 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRig3DGS: Creating Controllable Portraits from Casual Monocular Videos
Paper and Code
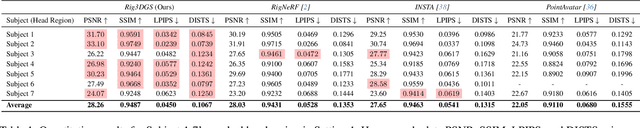
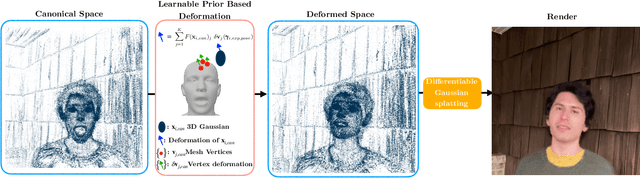
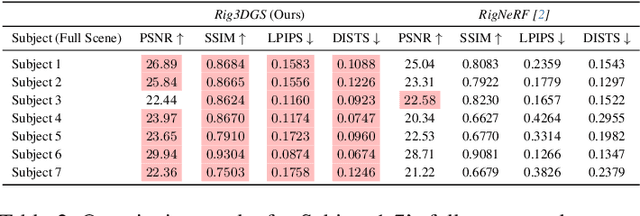

Creating controllable 3D human portraits from casual smartphone videos is highly desirable due to their immense value in AR/VR applications. The recent development of 3D Gaussian Splatting (3DGS) has shown improvements in rendering quality and training efficiency. However, it still remains a challenge to accurately model and disentangle head movements and facial expressions from a single-view capture to achieve high-quality renderings. In this paper, we introduce Rig3DGS to address this challenge. We represent the entire scene, including the dynamic subject, using a set of 3D Gaussians in a canonical space. Using a set of control signals, such as head pose and expressions, we transform them to the 3D space with learned deformations to generate the desired rendering. Our key innovation is a carefully designed deformation method which is guided by a learnable prior derived from a 3D morphable model. This approach is highly efficient in training and effective in controlling facial expressions, head positions, and view synthesis across various captures. We demonstrate the effectiveness of our learned deformation through extensive quantitative and qualitative experiments. The project page can be found at http://shahrukhathar.github.io/2024/02/05/Rig3DGS.html