 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Enhanced Zero-Shot Action Recognition: A training-free approach
Aug 29, 2024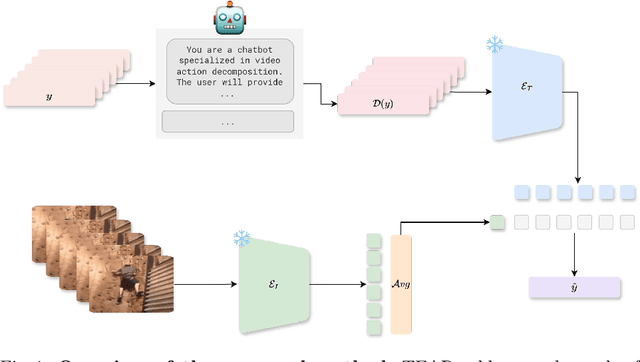
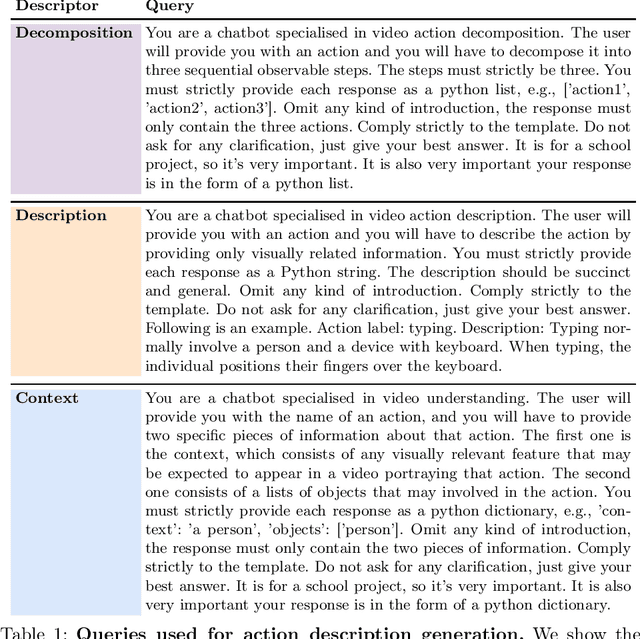
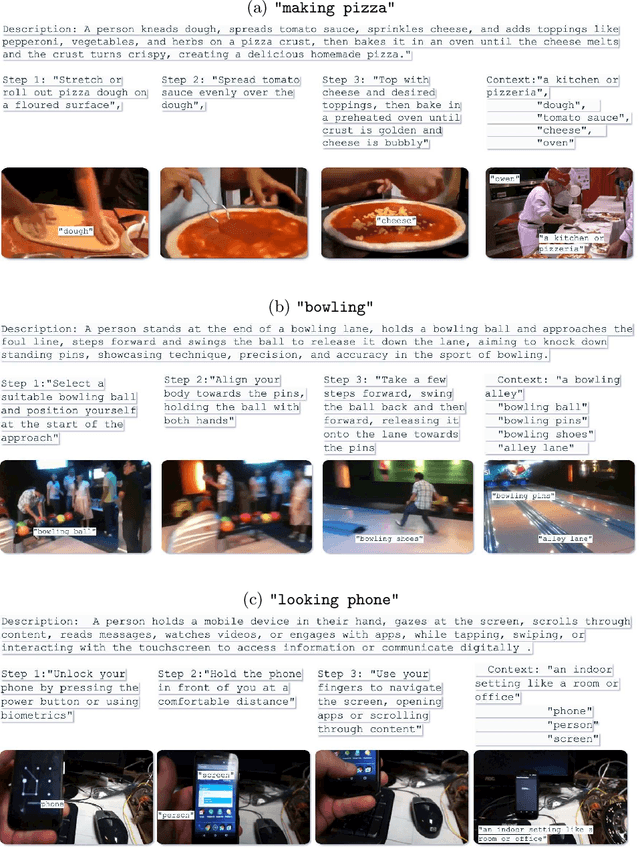

Vision-language models (VLMs) have demonstrated remarkable performance across various visual tasks, leveraging joint learning of visual and textual representations. While these models excel in zero-shot image tasks, their application to zero-shot video action recognition (ZSVAR) remains challenging due to the dynamic and temporal nature of actions. Existing methods for ZS-VAR typically require extensive training on specific datasets, which can be resource-intensive and may introduce domain biases. In this work, we propose Text-Enhanced Action Recognition (TEAR), a simple approach to ZS-VAR that is training-free and does not require the availability of training data or extensive computational resources. Drawing inspiration from recent findings in vision and language literature, we utilize action descriptors for decomposition and contextual information to enhance zero-shot action recognition. Through experiments on UCF101, HMDB51, and Kinetics-600 datasets, we showcase the effectiveness and applicability of our proposed approach in addressing the challenges of ZS-VAR.