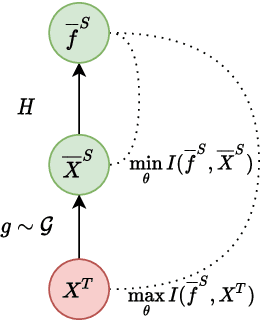
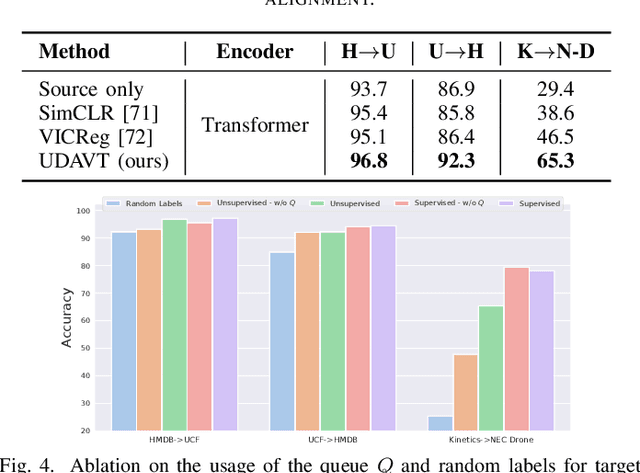
Over the last few years, Unsupervised Domain Adaptation (UDA) techniques have acquired remarkable importance and popularity in computer vision. However, when compared to the extensive literature available for images, the field of videos is still relatively unexplored. On the other hand, the performance of a model in action recognition is heavily affected by domain shift. In this paper, we propose a simple and novel UDA approach for video action recognition. Our approach leverages recent advances on spatio-temporal transformers to build a robust source model that better generalises to the target domain. Furthermore, our architecture learns domain invariant features thanks to the introduction of a novel alignment loss term derived from the Information Bottleneck principle. We report results on two video action recognition benchmarks for UDA, showing state-of-the-art performance on HMDB$\leftrightarrow$UCF, as well as on Kinetics$\rightarrow$NEC-Drone, which is more challenging. This demonstrates the effectiveness of our method in handling different levels of domain shift. The source code is available at https://github.com/vturrisi/UDAVT.
Self-Supervised Models are Continual Learners
Dec 08, 2021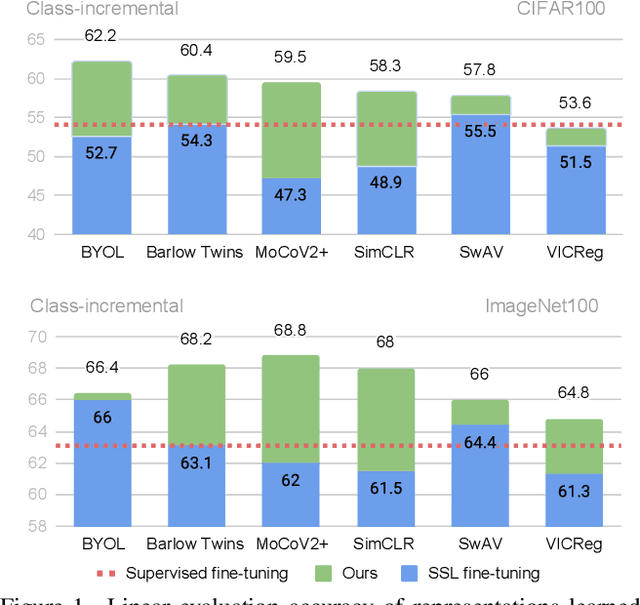

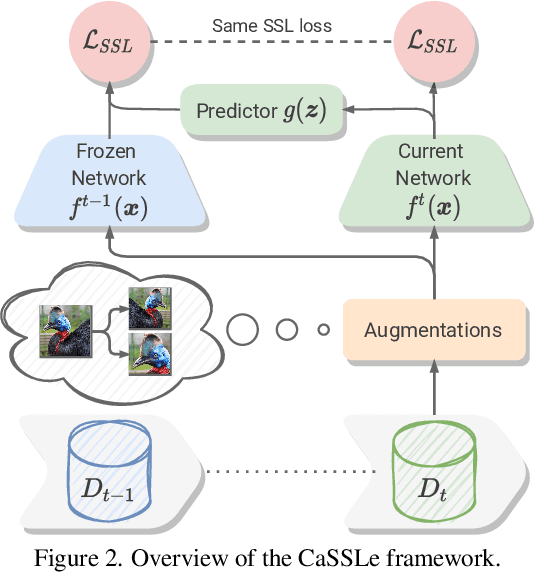
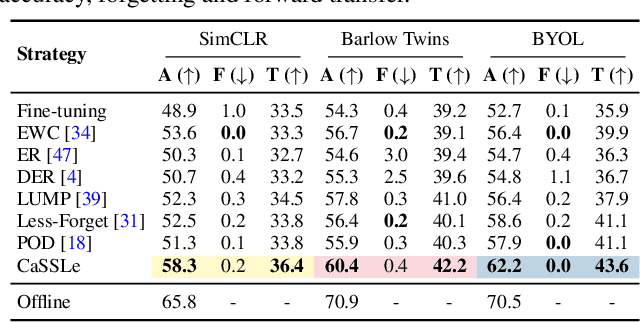
Self-supervised models have been shown to produce comparable or better visual representations than their supervised counterparts when trained offline on unlabeled data at scale. However, their efficacy is catastrophically reduced in a Continual Learning (CL) scenario where data is presented to the model sequentially. In this paper, we show that self-supervised loss functions can be seamlessly converted into distillation mechanisms for CL by adding a predictor network that maps the current state of the representations to their past state. This enables us to devise a framework for Continual self-supervised visual representation Learning that (i) significantly improves the quality of the learned representations, (ii) is compatible with several state-of-the-art self-supervised objectives, and (iii) needs little to no hyperparameter tuning. We demonstrate the effectiveness of our approach empirically by training six popular self-supervised models in various CL settings.
Solo-learn: A Library of Self-supervised Methods for Visual Representation Learning
Aug 16, 2021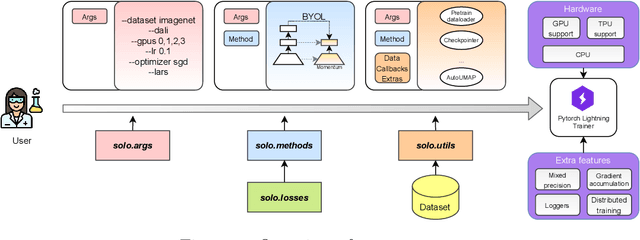
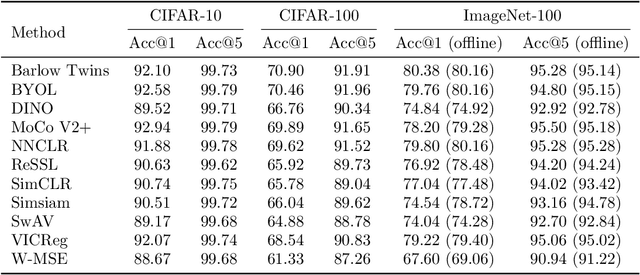

This paper presents solo-learn, a library of self-supervised methods for visual representation learning. Implemented in Python, using Pytorch and Pytorch lightning, the library fits both research and industry needs by featuring distributed training pipelines with mixed-precision, faster data loading via Nvidia DALI, online linear evaluation for better prototyping, and many additional training tricks. Our goal is to provide an easy-to-use library comprising a large amount of Self-supervised Learning (SSL) methods, that can be easily extended and fine-tuned by the community. solo-learn opens up avenues for exploiting large-budget SSL solutions on inexpensive smaller infrastructures and seeks to democratize SSL by making it accessible to all. The source code is available at https://github.com/vturrisi/solo-learn.
Online Local Boosting: improving performance in online decision trees
Jul 16, 2019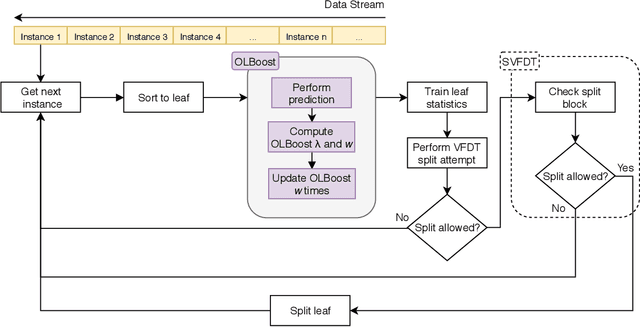
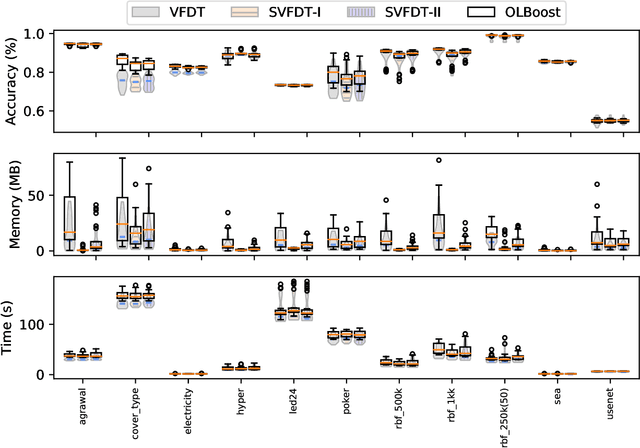
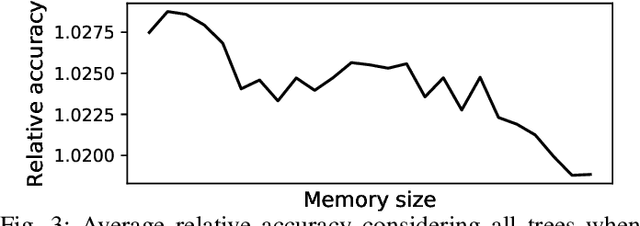
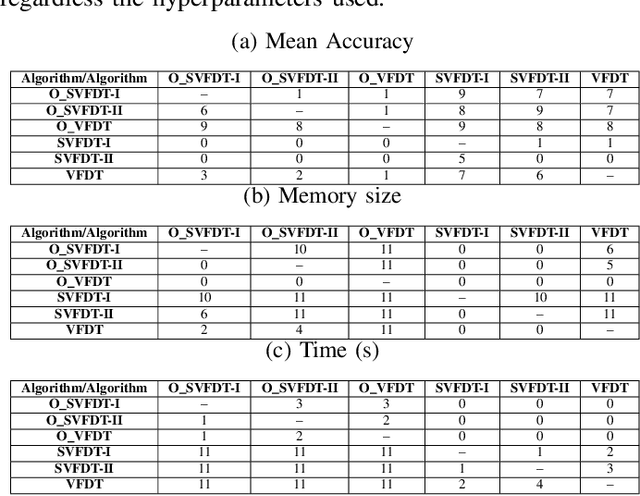
As more data are produced each day, and faster, data stream mining is growing in importance, making clear the need for algorithms able to fast process these data. Data stream mining algorithms are meant to be solutions to extract knowledge online, specially tailored from continuous data problem. Many of the current algorithms for data stream mining have high processing and memory costs. Often, the higher the predictive performance, the higher these costs. To increase predictive performance without largely increasing memory and time costs, this paper introduces a novel algorithm, named Online Local Boosting (OLBoost), which can be combined into online decision tree algorithms to improve their predictive performance without modifying the structure of the induced decision trees. For such, OLBoost applies a boosting to small separate regions of the instances space. Experimental results presented in this paper show that by using OLBoost the online learning decision tree algorithms can significantly improve their predictive performance. Additionally, it can make smaller trees perform as good or better than larger trees.