 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-head Sequence Tagging Model for Grammatical Error Correction
Paper and Code

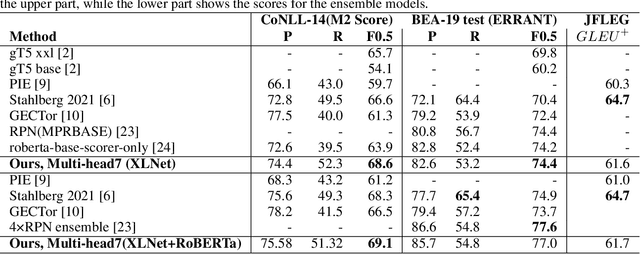
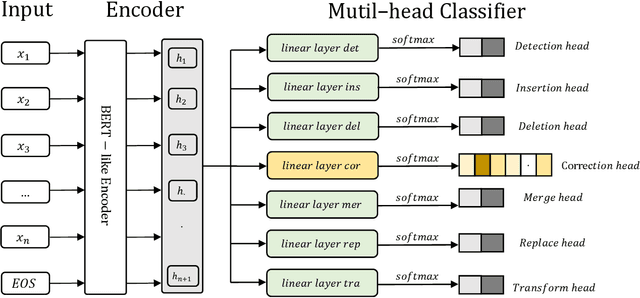

To solve the Grammatical Error Correction (GEC) problem , a mapping between a source sequence and a target one is needed, where the two differ only on few spans. For this reason, the attention has been shifted to the non-autoregressive or sequence tagging models. In which, the GEC has been simplified from Seq2Seq to labeling the input tokens with edit commands chosen from a large edit space. Due to this large number of classes and the limitation of the available datasets, the current sequence tagging approaches still have some issues handling a broad range of grammatical errors just by being laser-focused on one single task. To this end, we simplified the GEC further by dividing it into seven related subtasks: Insertion, Deletion, Merge, Substitution, Transformation, Detection, and Correction, with Correction being our primary focus. A distinct classification head is dedicated to each of these subtasks. the novel multi-head and multi-task learning model is proposed to effectively utilize training data and harness the information from related task training signals. To mitigate the limited number of available training samples, a new denoising autoencoder is used to generate a new synthetic dataset to be used for pretraining. Additionally, a new character-level transformation is proposed to enhance the sequence-to-edit function and improve the model's vocabulary coverage. Our single/ensemble model achieves an F0.5 of 74.4/77.0, and 68.6/69.1 on BEA-19 (test) and CoNLL-14 (test) respectively. Moreover, evaluated on JFLEG test set, the GLEU scores are 61.6 and 61.7 for the single and ensemble models, respectively. It mostly outperforms recently published state-of-the-art results by a considerable margin.