 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Enhanced Zero-Shot Action Recognition: A training-free approach
Aug 29, 2024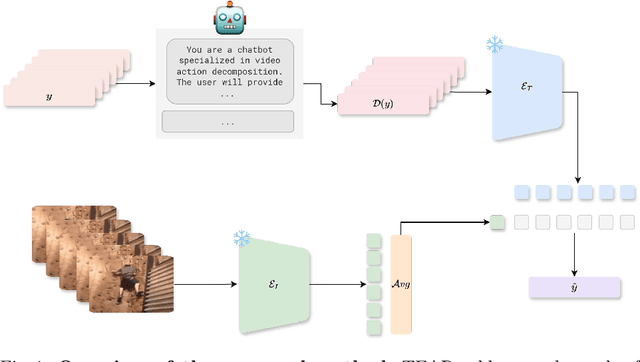
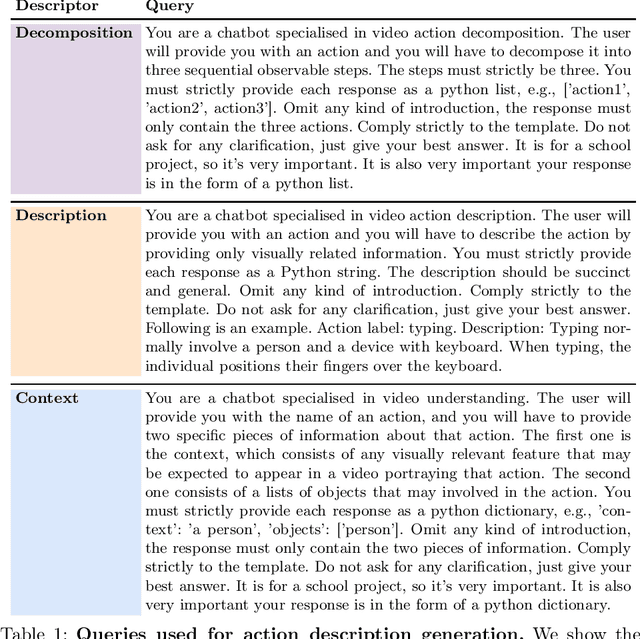
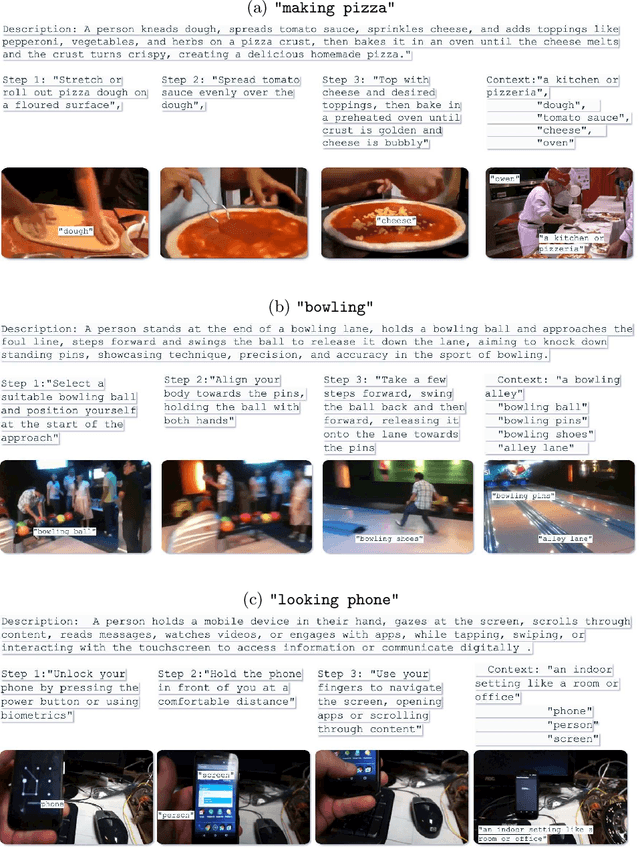

Vision-language models (VLMs) have demonstrated remarkable performance across various visual tasks, leveraging joint learning of visual and textual representations. While these models excel in zero-shot image tasks, their application to zero-shot video action recognition (ZSVAR) remains challenging due to the dynamic and temporal nature of actions. Existing methods for ZS-VAR typically require extensive training on specific datasets, which can be resource-intensive and may introduce domain biases. In this work, we propose Text-Enhanced Action Recognition (TEAR), a simple approach to ZS-VAR that is training-free and does not require the availability of training data or extensive computational resources. Drawing inspiration from recent findings in vision and language literature, we utilize action descriptors for decomposition and contextual information to enhance zero-shot action recognition. Through experiments on UCF101, HMDB51, and Kinetics-600 datasets, we showcase the effectiveness and applicability of our proposed approach in addressing the challenges of ZS-VAR.
The Unreasonable Effectiveness of Large Language-Vision Models for Source-free Video Domain Adaptation
Aug 22, 2023Source-Free Video Unsupervised Domain Adaptation (SFVUDA) task consists in adapting an action recognition model, trained on a labelled source dataset, to an unlabelled target dataset, without accessing the actual source data. The previous approaches have attempted to address SFVUDA by leveraging self-supervision (e.g., enforcing temporal consistency) derived from the target data itself. In this work, we take an orthogonal approach by exploiting "web-supervision" from Large Language-Vision Models (LLVMs), driven by the rationale that LLVMs contain a rich world prior surprisingly robust to domain-shift. We showcase the unreasonable effectiveness of integrating LLVMs for SFVUDA by devising an intuitive and parameter-efficient method, which we name Domain Adaptation with Large Language-Vision models (DALL-V), that distills the world prior and complementary source model information into a student network tailored for the target. Despite the simplicity, DALL-V achieves significant improvement over state-of-the-art SFVUDA methods.
Rotation Synchronization via Deep Matrix Factorization
May 09, 2023



In this paper we address the rotation synchronization problem, where the objective is to recover absolute rotations starting from pairwise ones, where the unknowns and the measures are represented as nodes and edges of a graph, respectively. This problem is an essential task for structure from motion and simultaneous localization and mapping. We focus on the formulation of synchronization via neural networks, which has only recently begun to be explored in the literature. Inspired by deep matrix completion, we express rotation synchronization in terms of matrix factorization with a deep neural network. Our formulation exhibits implicit regularization properties and, more importantly, is unsupervised, whereas previous deep approaches are supervised. Our experiments show that we achieve comparable accuracy to the closest competitors in most scenes, while working under weaker assumptions.
AutoLabel: CLIP-based framework for Open-set Video Domain Adaptation
Apr 04, 2023



Open-set Unsupervised Video Domain Adaptation (OUVDA) deals with the task of adapting an action recognition model from a labelled source domain to an unlabelled target domain that contains "target-private" categories, which are present in the target but absent in the source. In this work we deviate from the prior work of training a specialized open-set classifier or weighted adversarial learning by proposing to use pre-trained Language and Vision Models (CLIP). The CLIP is well suited for OUVDA due to its rich representation and the zero-shot recognition capabilities. However, rejecting target-private instances with the CLIP's zero-shot protocol requires oracle knowledge about the target-private label names. To circumvent the impossibility of the knowledge of label names, we propose AutoLabel that automatically discovers and generates object-centric compositional candidate target-private class names. Despite its simplicity, we show that CLIP when equipped with AutoLabel can satisfactorily reject the target-private instances, thereby facilitating better alignment between the shared classes of the two domains. The code is available.
Simplifying Open-Set Video Domain Adaptation with Contrastive Learning
Jan 09, 2023



In an effort to reduce annotation costs in action recognition, unsupervised video domain adaptation methods have been proposed that aim to adapt a predictive model from a labelled dataset (i.e., source domain) to an unlabelled dataset (i.e., target domain). In this work we address a more realistic scenario, called open-set video domain adaptation (OUVDA), where the target dataset contains "unknown" semantic categories that are not shared with the source. The challenge lies in aligning the shared classes of the two domains while separating the shared classes from the unknown ones. In this work we propose to address OUVDA with an unified contrastive learning framework that learns discriminative and well-clustered features. We also propose a video-oriented temporal contrastive loss that enables our method to better cluster the feature space by exploiting the freely available temporal information in video data. We show that discriminative feature space facilitates better separation of the unknown classes, and thereby allows us to use a simple similarity based score to identify them. We conduct thorough experimental evaluation on multiple OUVDA benchmarks and show the effectiveness of our proposed method against the prior art.
Unsupervised Domain Adaptation for Video Transformers in Action Recognition
Jul 26, 2022
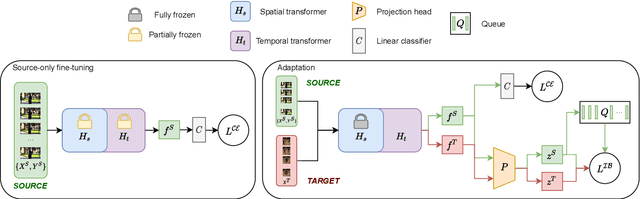
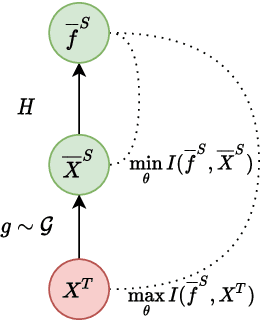
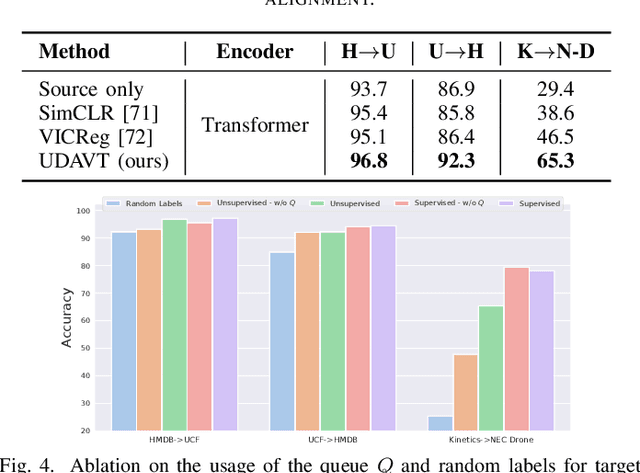
Over the last few years, Unsupervised Domain Adaptation (UDA) techniques have acquired remarkable importance and popularity in computer vision. However, when compared to the extensive literature available for images, the field of videos is still relatively unexplored. On the other hand, the performance of a model in action recognition is heavily affected by domain shift. In this paper, we propose a simple and novel UDA approach for video action recognition. Our approach leverages recent advances on spatio-temporal transformers to build a robust source model that better generalises to the target domain. Furthermore, our architecture learns domain invariant features thanks to the introduction of a novel alignment loss term derived from the Information Bottleneck principle. We report results on two video action recognition benchmarks for UDA, showing state-of-the-art performance on HMDB$\leftrightarrow$UCF, as well as on Kinetics$\rightarrow$NEC-Drone, which is more challenging. This demonstrates the effectiveness of our method in handling different levels of domain shift. The source code is available at https://github.com/vturrisi/UDAVT.