 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Structured Self-Attentive Model for Extractive Document Summarization (HSSAS)
May 20, 2018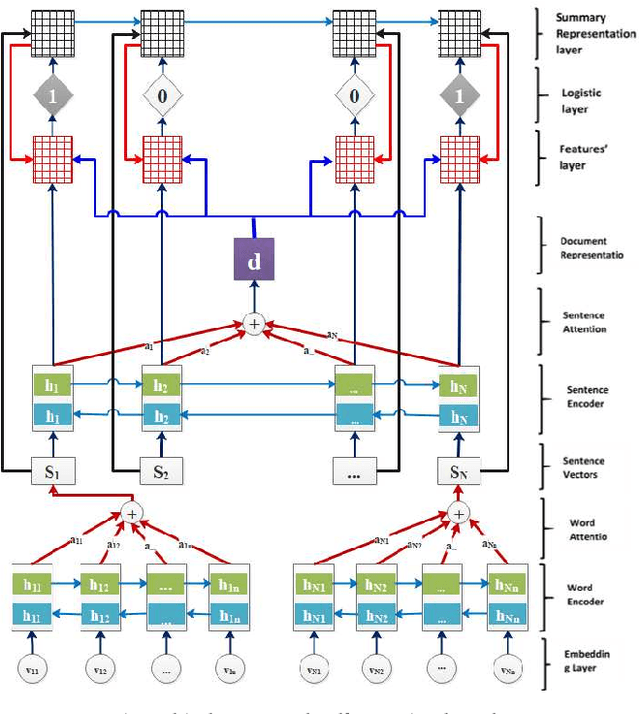
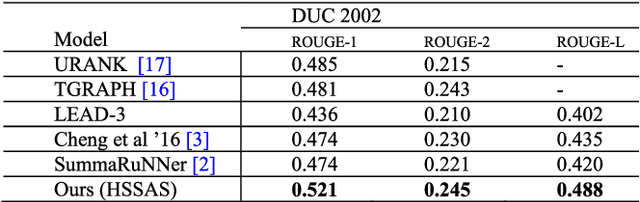
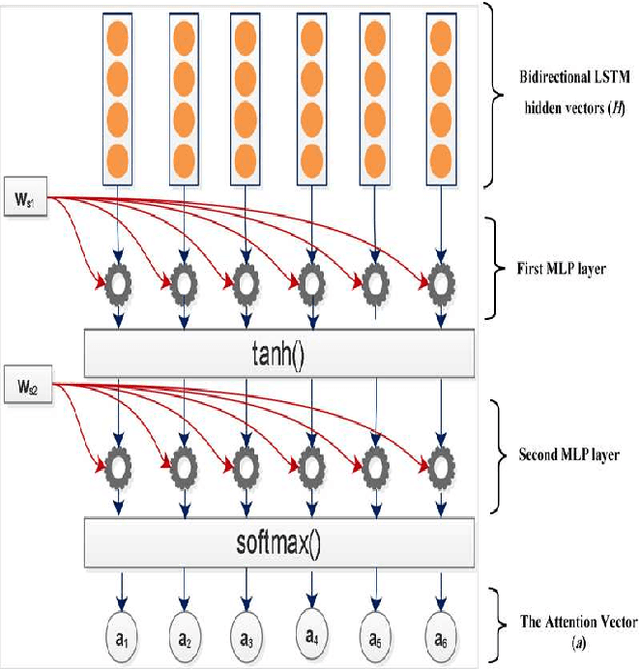
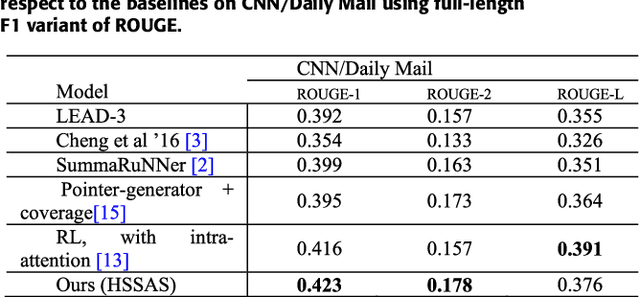
The recent advance in neural network architecture and training algorithms have shown the effectiveness of representation learning. The neural network-based models generate better representation than the traditional ones. They have the ability to automatically learn the distributed representation for sentences and documents. To this end, we proposed a novel model that addresses several issues that are not adequately modeled by the previously proposed models, such as the memory problem and incorporating the knowledge of document structure. Our model uses a hierarchical structured self-attention mechanism to create the sentence and document embeddings. This architecture mirrors the hierarchical structure of the document and in turn enables us to obtain better feature representation. The attention mechanism provides extra source of information to guide the summary extraction. The new model treated the summarization task as a classification problem in which the model computes the respective probabilities of sentence-summary membership. The model predictions are broken up by several features such as information content, salience, novelty and positional representation. The proposed model was evaluated on two well-known datasets, the CNN / Daily Mail, and DUC 2002. The experimental results show that our model outperforms the current extractive state-of-the-art by a considerable margin.