 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Surprising Situations in Event Data
Aug 29, 2022
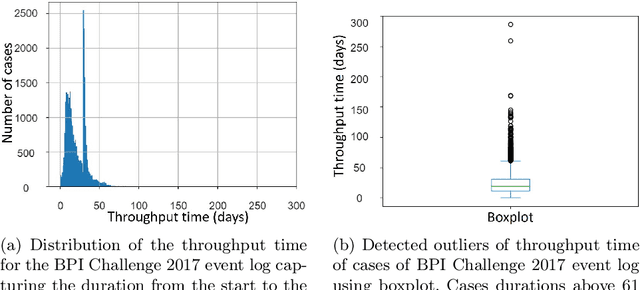
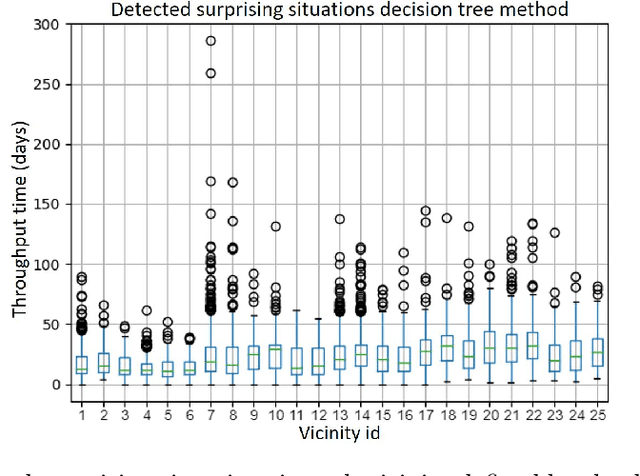
Process mining is a set of techniques that are used by organizations to understand and improve their operational processes. The first essential step in designing any process reengineering procedure is to find process improvement opportunities. In existing work, it is usually assumed that the set of problematic process instances in which an undesirable outcome occurs is known prior or is easily detectable. So the process enhancement procedure involves finding the root causes and the treatments for the problem in those process instances. For example, the set of problematic instances is considered as those with outlier values or with values smaller/bigger than a given threshold in one of the process features. However, on various occasions, using this approach, many process enhancement opportunities, not captured by these problematic process instances, are missed. To overcome this issue, we formulate finding the process enhancement areas as a context-sensitive anomaly/outlier detection problem. We define a process enhancement area as a set of situations (process instances or prefixes of process instances) where the process performance is surprising. We aim to characterize those situations where process performance/outcome is significantly different from what was expected considering its performance/outcome in similar situations. To evaluate the validity and relevance of the proposed approach, we have implemented and evaluated it on several real-life event logs.
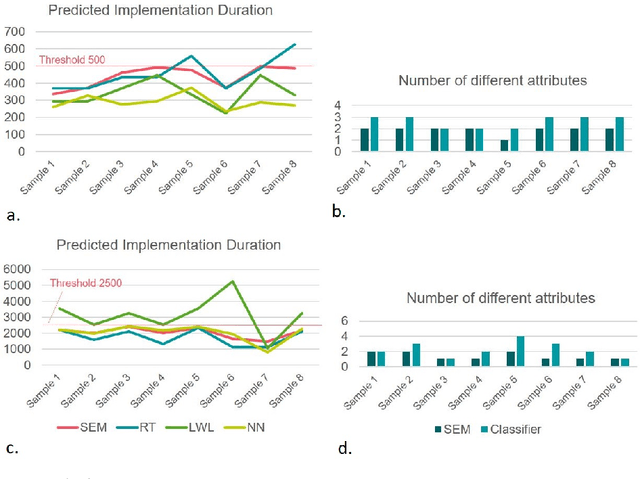
Feature Recommendation for Structural Equation Model Discovery in Process Mining
Aug 13, 2021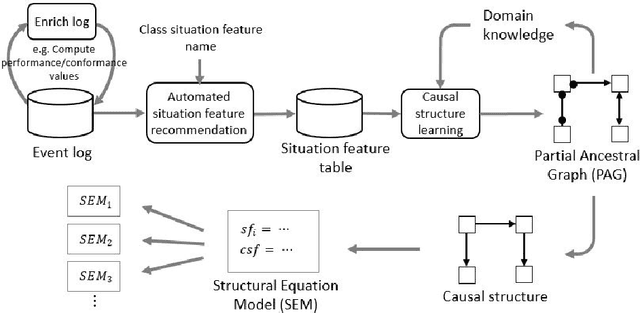
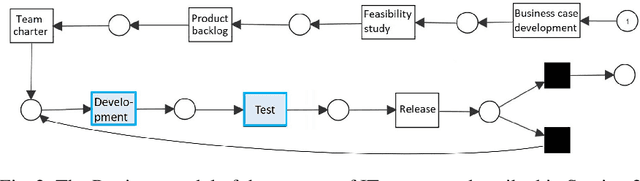
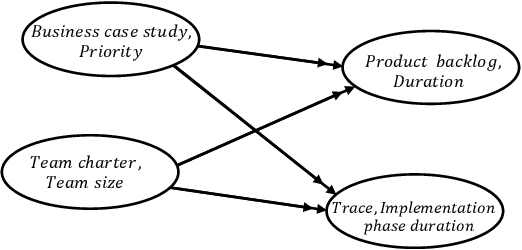
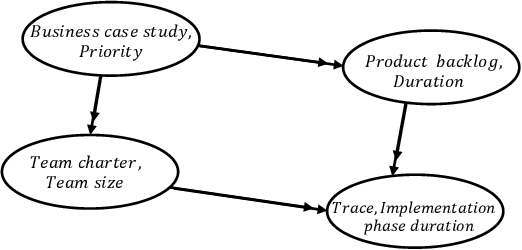
Process mining techniques can help organizations to improve their operational processes. Organizations can benefit from process mining techniques in finding and amending the root causes of performance or compliance problems. Considering the volume of the data and the number of features captured by the information system of today's companies, the task of discovering the set of features that should be considered in root cause analysis can be quite involving. In this paper, we propose a method for finding the set of (aggregated) features with a possible effect on the problem. The root cause analysis task is usually done by applying a machine learning technique to the data gathered from the information system supporting the processes. To prevent mixing up correlation and causation, which may happen because of interpreting the findings of machine learning techniques as causal, we propose a method for discovering the structural equation model of the process that can be used for root cause analysis. We have implemented the proposed method as a plugin in ProM and we have evaluated it using two real and synthetic event logs. These experiments show the validity and effectiveness of the proposed methods.
Case Level Counterfactual Reasoning in Process Mining
Feb 25, 2021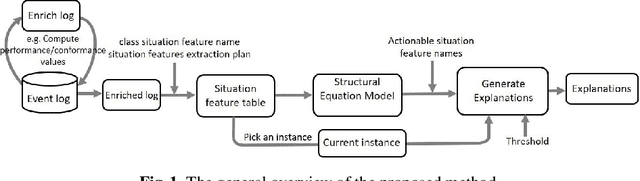

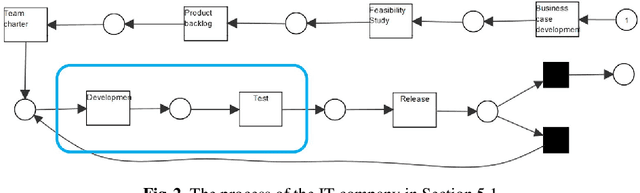
Process mining is widely used to diagnose processes and uncover performance and compliance problems. It is also possible to see relations between different behavioral aspects, e.g., cases that deviate more at the beginning of the process tend to get delayed in the last part of the process. However, correlations do not necessarily reveal causalities. Moreover, standard process mining diagnostics do not indicate how to improve the process. This is the reason we advocate the use of \emph{structural equation models} and \emph{counterfactual reasoning}. We use results from causal inference and adapt these to be able to reason over event logs and process interventions. We have implemented the approach as a ProM plug-in and have evaluated it on several data sets. Our ProM plug-in produces recommendations that indicate how specific cases could have been handled differently to avoid a performance or compliance problem.
Fairness-Aware Process Mining
Aug 28, 2019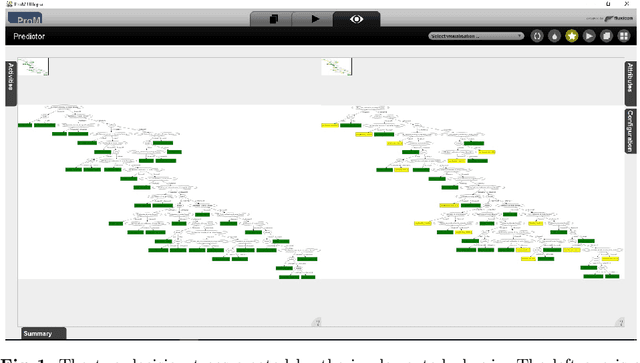
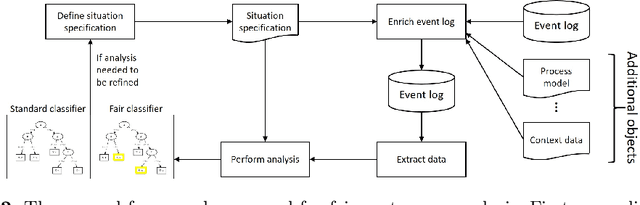
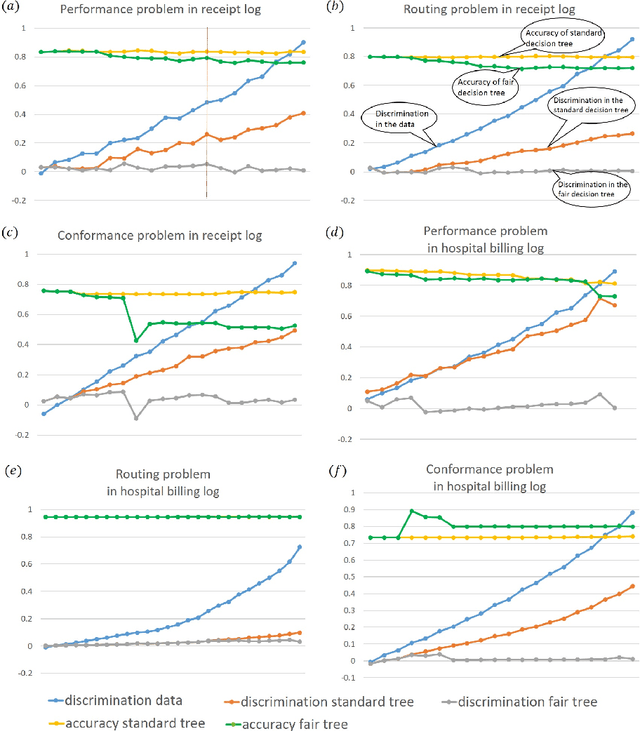
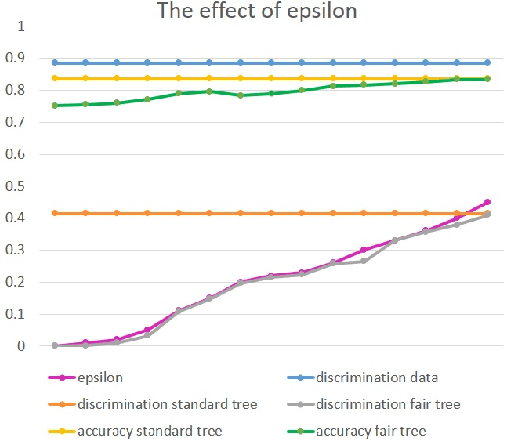
Process mining is a multi-purpose tool enabling organizations to improve their processes. One of the primary purposes of process mining is finding the root causes of performance or compliance problems in processes. The usual way of doing so is by gathering data from the process event log and other sources and then applying some data mining and machine learning techniques. However, the results of applying such techniques are not always acceptable. In many situations, this approach is prone to making obvious or unfair diagnoses and applying them may result in conclusions that are unsurprising or even discriminating (e.g., blaming overloaded employees for delays). In this paper, we present a solution to this problem by creating a fair classifier for such situations. The undesired effects are removed at the expense of reduction on the accuracy of the resulting classifier. We have implemented this method as a plug-in in ProM. Using the implemented plug-in on two real event logs, we decreased the discrimination caused by the classifier, while losing a small fraction of its accuracy.