 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition of Historical Text via Large Language Model
Aug 25, 2025Large language models have demonstrated remarkable versatility across a wide range of natural language processing tasks and domains. One such task is Named Entity Recognition (NER), which involves identifying and classifying proper names in text, such as people, organizations, locations, dates, and other specific entities. NER plays a crucial role in extracting information from unstructured textual data, enabling downstream applications such as information retrieval from unstructured text. Traditionally, NER is addressed using supervised machine learning approaches, which require large amounts of annotated training data. However, historical texts present a unique challenge, as the annotated datasets are often scarce or nonexistent, due to the high cost and expertise required for manual labeling. In addition, the variability and noise inherent in historical language, such as inconsistent spelling and archaic vocabulary, further complicate the development of reliable NER systems for these sources. In this study, we explore the feasibility of applying LLMs to NER in historical documents using zero-shot and few-shot prompting strategies, which require little to no task-specific training data. Our experiments, conducted on the HIPE-2022 (Identifying Historical People, Places and other Entities) dataset, show that LLMs can achieve reasonably strong performance on NER tasks in this setting. While their performance falls short of fully supervised models trained on domain-specific annotations, the results are nevertheless promising. These findings suggest that LLMs offer a viable and efficient alternative for information extraction in low-resource or historically significant corpora, where traditional supervised methods are infeasible.
Text-Enhanced Zero-Shot Action Recognition: A training-free approach
Aug 29, 2024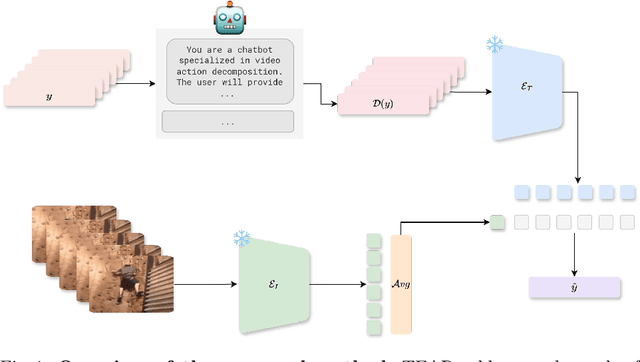
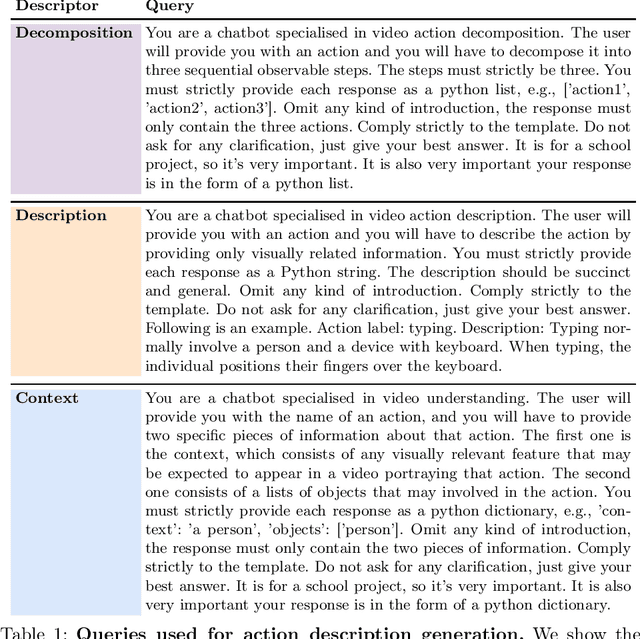
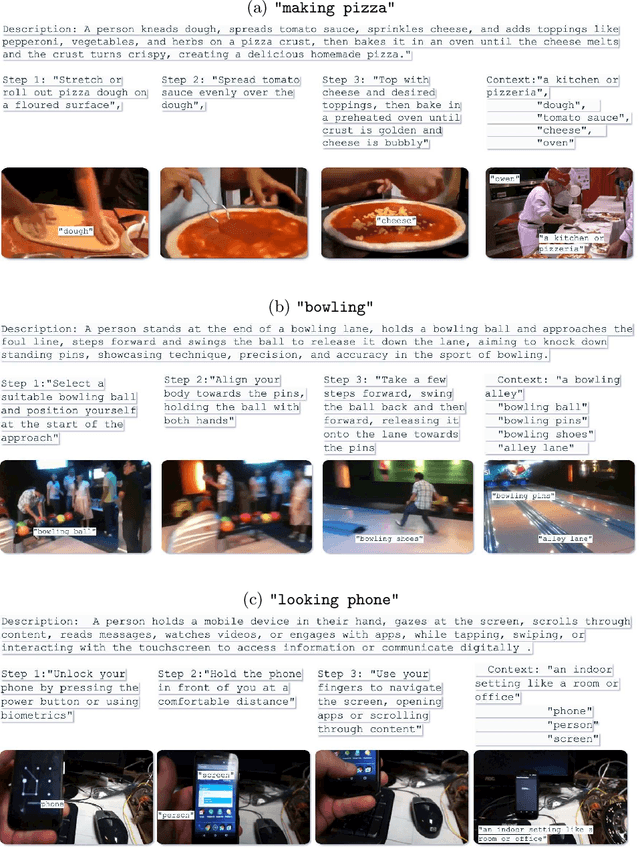

Vision-language models (VLMs) have demonstrated remarkable performance across various visual tasks, leveraging joint learning of visual and textual representations. While these models excel in zero-shot image tasks, their application to zero-shot video action recognition (ZSVAR) remains challenging due to the dynamic and temporal nature of actions. Existing methods for ZS-VAR typically require extensive training on specific datasets, which can be resource-intensive and may introduce domain biases. In this work, we propose Text-Enhanced Action Recognition (TEAR), a simple approach to ZS-VAR that is training-free and does not require the availability of training data or extensive computational resources. Drawing inspiration from recent findings in vision and language literature, we utilize action descriptors for decomposition and contextual information to enhance zero-shot action recognition. Through experiments on UCF101, HMDB51, and Kinetics-600 datasets, we showcase the effectiveness and applicability of our proposed approach in addressing the challenges of ZS-VAR.
Unsupervised Mandarin-Cantonese Machine Translation
Jan 10, 2023



Advancements in unsupervised machine translation have enabled the development of machine translation systems that can translate between languages for which there is not an abundance of parallel data available. We explored unsupervised machine translation between Mandarin Chinese and Cantonese. Despite the vast number of native speakers of Cantonese, there is still no large-scale corpus for the language, due to the fact that Cantonese is primarily used for oral communication. The key contributions of our project include: 1. The creation of a new corpus containing approximately 1 million Cantonese sentences, and 2. A large-scale comparison across different model architectures, tokenization schemes, and embedding structures. Our best model trained with character-based tokenization and a Transformer architecture achieved a character-level BLEU of 25.1 when translating from Mandarin to Cantonese and of 24.4 when translating from Cantonese to Mandarin. In this paper we discuss our research process, experiments, and results.