 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelighting from a Single Image: Datasets and Deep Intrinsic-based Architecture
Sep 27, 2024Single image scene relighting aims to generate a realistic new version of an input image so that it appears to be illuminated by a new target light condition. Although existing works have explored this problem from various perspectives, generating relit images under arbitrary light conditions remains highly challenging, and related datasets are scarce. Our work addresses this problem from both the dataset and methodological perspectives. We propose two new datasets: a synthetic dataset with the ground truth of intrinsic components and a real dataset collected under laboratory conditions. These datasets alleviate the scarcity of existing datasets. To incorporate physical consistency in the relighting pipeline, we establish a two-stage network based on intrinsic decomposition, giving outputs at intermediate steps, thereby introducing physical constraints. When the training set lacks ground truth for intrinsic decomposition, we introduce an unsupervised module to ensure that the intrinsic outputs are satisfactory. Our method outperforms the state-of-the-art methods in performance, as tested on both existing datasets and our newly developed datasets. Furthermore, pretraining our method or other prior methods using our synthetic dataset can enhance their performance on other datasets. Since our method can accommodate any light conditions, it is capable of producing animated results. The dataset, method, and videos are publicly available.
Intrinsic Decomposition of Document Images In-the-Wild
Nov 29, 2020
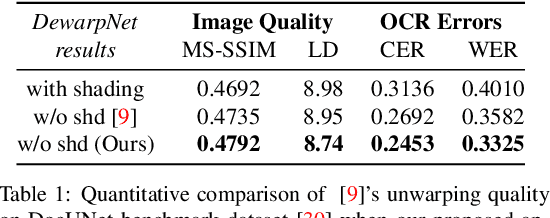

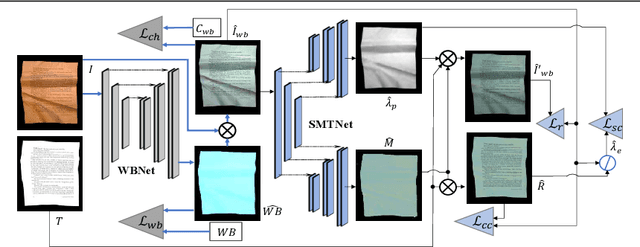
Automatic document content processing is affected by artifacts caused by the shape of the paper, non-uniform and diverse color of lighting conditions. Fully-supervised methods on real data are impossible due to the large amount of data needed. Hence, the current state of the art deep learning models are trained on fully or partially synthetic images. However, document shadow or shading removal results still suffer because: (a) prior methods rely on uniformity of local color statistics, which limit their application on real-scenarios with complex document shapes and textures and; (b) synthetic or hybrid datasets with non-realistic, simulated lighting conditions are used to train the models. In this paper we tackle these problems with our two main contributions. First, a physically constrained learning-based method that directly estimates document reflectance based on intrinsic image formation which generalizes to challenging illumination conditions. Second, a new dataset that clearly improves previous synthetic ones, by adding a large range of realistic shading and diverse multi-illuminant conditions, uniquely customized to deal with documents in-the-wild. The proposed architecture works in a self-supervised manner where only the synthetic texture is used as a weak training signal (obviating the need for very costly ground truth with disentangled versions of shading and reflectance). The proposed approach leads to a significant generalization of document reflectance estimation in real scenes with challenging illumination. We extensively evaluate on the real benchmark datasets available for intrinsic image decomposition and document shadow removal tasks. Our reflectance estimation scheme, when used as a pre-processing step of an OCR pipeline, shows a 26% improvement of character error rate (CER), thus, proving the practical applicability.