 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeed-cec: improving rare word recognition using asr postprocessing based on error detection and context-aware error correction
Oct 08, 2023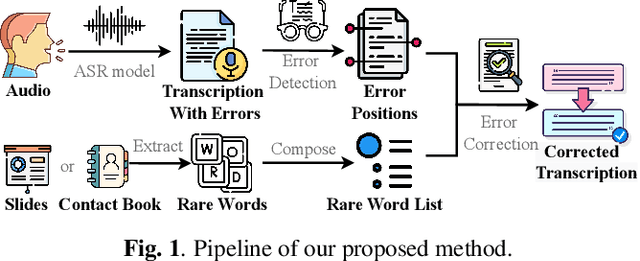
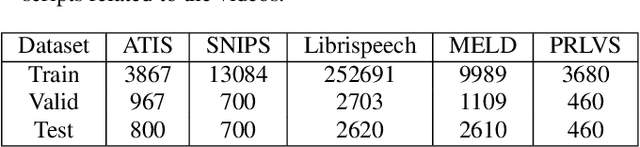
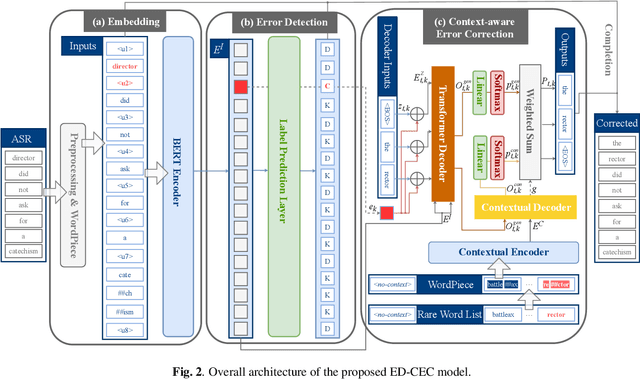
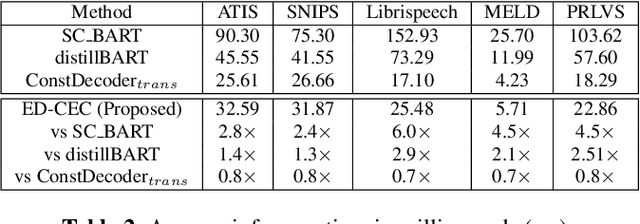
Automatic speech recognition (ASR) systems often encounter difficulties in accurately recognizing rare words, leading to errors that can have a negative impact on downstream tasks such as keyword spotting, intent detection, and text summarization. To address this challenge, we present a novel ASR postprocessing method that focuses on improving the recognition of rare words through error detection and context-aware error correction. Our method optimizes the decoding process by targeting only the predicted error positions, minimizing unnecessary computations. Moreover, we leverage a rare word list to provide additional contextual knowledge, enabling the model to better correct rare words. Experimental results across five datasets demonstrate that our proposed method achieves significantly lower word error rates (WERs) than previous approaches while maintaining a reasonable inference speed. Furthermore, our approach exhibits promising robustness across different ASR systems.
A 65nm 8b-Activation 8b-Weight SRAM-Based Charge-Domain Computing-in-Memory Macro Using A Fully-Parallel Analog Adder Network and A Single-ADC Interface
Nov 23, 2022



Performing data-intensive tasks in the von Neumann architecture is challenging to achieve both high performance and power efficiency due to the memory wall bottleneck. Computing-in-memory (CiM) is a promising mitigation approach by enabling parallel in-situ multiply-accumulate (MAC) operations within the memory with support from the peripheral interface and datapath. SRAM-based charge-domain CiM (CD-CiM) has shown its potential of enhanced power efficiency and computing accuracy. However, existing SRAM-based CD-CiM faces scaling challenges to meet the throughput requirement of high-performance multi-bit-quantization applications. This paper presents an SRAM-based high-throughput ReLU-optimized CD-CiM macro. It is capable of completing MAC and ReLU of two signed 8b vectors in one CiM cycle with only one A/D conversion. Along with non-linearity compensation for the analog computing and A/D conversion interfaces, this work achieves 51.2GOPS throughput and 10.3TOPS/W energy efficiency, while showing 88.6% accuracy in the CIFAR-10 dataset.
A Causal Inference Method for Reducing Gender Bias in Word Embedding Relations
Nov 25, 2019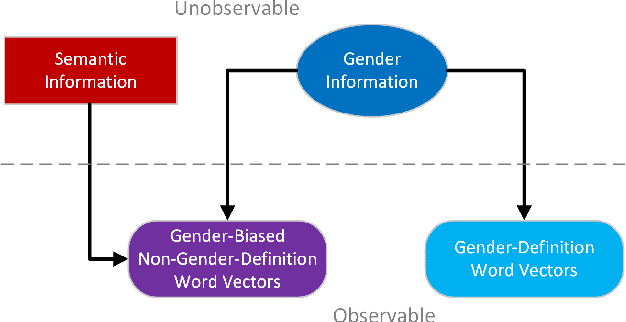
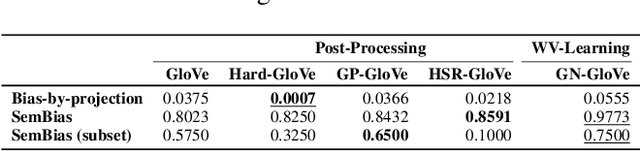
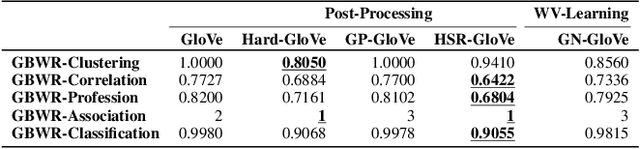
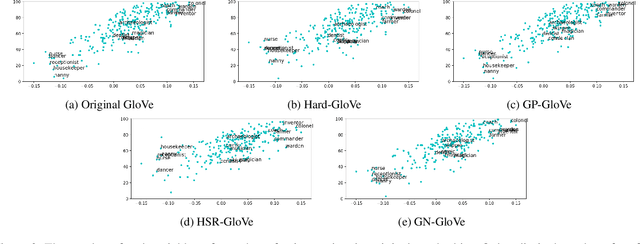
Word embedding has become essential for natural language processing as it boosts empirical performances of various tasks. However, recent research discovers that gender bias is incorporated in neural word embeddings, and downstream tasks that rely on these biased word vectors also produce gender-biased results. While some word-embedding gender-debiasing methods have been developed, these methods mainly focus on reducing gender bias associated with gender direction and fail to reduce the gender bias presented in word embedding relations. In this paper, we design a causal and simple approach for mitigating gender bias in word vector relation by utilizing the statistical dependency between gender-definition word embeddings and gender-biased word embeddings. Our method attains state-of-the-art results on gender-debiasing tasks, lexical- and sentence-level evaluation tasks, and downstream coreference resolution tasks.
Causally Denoise Word Embeddings Using Half-Sibling Regression
Nov 24, 2019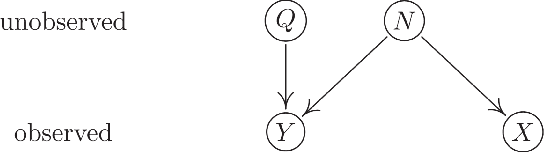


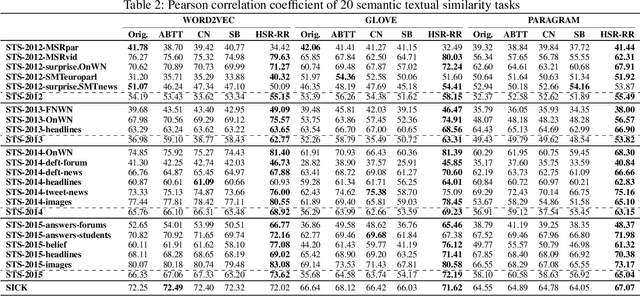
Distributional representations of words, also known as word vectors, have become crucial for modern natural language processing tasks due to their wide applications. Recently, a growing body of word vector postprocessing algorithm has emerged, aiming to render off-the-shelf word vectors even stronger. In line with these investigations, we introduce a novel word vector postprocessing scheme under a causal inference framework. Concretely, the postprocessing pipeline is realized by Half-Sibling Regression (HSR), which allows us to identify and remove confounding noise contained in word vectors. Compared to previous work, our proposed method has the advantages of interpretability and transparency due to its causal inference grounding. Evaluated on a battery of standard lexical-level evaluation tasks and downstream sentiment analysis tasks, our method reaches state-of-the-art performance.