 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Video Transformers in Action Recognition
Paper and Code

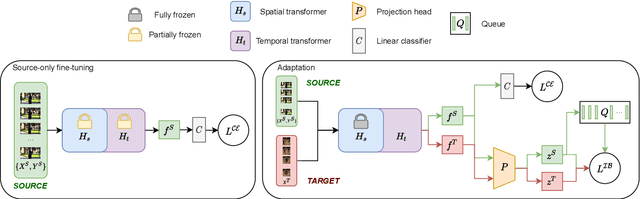
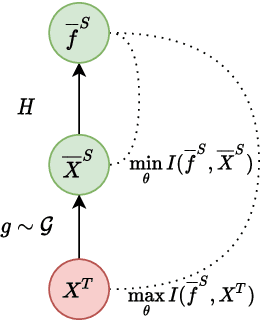
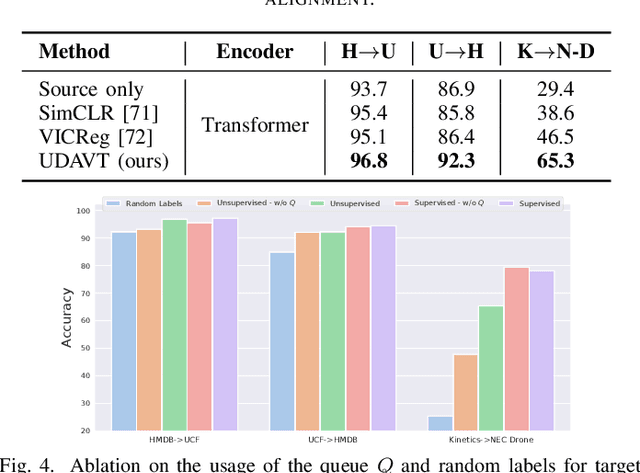
Over the last few years, Unsupervised Domain Adaptation (UDA) techniques have acquired remarkable importance and popularity in computer vision. However, when compared to the extensive literature available for images, the field of videos is still relatively unexplored. On the other hand, the performance of a model in action recognition is heavily affected by domain shift. In this paper, we propose a simple and novel UDA approach for video action recognition. Our approach leverages recent advances on spatio-temporal transformers to build a robust source model that better generalises to the target domain. Furthermore, our architecture learns domain invariant features thanks to the introduction of a novel alignment loss term derived from the Information Bottleneck principle. We report results on two video action recognition benchmarks for UDA, showing state-of-the-art performance on HMDB$\leftrightarrow$UCF, as well as on Kinetics$\rightarrow$NEC-Drone, which is more challenging. This demonstrates the effectiveness of our method in handling different levels of domain shift. The source code is available at https://github.com/vturrisi/UDAVT.