 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enhanced Latent Semantic Analysis Approach for Arabic Document Summarization
Jul 31, 2018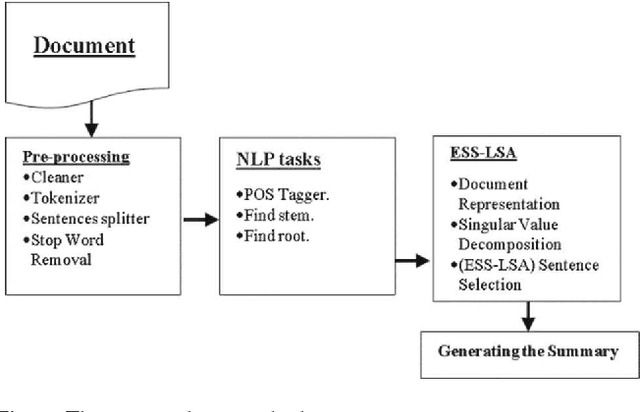
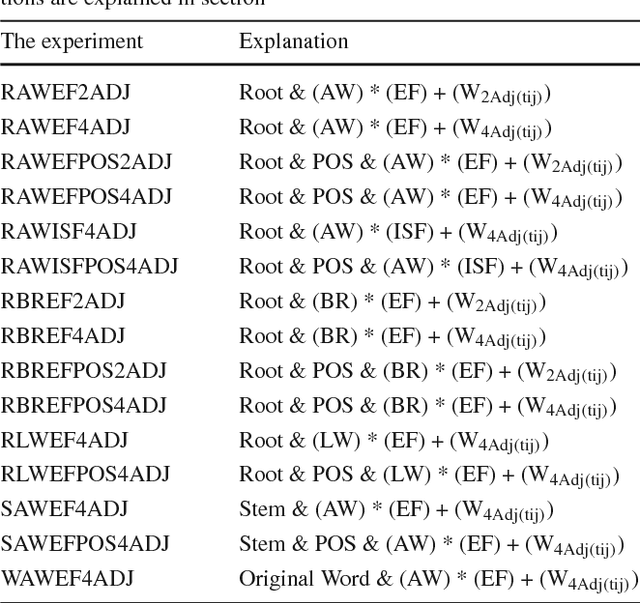

The fast-growing amount of information on the Internet makes the research in automatic document summarization very urgent. It is an effective solution for information overload. Many approaches have been proposed based on different strategies, such as latent semantic analysis (LSA). However, LSA, when applied to document summarization, has some limitations which diminish its performance. In this work, we try to overcome these limitations by applying statistic and linear algebraic approaches combined with syntactic and semantic processing of text. First, the part of speech tagger is utilized to reduce the dimension of LSA. Then, the weight of the term in four adjacent sentences is added to the weighting schemes while calculating the input matrix to take into account the word order and the syntactic relations. In addition, a new LSA-based sentence selection algorithm is proposed, in which the term description is combined with sentence description for each topic which in turn makes the generated summary more informative and diverse. To ensure the effectiveness of the proposed LSA-based sentence selection algorithm, extensive experiment on Arabic and English are done. Four datasets are used to evaluate the new model, Linguistic Data Consortium (LDC) Arabic Newswire-a corpus, Essex Arabic Summaries Corpus (EASC), DUC2002, and Multilingual MSS 2015 dataset. Experimental results on the four datasets show the effectiveness of the proposed model on Arabic and English datasets. It performs comprehensively better compared to the state-of-the-art methods.
* This is a pre-print of an article published in Arabian Journal for Science and Engineering. The final authenticated version is available online at: https://doi.org/10.1007/s13369-018-3286-z